 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Respecting Subtasks for Model-Based Reinforcement Learning
Feb 09, 2022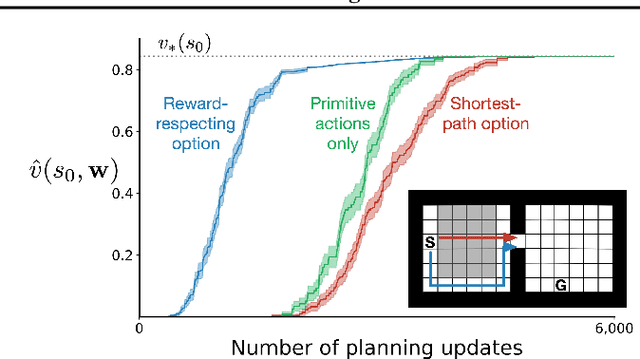
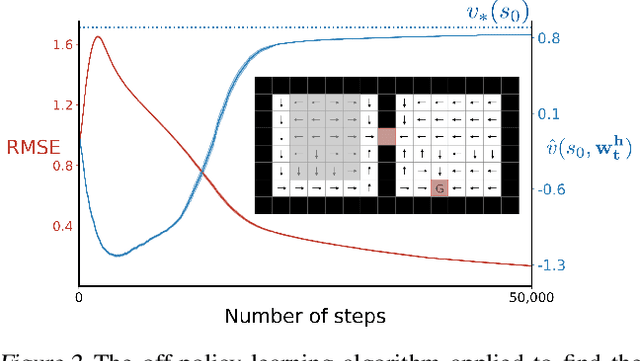
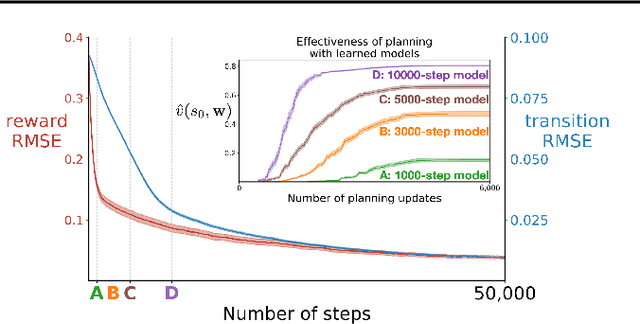
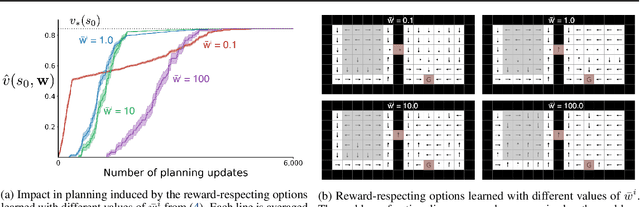
To achieve the ambitious goals of artificial intelligence, reinforcement learning must include planning with a model of the world that is abstract in state and time. Deep learning has made progress in state abstraction, but, although the theory of time abstraction has been extensively developed based on the options framework, in practice options have rarely been used in planning. One reason for this is that the space of possible options is immense and the methods previously proposed for option discovery do not take into account how the option models will be used in planning. Options are typically discovered by posing subsidiary tasks such as reaching a bottleneck state, or maximizing a sensory signal other than the reward. Each subtask is solved to produce an option, and then a model of the option is learned and made available to the planning process. The subtasks proposed in most previous work ignore the reward on the original problem, whereas we propose subtasks that use the original reward plus a bonus based on a feature of the state at the time the option stops. We show that options and option models obtained from such reward-respecting subtasks are much more likely to be useful in planning and can be learned online and off-policy using existing learning algorithms. Reward respecting subtasks strongly constrain the space of options and thereby also provide a partial solution to the problem of option discovery. Finally, we show how the algorithms for learning values, policies, options, and models can be unified using general value functions.
When should agents explore?
Aug 26, 2021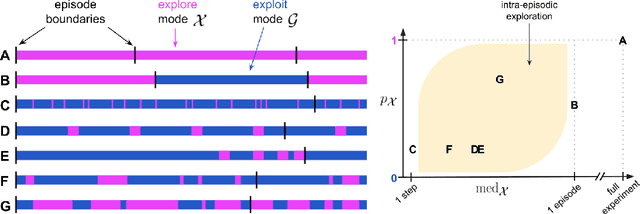
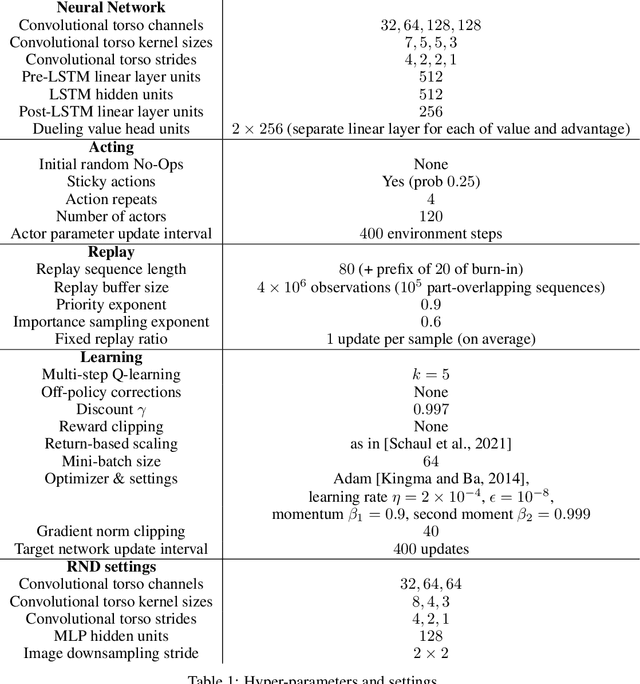
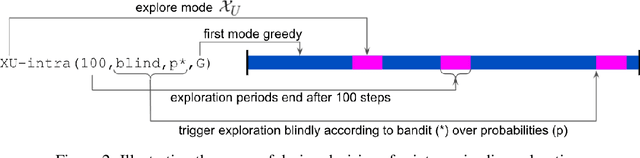
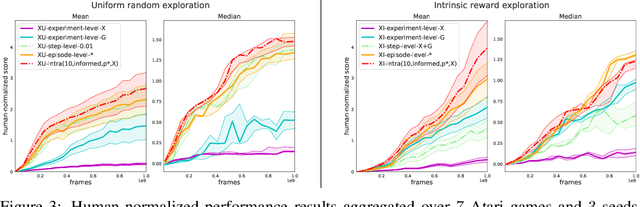
Exploration remains a central challenge for reinforcement learning (RL). Virtually all existing methods share the feature of a monolithic behaviour policy that changes only gradually (at best). In contrast, the exploratory behaviours of animals and humans exhibit a rich diversity, namely including forms of switching between modes. This paper presents an initial study of mode-switching, non-monolithic exploration for RL. We investigate different modes to switch between, at what timescales it makes sense to switch, and what signals make for good switching triggers. We also propose practical algorithmic components that make the switching mechanism adaptive and robust, which enables flexibility without an accompanying hyper-parameter-tuning burden. Finally, we report a promising and detailed analysis on Atari, using two-mode exploration and switching at sub-episodic time-scales.
Adapting Behaviour for Learning Progress
Dec 14, 2019

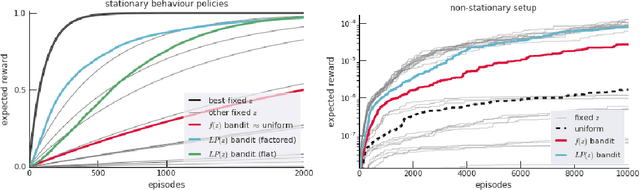
Determining what experience to generate to best facilitate learning (i.e. exploration) is one of the distinguishing features and open challenges in reinforcement learning. The advent of distributed agents that interact with parallel instances of the environment has enabled larger scales and greater flexibility, but has not removed the need to tune exploration to the task, because the ideal data for the learning algorithm necessarily depends on its process of learning. We propose to dynamically adapt the data generation by using a non-stationary multi-armed bandit to optimize a proxy of the learning progress. The data distribution is controlled by modulating multiple parameters of the policy (such as stochasticity, consistency or optimism) without significant overhead. The adaptation speed of the bandit can be increased by exploiting the factored modulation structure. We demonstrate on a suite of Atari 2600 games how this unified approach produces results comparable to per-task tuning at a fraction of the cost.
Grounded Language Learning in a Simulated 3D World
Jun 26, 2017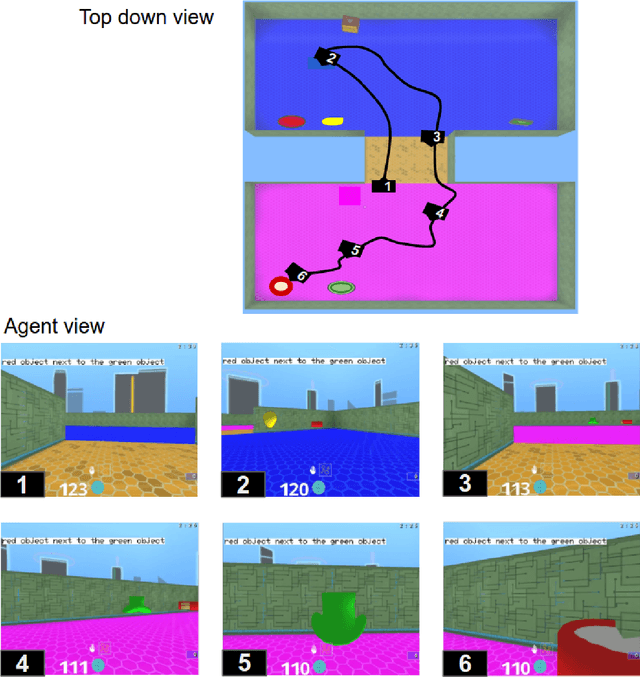

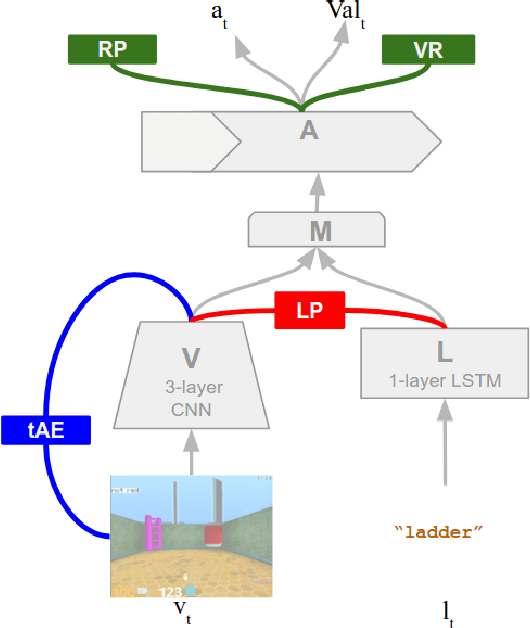
We are increasingly surrounded by artificially intelligent technology that takes decisions and executes actions on our behalf. This creates a pressing need for general means to communicate with, instruct and guide artificial agents, with human language the most compelling means for such communication. To achieve this in a scalable fashion, agents must be able to relate language to the world and to actions; that is, their understanding of language must be grounded and embodied. However, learning grounded language is a notoriously challenging problem in artificial intelligence research. Here we present an agent that learns to interpret language in a simulated 3D environment where it is rewarded for the successful execution of written instructions. Trained via a combination of reinforcement and unsupervised learning, and beginning with minimal prior knowledge, the agent learns to relate linguistic symbols to emergent perceptual representations of its physical surroundings and to pertinent sequences of actions. The agent's comprehension of language extends beyond its prior experience, enabling it to apply familiar language to unfamiliar situations and to interpret entirely novel instructions. Moreover, the speed with which this agent learns new words increases as its semantic knowledge grows. This facility for generalising and bootstrapping semantic knowledge indicates the potential of the present approach for reconciling ambiguous natural language with the complexity of the physical world.
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Aug 12, 2016


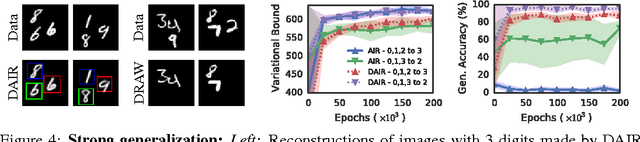
We present a framework for efficient inference in structured image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network. We further show that the networks produce accurate inferences when compared to supervised counterparts, and that their structure leads to improved generalization.