 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features
Feb 20, 2025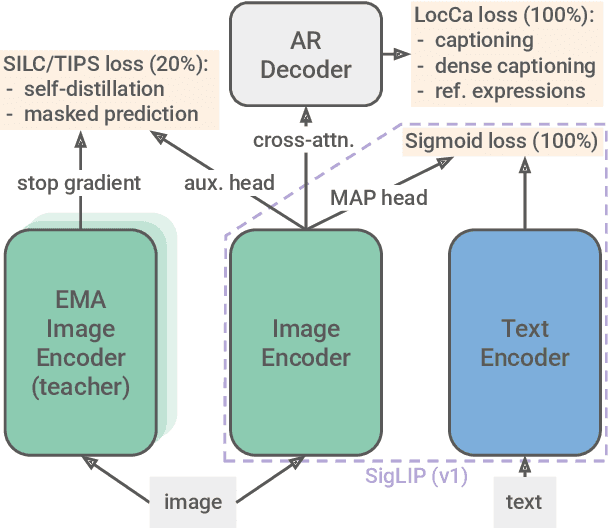
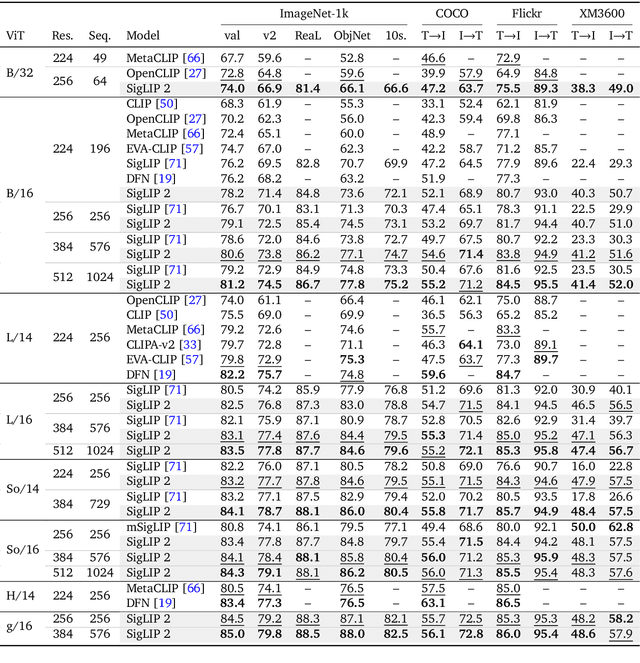
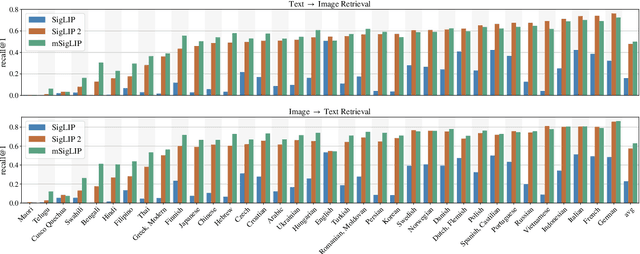
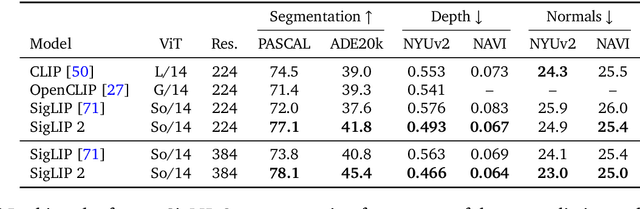
We introduce SigLIP 2, a family of new multilingual vision-language encoders that build on the success of the original SigLIP. In this second iteration, we extend the original image-text training objective with several prior, independently developed techniques into a unified recipe -- this includes captioning-based pretraining, self-supervised losses (self-distillation, masked prediction) and online data curation. With these changes, SigLIP 2 models outperform their SigLIP counterparts at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). Furthermore, the new training recipe leads to significant improvements on localization and dense prediction tasks. We also train variants which support multiple resolutions and preserve the input's native aspect ratio. Finally, we train on a more diverse data-mixture that includes de-biasing techniques, leading to much better multilingual understanding and improved fairness. To allow users to trade off inference cost with performance, we release model checkpoints at four sizes: ViT-B (86M), L (303M), So400m (400M), and g (1B).
A Practitioner's Guide to Continual Multimodal Pretraining
Aug 26, 2024Multimodal foundation models serve numerous applications at the intersection of vision and language. Still, despite being pretrained on extensive data, they become outdated over time. To keep models updated, research into continual pretraining mainly explores scenarios with either (1) infrequent, indiscriminate updates on large-scale new data, or (2) frequent, sample-level updates. However, practical model deployment often operates in the gap between these two limit cases, as real-world applications often demand adaptation to specific subdomains, tasks or concepts -- spread over the entire, varying life cycle of a model. In this work, we complement current perspectives on continual pretraining through a research test bed as well as provide comprehensive guidance for effective continual model updates in such scenarios. We first introduce FoMo-in-Flux, a continual multimodal pretraining benchmark with realistic compute constraints and practical deployment requirements, constructed over 63 datasets with diverse visual and semantic coverage. Using FoMo-in-Flux, we explore the complex landscape of practical continual pretraining through multiple perspectives: (1) A data-centric investigation of data mixtures and stream orderings that emulate real-world deployment situations, (2) a method-centric investigation ranging from simple fine-tuning and traditional continual learning strategies to parameter-efficient updates and model merging, (3) meta learning rate schedules and mechanistic design choices, and (4) the influence of model and compute scaling. Together, our insights provide a practitioner's guide to continual multimodal pretraining for real-world deployment. Our benchmark and code is here: https://github.com/ExplainableML/fomo_in_flux.
Fantastic Gains and Where to Find Them: On the Existence and Prospect of General Knowledge Transfer between Any Pretrained Model
Oct 26, 2023Training deep networks requires various design decisions regarding for instance their architecture, data augmentation, or optimization. In this work, we find these training variations to result in networks learning unique feature sets from the data. Using public model libraries comprising thousands of models trained on canonical datasets like ImageNet, we observe that for arbitrary pairings of pretrained models, one model extracts significant data context unavailable in the other -- independent of overall performance. Given any arbitrary pairing of pretrained models and no external rankings (such as separate test sets, e.g. due to data privacy), we investigate if it is possible to transfer such "complementary" knowledge from one model to another without performance degradation -- a task made particularly difficult as additional knowledge can be contained in stronger, equiperformant or weaker models. Yet facilitating robust transfer in scenarios agnostic to pretrained model pairings would unlock auxiliary gains and knowledge fusion from any model repository without restrictions on model and problem specifics - including from weaker, lower-performance models. This work therefore provides an initial, in-depth exploration on the viability of such general-purpose knowledge transfer. Across large-scale experiments, we first reveal the shortcomings of standard knowledge distillation techniques, and then propose a much more general extension through data partitioning for successful transfer between nearly all pretrained models, which we show can also be done unsupervised. Finally, we assess both the scalability and impact of fundamental model properties on successful model-agnostic knowledge transfer.
Where Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022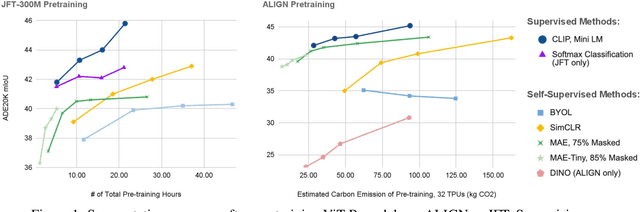
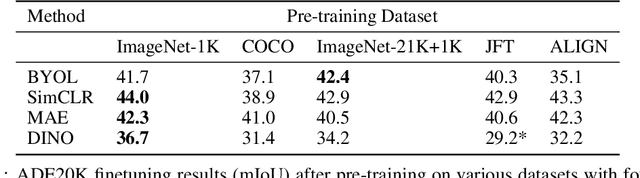
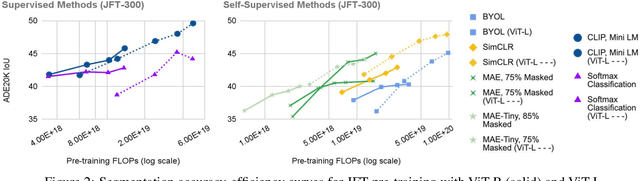
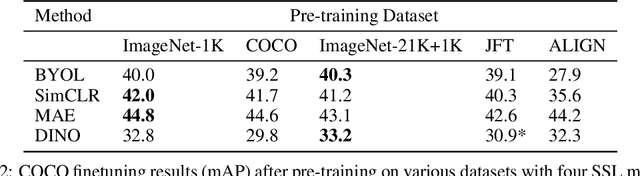
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021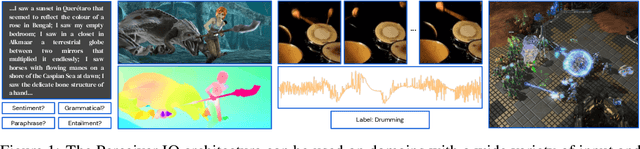
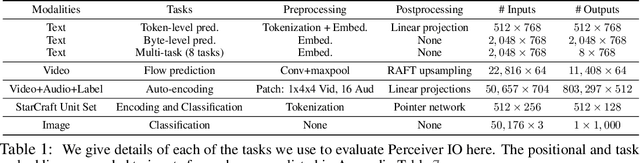
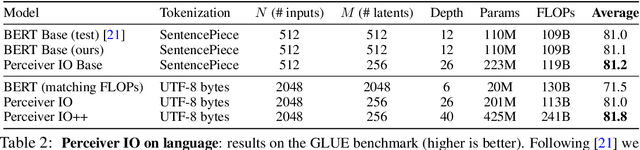
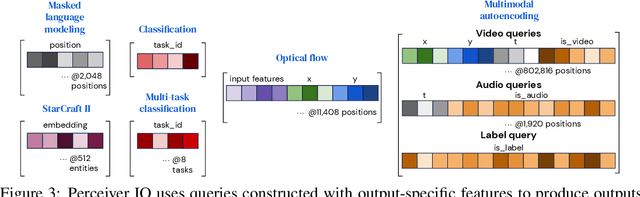
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.