 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Learned Indexes to Improve Time Series Indexing Performance on Embedded Sensor Devices
Feb 06, 2023


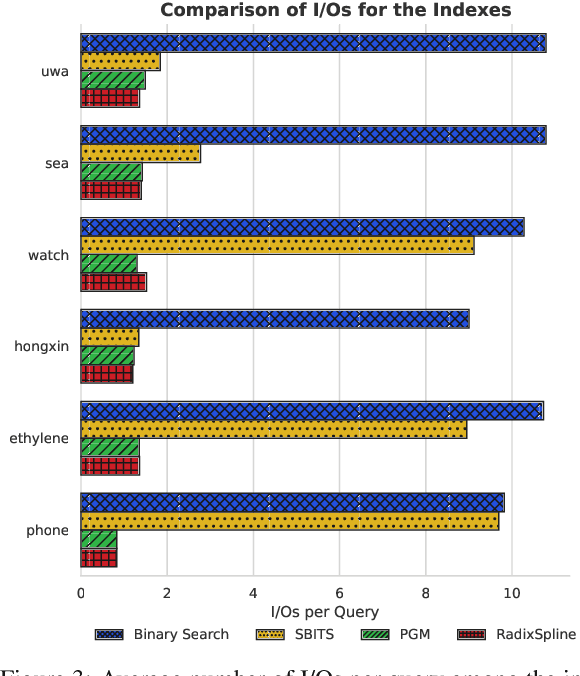
Efficiently querying data on embedded sensor and IoT devices is challenging given the very limited memory and CPU resources. With the increasing volumes of collected data, it is critical to process, filter, and manipulate data on the edge devices where it is collected to improve efficiency and reduce network transmissions. Existing embedded index structures do not adapt to the data distribution and characteristics. This paper demonstrates how applying learned indexes that develop space efficient summaries of the data can dramatically improve the query performance and predictability. Learned indexes based on linear approximations can reduce the query I/O by 50 to 90% and improve query throughput by a factor of 2 to 5, while only requiring a few kilobytes of RAM. Experimental results on a variety of time series data sets demonstrate the advantages of learned indexes that considerably improve over the state-of-the-art index algorithms.
Know your audience: specializing grounded language models with the game of Dixit
Jun 16, 2022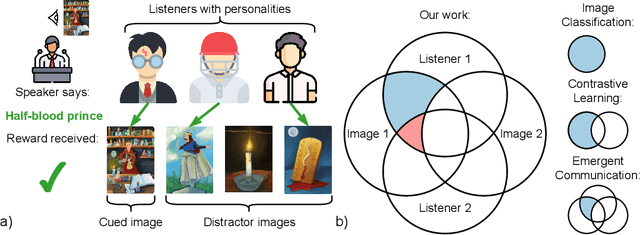
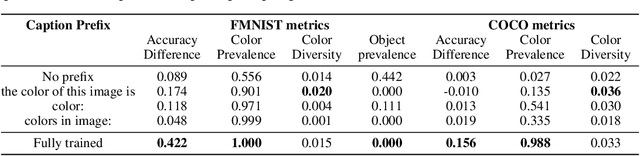
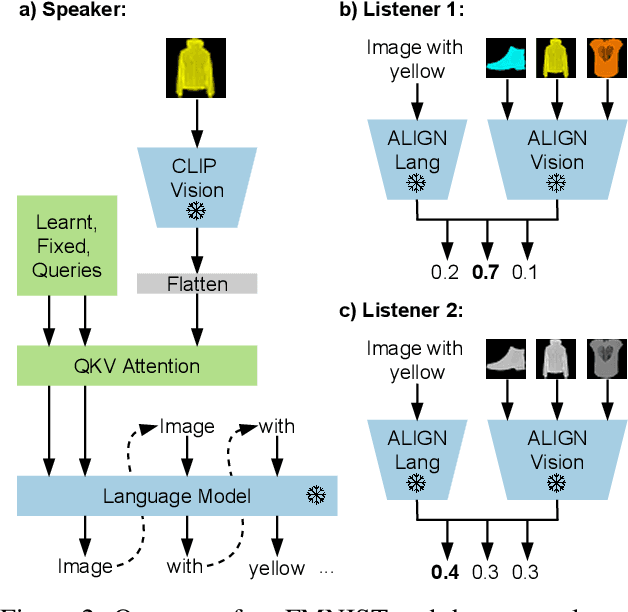
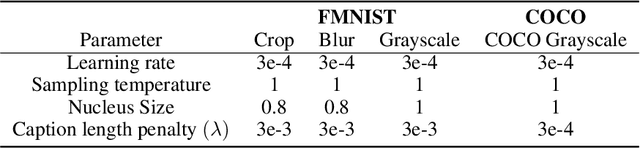
Effective communication requires adapting to the idiosyncratic common ground shared with each communicative partner. We study a particularly challenging instantiation of this problem: the popular game Dixit. We formulate a round of Dixit as a multi-agent image reference game where a (trained) speaker model is rewarded for describing a target image such that one (pretrained) listener model can correctly identify it from a pool of distractors, but another listener cannot. To adapt to this setting, the speaker must exploit differences in the common ground it shares with the different listeners. We show that finetuning an attention-based adapter between a CLIP vision encoder and a large language model in this contrastive, multi-agent setting gives rise to context-dependent natural language specialization from rewards only, without direct supervision. In a series of controlled experiments, we show that the speaker can adapt according to the idiosyncratic strengths and weaknesses of various pairs of different listeners. Furthermore, we show zero-shot transfer of the speaker's specialization to unseen real-world data. Our experiments offer a step towards adaptive communication in complex multi-partner settings and highlight the interesting research challenges posed by games like Dixit. We hope that our work will inspire creative new approaches to adapting pretrained models.
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021
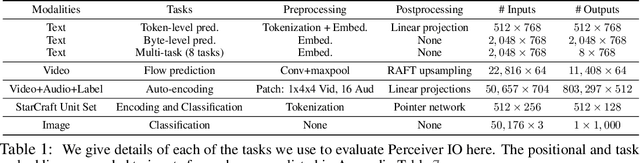
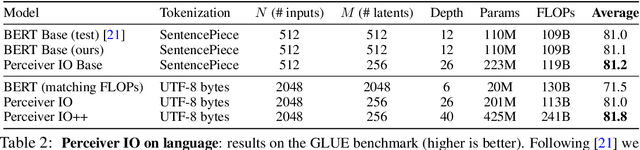
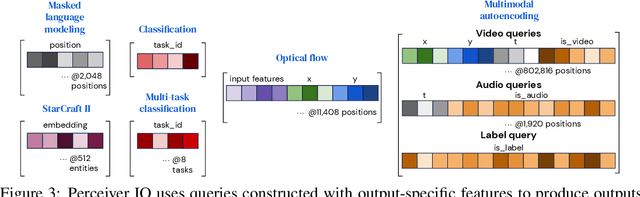
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
Object-based attention for spatio-temporal reasoning: Outperforming neuro-symbolic models with flexible distributed architectures
Dec 15, 2020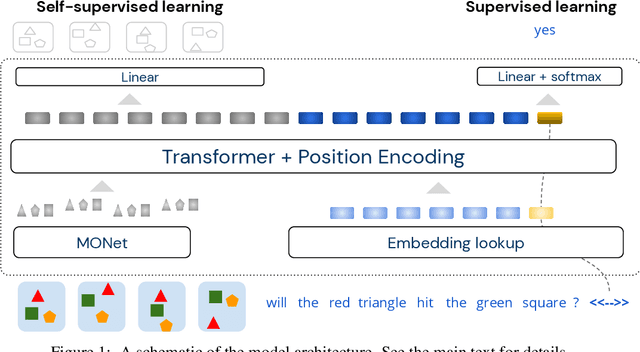
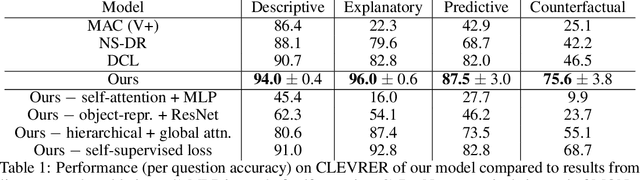
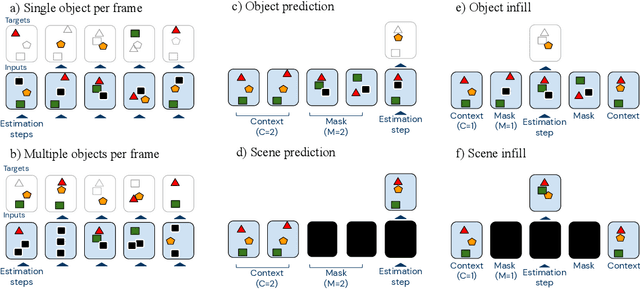
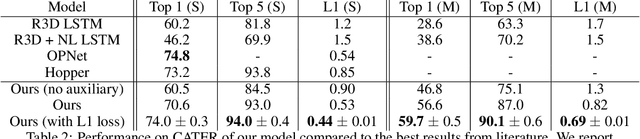
Neural networks have achieved success in a wide array of perceptual tasks, but it is often stated that they are incapable of solving tasks that require higher-level reasoning. Two new task domains, CLEVRER and CATER, have recently been developed to focus on reasoning, as opposed to perception, in the context of spatio-temporal interactions between objects. Initial experiments on these domains found that neuro-symbolic approaches, which couple a logic engine and language parser with a neural perceptual front-end, substantially outperform fully-learned distributed networks, a finding that was taken to support the above thesis. Here, we show on the contrary that a fully-learned neural network with the right inductive biases can perform substantially better than all previous neural-symbolic models on both of these tasks, particularly on questions that most emphasize reasoning over perception. Our model makes critical use of both self-attention and learned "soft" object-centric representations, as well as BERT-style semi-supervised predictive losses. These flexible biases allow our model to surpass the previous neuro-symbolic state-of-the-art using less than 60% of available labelled data. Together, these results refute the neuro-symbolic thesis laid out by previous work involving these datasets, and they provide evidence that neural networks can indeed learn to reason effectively about the causal, dynamic structure of physical events.
Adapting Behaviour for Learning Progress
Dec 14, 2019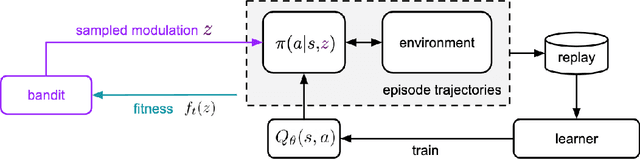

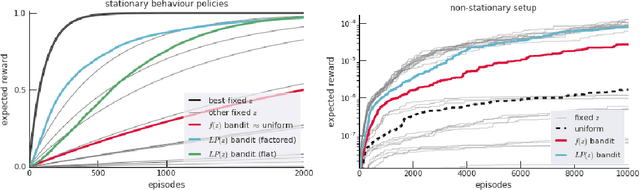
Determining what experience to generate to best facilitate learning (i.e. exploration) is one of the distinguishing features and open challenges in reinforcement learning. The advent of distributed agents that interact with parallel instances of the environment has enabled larger scales and greater flexibility, but has not removed the need to tune exploration to the task, because the ideal data for the learning algorithm necessarily depends on its process of learning. We propose to dynamically adapt the data generation by using a non-stationary multi-armed bandit to optimize a proxy of the learning progress. The data distribution is controlled by modulating multiple parameters of the policy (such as stochasticity, consistency or optimism) without significant overhead. The adaptation speed of the bandit can be increased by exploiting the factored modulation structure. We demonstrate on a suite of Atari 2600 games how this unified approach produces results comparable to per-task tuning at a fraction of the cost.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019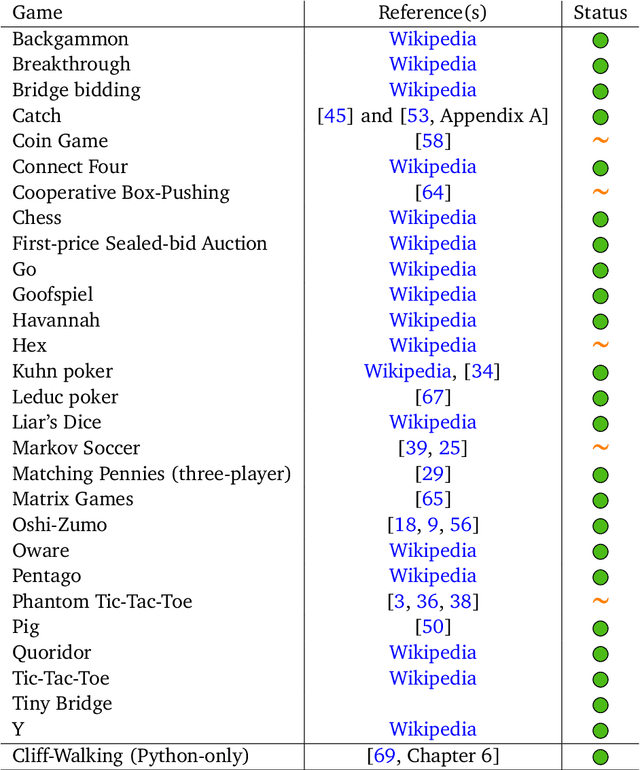
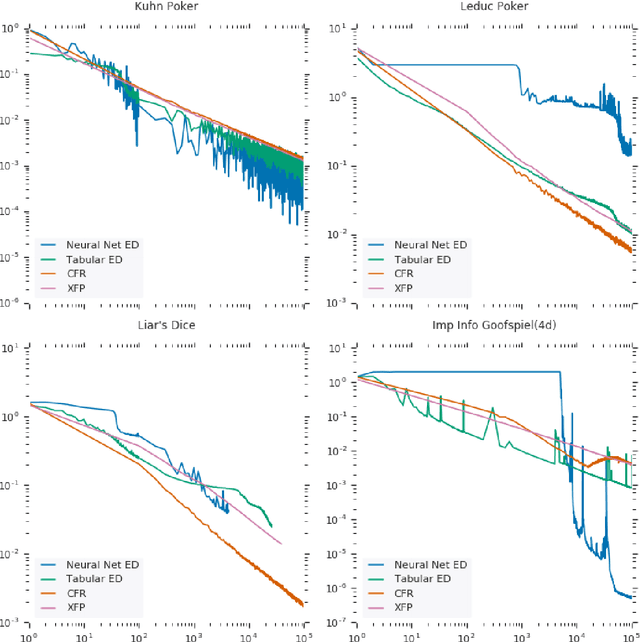
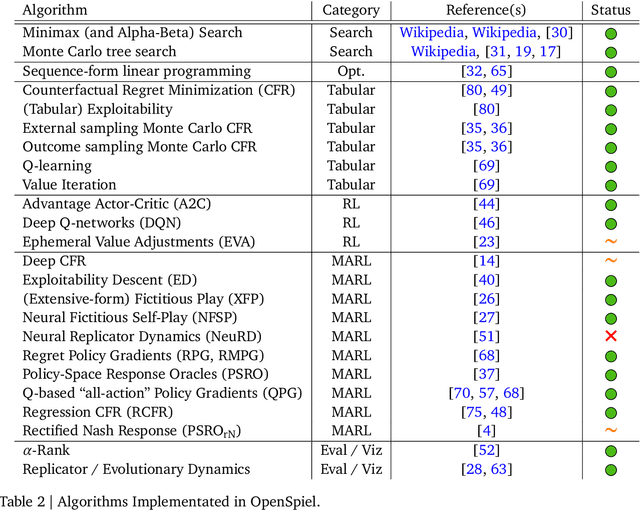
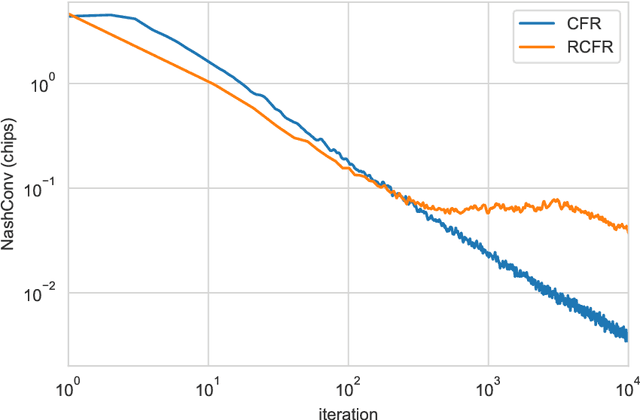
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
Deep Lattice Networks and Partial Monotonic Functions
Sep 19, 2017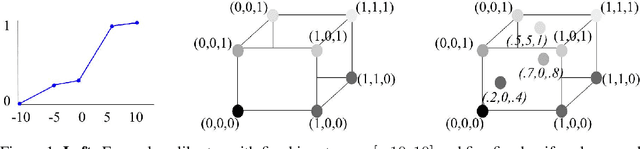

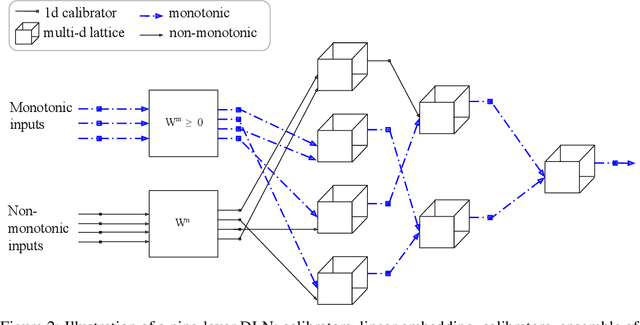

We propose learning deep models that are monotonic with respect to a user-specified set of inputs by alternating layers of linear embeddings, ensembles of lattices, and calibrators (piecewise linear functions), with appropriate constraints for monotonicity, and jointly training the resulting network. We implement the layers and projections with new computational graph nodes in TensorFlow and use the ADAM optimizer and batched stochastic gradients. Experiments on benchmark and real-world datasets show that six-layer monotonic deep lattice networks achieve state-of-the art performance for classification and regression with monotonicity guarantees.