 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatEd: A Chatbot Leveraging ChatGPT for an Enhanced Learning Experience in Higher Education
Dec 29, 2023With the rapid evolution of Natural Language Processing (NLP), Large Language Models (LLMs) like ChatGPT have emerged as powerful tools capable of transforming various sectors. Their vast knowledge base and dynamic interaction capabilities represent significant potential in improving education by operating as a personalized assistant. However, the possibility of generating incorrect, biased, or unhelpful answers are a key challenge to resolve when deploying LLMs in an education context. This work introduces an innovative architecture that combines the strengths of ChatGPT with a traditional information retrieval based chatbot framework to offer enhanced student support in higher education. Our empirical evaluations underscore the high promise of this approach.
Student Mastery or AI Deception? Analyzing ChatGPT's Assessment Proficiency and Evaluating Detection Strategies
Nov 27, 2023



Generative AI systems such as ChatGPT have a disruptive effect on learning and assessment. Computer science requires practice to develop skills in problem solving and programming that are traditionally developed using assignments. Generative AI has the capability of completing these assignments for students with high accuracy, which dramatically increases the potential for academic integrity issues and students not achieving desired learning outcomes. This work investigates the performance of ChatGPT by evaluating it across three courses (CS1,CS2,databases). ChatGPT completes almost all introductory assessments perfectly. Existing detection methods, such as MOSS and JPlag (based on similarity metrics) and GPTzero (AI detection), have mixed success in identifying AI solutions. Evaluating instructors and teaching assistants using heuristics to distinguish between student and AI code shows that their detection is not sufficiently accurate. These observations emphasize the need for adapting assessments and improved detection methods.
LearnedSort as a learning-augmented SampleSort: Analysis and Parallelization
Jul 17, 2023This work analyzes and parallelizes LearnedSort, the novel algorithm that sorts using machine learning models based on the cumulative distribution function. LearnedSort is analyzed under the lens of algorithms with predictions, and it is argued that LearnedSort is a learning-augmented SampleSort. A parallel LearnedSort algorithm is developed combining LearnedSort with the state-of-the-art SampleSort implementation, IPS4o. Benchmarks on synthetic and real-world datasets demonstrate improved parallel performance for parallel LearnedSort compared to IPS4o and other sorting algorithms.
A Case Study on Record Matching of Individuals in Historical Archives of Indigenous Databases
Feb 15, 2023Digitization of historical records has produced a significant amount of data for analysis and interpretation. A critical challenge is the ability to relate historical information across different archives to allow for the data to be framed in the appropriate historical context. This paper presents a real-world case study on historical information integration and record matching with the goal to improve the historical value of archives containing data in the period 1800 to 1920. The archives contain unique information about M\'etis and Indigenous people in Canada and interactions with European settlers. The archives contain thousands of records that have increased relevance when relationships and interconnections are discovered. The contribution is a record linking approach suitable for historical archives and an evaluation of its effectiveness. Experimental results demonstrate potential for discovering historical linkage with high precision enabling new historical discoveries.
An Application of Deep Learning for Sweet Cherry Phenotyping using YOLO Object Detection
Feb 13, 2023Tree fruit breeding is a long-term activity involving repeated measurements of various fruit quality traits on a large number of samples. These traits are traditionally measured by manually counting the fruits, weighing to indirectly measure the fruit size, and fruit colour is classified subjectively into different color categories using visual comparison to colour charts. These processes are slow, expensive and subject to evaluators' bias and fatigue. Recent advancements in deep learning can help automate this process. A method was developed to automatically count the number of sweet cherry fruits in a camera's field of view in real time using YOLOv3. A system capable of analyzing the image data for other traits such as size and color was also developed using Python. The YOLO model obtained close to 99% accuracy in object detection and counting of cherries and 90% on the Intersection over Union metric for object localization when extracting size and colour information. The model surpasses human performance and offers a significant improvement compared to manual counting.
Using Learned Indexes to Improve Time Series Indexing Performance on Embedded Sensor Devices
Feb 06, 2023


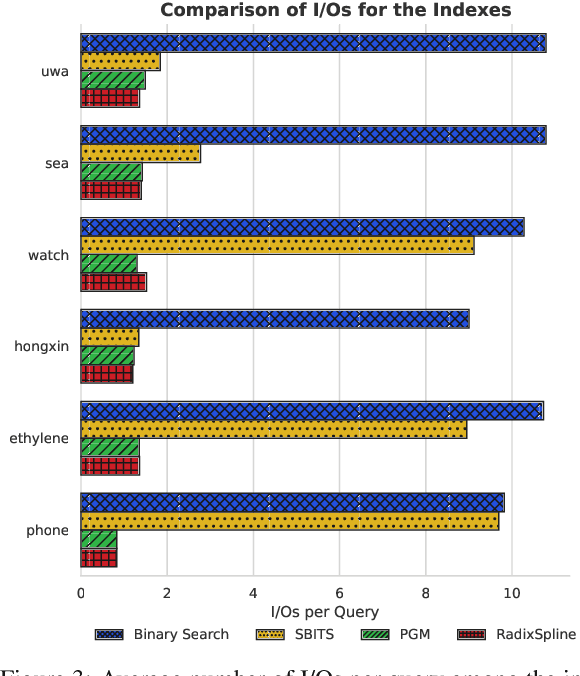
Efficiently querying data on embedded sensor and IoT devices is challenging given the very limited memory and CPU resources. With the increasing volumes of collected data, it is critical to process, filter, and manipulate data on the edge devices where it is collected to improve efficiency and reduce network transmissions. Existing embedded index structures do not adapt to the data distribution and characteristics. This paper demonstrates how applying learned indexes that develop space efficient summaries of the data can dramatically improve the query performance and predictability. Learned indexes based on linear approximations can reduce the query I/O by 50 to 90% and improve query throughput by a factor of 2 to 5, while only requiring a few kilobytes of RAM. Experimental results on a variety of time series data sets demonstrate the advantages of learned indexes that considerably improve over the state-of-the-art index algorithms.
A Survey of Online Experiment Design with the Stochastic Multi-Armed Bandit
Nov 03, 2015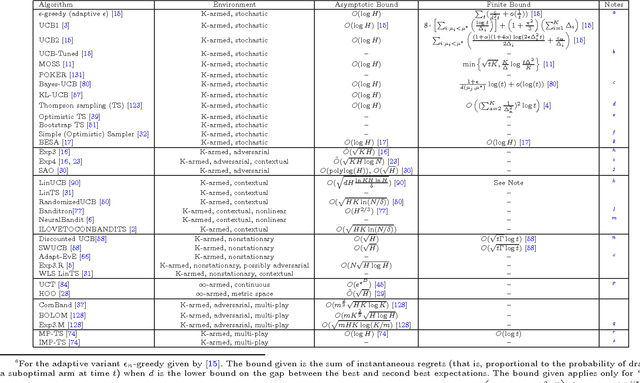
Adaptive and sequential experiment design is a well-studied area in numerous domains. We survey and synthesize the work of the online statistical learning paradigm referred to as multi-armed bandits integrating the existing research as a resource for a certain class of online experiments. We first explore the traditional stochastic model of a multi-armed bandit, then explore a taxonomic scheme of complications to that model, for each complication relating it to a specific requirement or consideration of the experiment design context. Finally, at the end of the paper, we present a table of known upper-bounds of regret for all studied algorithms providing both perspectives for future theoretical work and a decision-making tool for practitioners looking for theoretical guarantees.
Case-Based Subgoaling in Real-Time Heuristic Search for Video Game Pathfinding
Jan 16, 2014


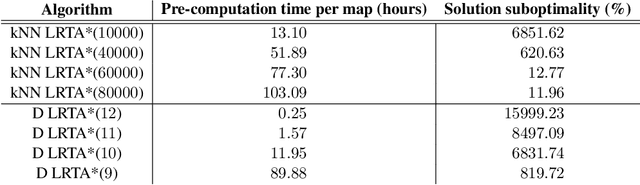
Real-time heuristic search algorithms satisfy a constant bound on the amount of planning per action, independent of problem size. As a result, they scale up well as problems become larger. This property would make them well suited for video games where Artificial Intelligence controlled agents must react quickly to user commands and to other agents actions. On the downside, real-time search algorithms employ learning methods that frequently lead to poor solution quality and cause the agent to appear irrational by re-visiting the same problem states repeatedly. The situation changed recently with a new algorithm, D LRTA*, which attempted to eliminate learning by automatically selecting subgoals. D LRTA* is well poised for video games, except it has a complex and memory-demanding pre-computation phase during which it builds a database of subgoals. In this paper, we propose a simpler and more memory-efficient way of pre-computing subgoals thereby eliminating the main obstacle to applying state-of-the-art real-time search methods in video games. The new algorithm solves a number of randomly chosen problems off-line, compresses the solutions into a series of subgoals and stores them in a database. When presented with a novel problem on-line, it queries the database for the most similar previously solved case and uses its subgoals to solve the problem. In the domain of pathfinding on four large video game maps, the new algorithm delivers solutions eight times better while using 57 times less memory and requiring 14% less pre-computation time.