 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Pigs Fly: Contextual Reasoning in Synthetic and Natural Scenes
Apr 06, 2021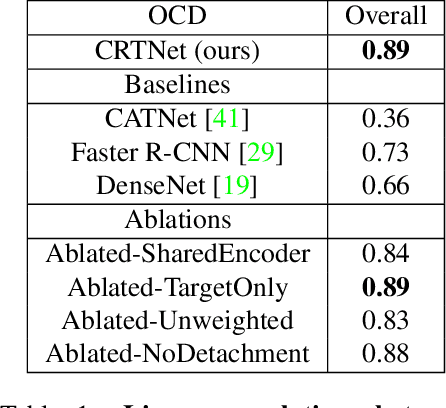
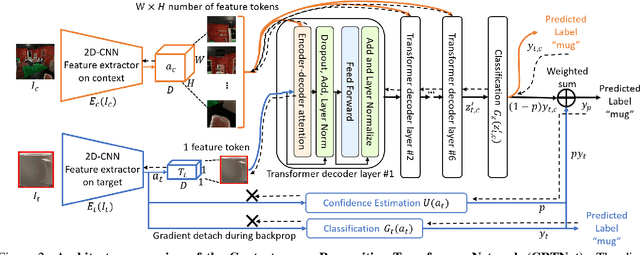
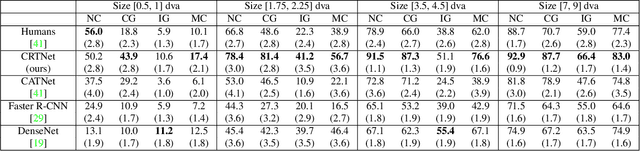
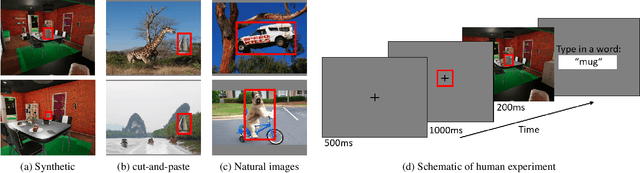
Context is of fundamental importance to both human and machine vision -- an object in the air is more likely to be an airplane, than a pig. The rich notion of context incorporates several aspects including physics rules, statistical co-occurrences, and relative object sizes, among others. While previous works have crowd-sourced out-of-context photographs from the web to study scene context, controlling the nature and extent of contextual violations has been an extremely daunting task. Here we introduce a diverse, synthetic Out-of-Context Dataset (OCD) with fine-grained control over scene context. By leveraging a 3D simulation engine, we systematically control the gravity, object co-occurrences and relative sizes across 36 object categories in a virtual household environment. We then conduct a series of experiments to gain insights into the impact of contextual cues on both human and machine vision using OCD. First, we conduct psycho-physics experiments to establish a human benchmark for out-of-context recognition, and then compare it with state-of-the-art computer vision models to quantify the gap between the two. Finally, we propose a context-aware recognition transformer model, fusing object and contextual information via multi-head attention. Our model captures useful information for contextual reasoning, enabling human-level performance and significantly better robustness in out-of-context conditions compared to baseline models across OCD and other existing out-of-context natural image datasets. All source code and data are publicly available https://github.com/kreimanlab/WhenPigsFlyContext.