 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review on Large Language Models for Visual Analytics
Mar 19, 2025



This paper provides a comprehensive review of the integration of Large Language Models (LLMs) with visual analytics, addressing their foundational concepts, capabilities, and wide-ranging applications. It begins by outlining the theoretical underpinnings of visual analytics and the transformative potential of LLMs, specifically focusing on their roles in natural language understanding, natural language generation, dialogue systems, and text-to-media transformations. The review further investigates how the synergy between LLMs and visual analytics enhances data interpretation, visualization techniques, and interactive exploration capabilities. Key tools and platforms including LIDA, Chat2VIS, Julius AI, and Zoho Analytics, along with specialized multimodal models such as ChartLlama and CharXIV, are critically evaluated. The paper discusses their functionalities, strengths, and limitations in supporting data exploration, visualization enhancement, automated reporting, and insight extraction. The taxonomy of LLM tasks, ranging from natural language understanding (NLU), natural language generation (NLG), to dialogue systems and text-to-media transformations, is systematically explored. This review provides a SWOT analysis of integrating Large Language Models (LLMs) with visual analytics, highlighting strengths like accessibility and flexibility, weaknesses such as computational demands and biases, opportunities in multimodal integration and user collaboration, and threats including privacy concerns and skill degradation. It emphasizes addressing ethical considerations and methodological improvements for effective integration.
Multimodal Data-Driven Classification of Mental Disorders: A Comprehensive Approach to Diagnosing Depression, Anxiety, and Schizophrenia
Feb 06, 2025



This study investigates the potential of multimodal data integration, which combines electroencephalogram (EEG) data with sociodemographic characteristics like age, sex, education, and intelligence quotient (IQ), to diagnose mental diseases like schizophrenia, depression, and anxiety. Using Apache Spark and convolutional neural networks (CNNs), a data-driven classification pipeline has been developed for big data environment to effectively analyze massive datasets. In order to evaluate brain activity and connection patterns associated with mental disorders, EEG parameters such as power spectral density (PSD) and coherence are examined. The importance of coherence features is highlighted by comparative analysis, which shows significant improvement in classification accuracy and robustness. This study emphasizes the significance of holistic approaches for efficient diagnostic tools by integrating a variety of data sources. The findings open the door for creative, data-driven approaches to treating psychiatric diseases by demonstrating the potential of utilizing big data, sophisticated deep learning methods, and multimodal datasets to enhance the precision, usability, and comprehension of mental health diagnostics.
Innovative Framework for Early Estimation of Mental Disorder Scores to Enable Timely Interventions
Feb 06, 2025



Individual's general well-being is greatly impacted by mental health conditions including depression and Post-Traumatic Stress Disorder (PTSD), underscoring the importance of early detection and precise diagnosis in order to facilitate prompt clinical intervention. An advanced multimodal deep learning system for the automated classification of PTSD and depression is presented in this paper. Utilizing textual and audio data from clinical interview datasets, the method combines features taken from both modalities by combining the architectures of LSTM (Long Short Term Memory) and BiLSTM (Bidirectional Long Short-Term Memory).Although text features focus on speech's semantic and grammatical components; audio features capture vocal traits including rhythm, tone, and pitch. This combination of modalities enhances the model's capacity to identify minute patterns connected to mental health conditions. Using test datasets, the proposed method achieves classification accuracies of 92% for depression and 93% for PTSD, outperforming traditional unimodal approaches and demonstrating its accuracy and robustness.
Anomaly detection in surveillance videos using transformer based attention model
Jun 06, 2022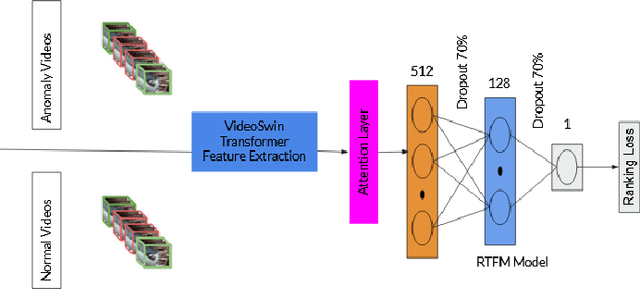
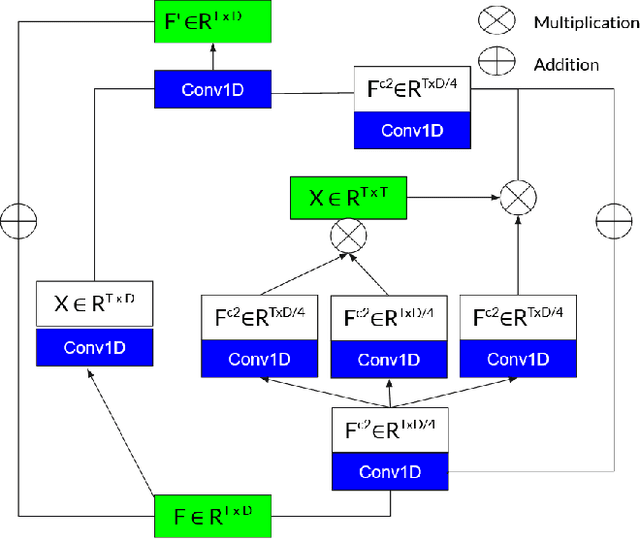

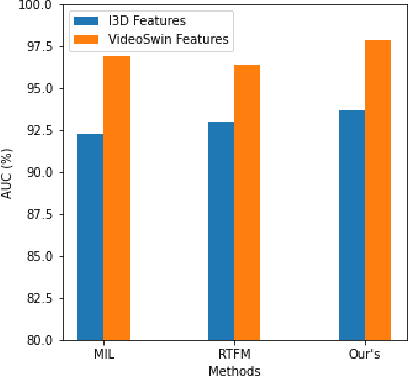
Surveillance footage can catch a wide range of realistic anomalies. This research suggests using a weakly supervised strategy to avoid annotating anomalous segments in training videos, which is time consuming. In this approach only video level labels are used to obtain frame level anomaly scores. Weakly supervised video anomaly detection (WSVAD) suffers from the wrong identification of abnormal and normal instances during the training process. Therefore it is important to extract better quality features from the available videos. WIth this motivation, the present paper uses better quality transformer-based features named Videoswin Features followed by the attention layer based on dilated convolution and self attention to capture long and short range dependencies in temporal domain. This gives us a better understanding of available videos. The proposed framework is validated on real-world dataset i.e. ShanghaiTech Campus dataset which results in competitive performance than current state-of-the-art methods. The model and the code are available at https://github.com/kapildeshpande/Anomaly-Detection-in-Surveillance-Videos
Impact of the composition of feature extraction and class sampling in medicare fraud detection
Jun 03, 2022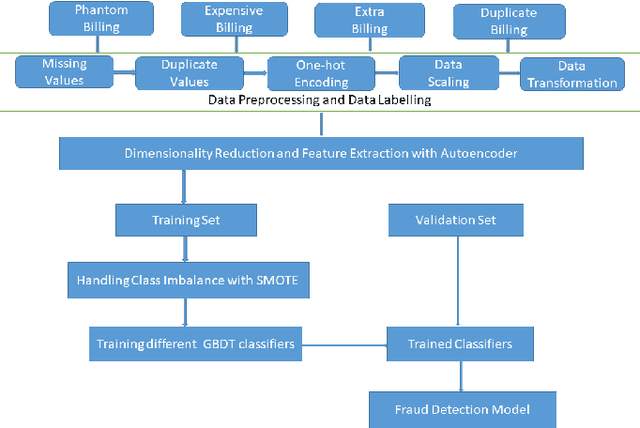
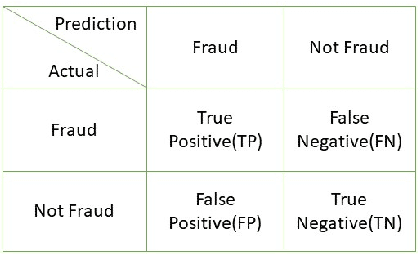
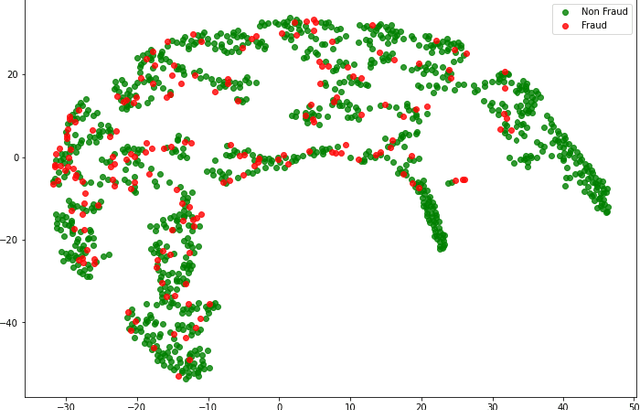
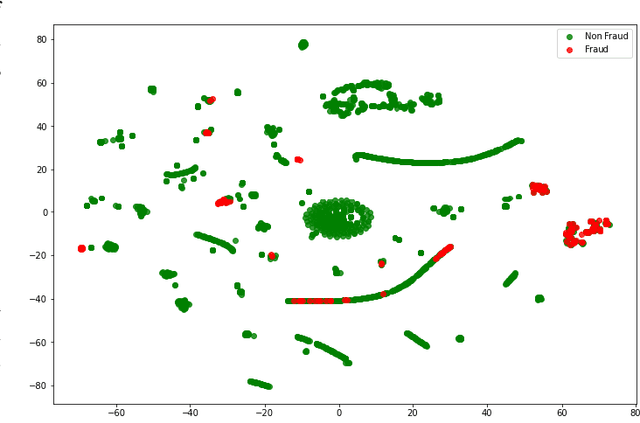
With healthcare being critical aspect, health insurance has become an important scheme in minimizing medical expenses. Following this, the healthcare industry has seen a significant increase in fraudulent activities owing to increased insurance, and fraud has become a significant contributor to rising medical care expenses, although its impact can be mitigated using fraud detection techniques. To detect fraud, machine learning techniques are used. The Centers for Medicaid and Medicare Services (CMS) of the United States federal government released "Medicare Part D" insurance claims is utilized in this study to develop fraud detection system. Employing machine learning algorithms on a class-imbalanced and high dimensional medicare dataset is a challenging task. To compact such challenges, the present work aims to perform feature extraction following data sampling, afterward applying various classification algorithms, to get better performance. Feature extraction is a dimensionality reduction approach that converts attributes into linear or non-linear combinations of the actual attributes, generating a smaller and more diversified set of attributes and thus reducing the dimensions. Data sampling is commonlya used to address the class imbalance either by expanding the frequency of minority class or reducing the frequency of majority class to obtain approximately equal numbers of occurrences for both classes. The proposed approach is evaluated through standard performance metrics. Thus, to detect fraud efficiently, this study applies autoencoder as a feature extraction technique, synthetic minority oversampling technique (SMOTE) as a data sampling technique, and various gradient boosted decision tree-based classifiers as a classification algorithm. The experimental results show the combination of autoencoders followed by SMOTE on the LightGBM classifier achieved best results.
Impact of Attention on Adversarial Robustness of Image Classification Models
Sep 02, 2021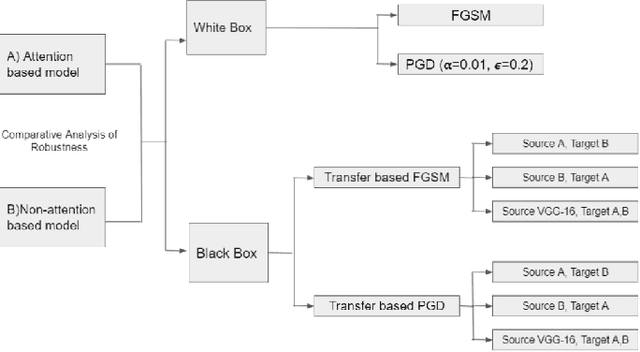
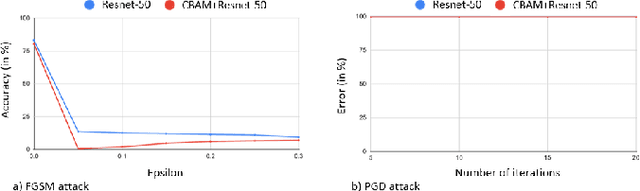
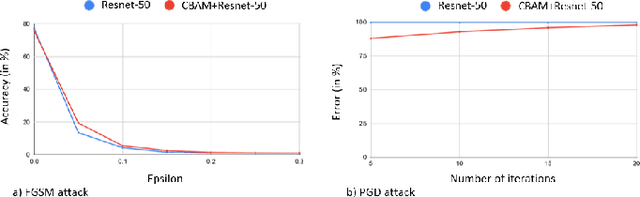
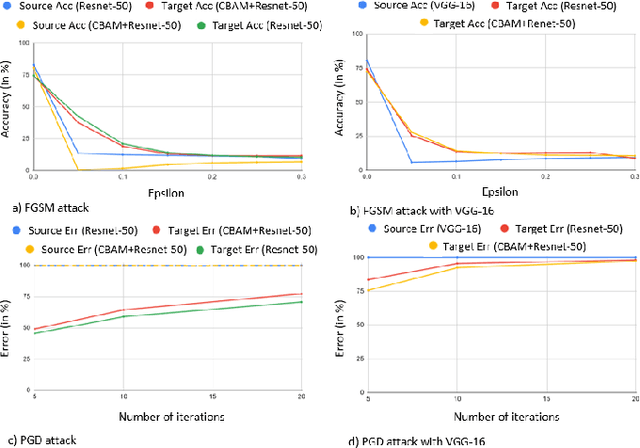
Adversarial attacks against deep learning models have gained significant attention and recent works have proposed explanations for the existence of adversarial examples and techniques to defend the models against these attacks. Attention in computer vision has been used to incorporate focused learning of important features and has led to improved accuracy. Recently, models with attention mechanisms have been proposed to enhance adversarial robustness. Following this context, this work aims at a general understanding of the impact of attention on adversarial robustness. This work presents a comparative study of adversarial robustness of non-attention and attention based image classification models trained on CIFAR-10, CIFAR-100 and Fashion MNIST datasets under the popular white box and black box attacks. The experimental results show that the robustness of attention based models may be dependent on the datasets used i.e. the number of classes involved in the classification. In contrast to the datasets with less number of classes, attention based models are observed to show better robustness towards classification.
White blood cell subtype detection and classification
Aug 10, 2021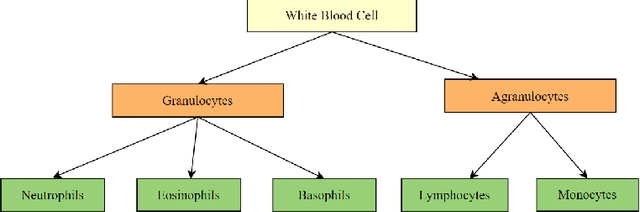
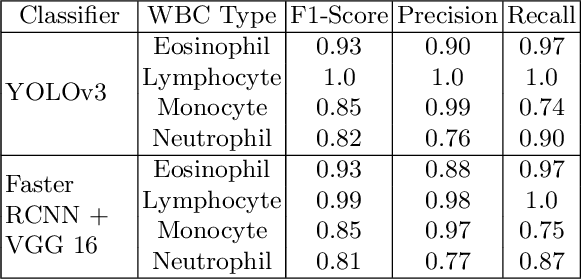
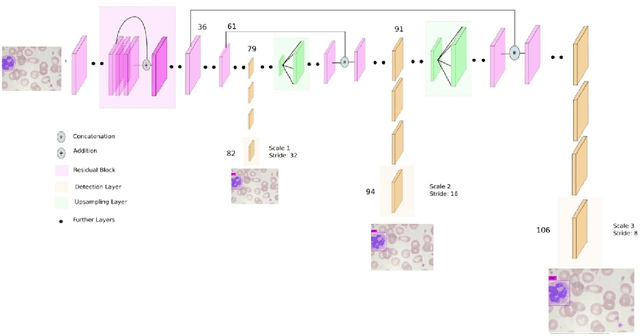
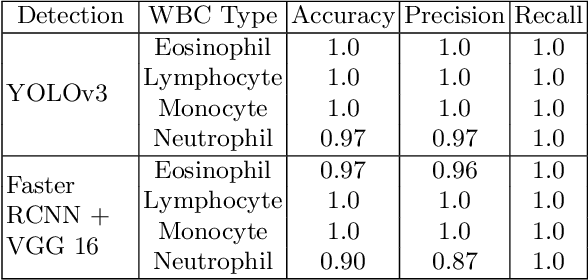
Machine learning has endless applications in the health care industry. White blood cell classification is one of the interesting and promising area of research. The classification of the white blood cells plays an important part in the medical diagnosis. In practise white blood cell classification is performed by the haematologist by taking a small smear of blood and careful examination under the microscope. The current procedures to identify the white blood cell subtype is more time taking and error-prone. The computer aided detection and diagnosis of the white blood cells tend to avoid the human error and reduce the time taken to classify the white blood cells. In the recent years several deep learning approaches have been developed in the context of classification of the white blood cells that are able to identify but are unable to localize the positions of white blood cells in the blood cell image. Following this, the present research proposes to utilize YOLOv3 object detection technique to localize and classify the white blood cells with bounding boxes. With exhaustive experimental analysis, the proposed work is found to detect the white blood cell with 99.2% accuracy and classify with 90% accuracy.
MAG-Net: Mutli-task attention guided network for brain tumor segmentation and classification
Jul 26, 2021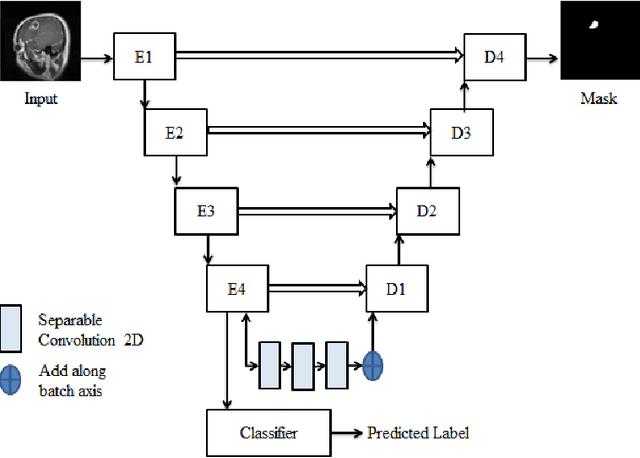
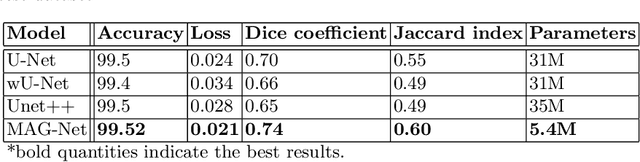

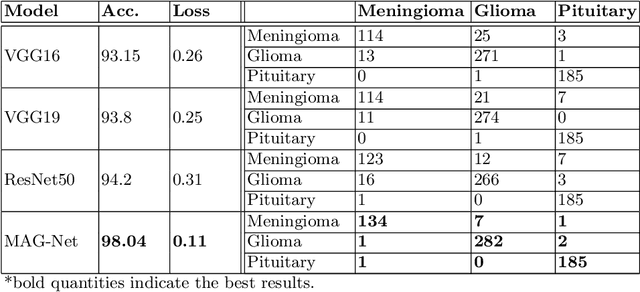
Brain tumor is the most common and deadliest disease that can be found in all age groups. Generally, MRI modality is adopted for identifying and diagnosing tumors by the radiologists. The correct identification of tumor regions and its type can aid to diagnose tumors with the followup treatment plans. However, for any radiologist analysing such scans is a complex and time-consuming task. Motivated by the deep learning based computer-aided-diagnosis systems, this paper proposes multi-task attention guided encoder-decoder network (MAG-Net) to classify and segment the brain tumor regions using MRI images. The MAG-Net is trained and evaluated on the Figshare dataset that includes coronal, axial, and sagittal views with 3 types of tumors meningioma, glioma, and pituitary tumor. With exhaustive experimental trials the model achieved promising results as compared to existing state-of-the-art models, while having least number of training parameters among other state-of-the-art models.
Recommending best course of treatment based on similarities of prognostic markers
Jul 19, 2021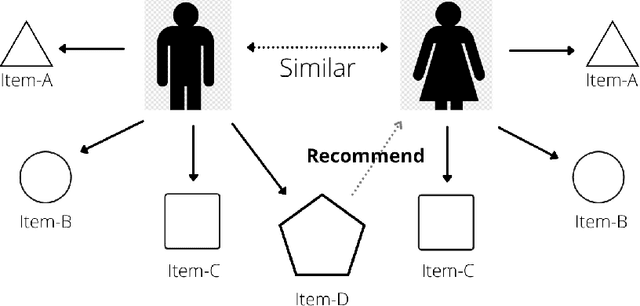
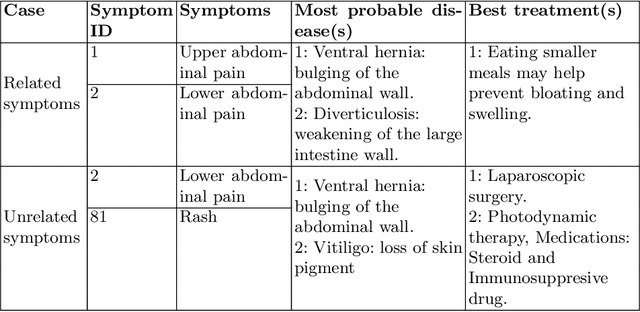

With the advancement in the technology sector spanning over every field, a huge influx of information is inevitable. Among all the opportunities that the advancements in the technology have brought, one of them is to propose efficient solutions for data retrieval. This means that from an enormous pile of data, the retrieval methods should allow the users to fetch the relevant and recent data over time. In the field of entertainment and e-commerce, recommender systems have been functioning to provide the aforementioned. Employing the same systems in the medical domain could definitely prove to be useful in variety of ways. Following this context, the goal of this paper is to propose collaborative filtering based recommender system in the healthcare sector to recommend remedies based on the symptoms experienced by the patients. Furthermore, a new dataset is developed consisting of remedies concerning various diseases to address the limited availability of the data. The proposed recommender system accepts the prognostic markers of a patient as the input and generates the best remedy course. With several experimental trials, the proposed model achieved promising results in recommending the possible remedy for given prognostic markers.
Hate speech detection using static BERT embeddings
Jun 29, 2021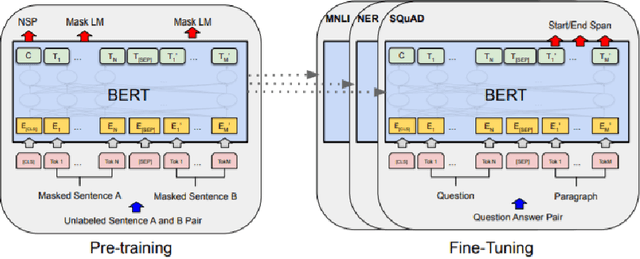
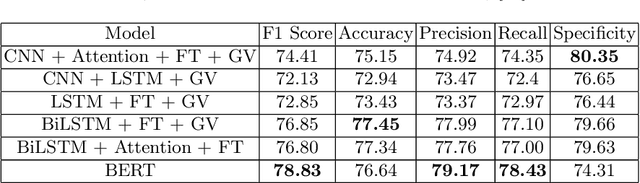
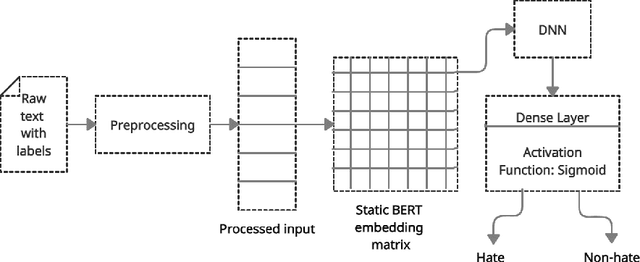
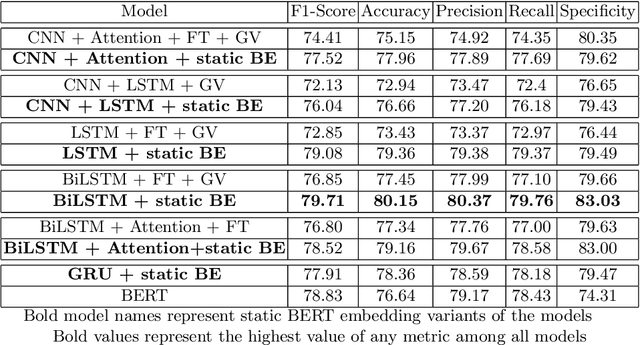
With increasing popularity of social media platforms hate speech is emerging as a major concern, where it expresses abusive speech that targets specific group characteristics, such as gender, religion or ethnicity to spread violence. Earlier people use to verbally deliver hate speeches but now with the expansion of technology, some people are deliberately using social media platforms to spread hate by posting, sharing, commenting, etc. Whether it is Christchurch mosque shootings or hate crimes against Asians in west, it has been observed that the convicts are very much influenced from hate text present online. Even though AI systems are in place to flag such text but one of the key challenges is to reduce the false positive rate (marking non hate as hate), so that these systems can detect hate speech without undermining the freedom of expression. In this paper, we use ETHOS hate speech detection dataset and analyze the performance of hate speech detection classifier by replacing or integrating the word embeddings (fastText (FT), GloVe (GV) or FT + GV) with static BERT embeddings (BE). With the extensive experimental trails it is observed that the neural network performed better with static BE compared to using FT, GV or FT + GV as word embeddings. In comparison to fine-tuned BERT, one metric that significantly improved is specificity.