 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Reasoning Tasks with a Slot Transformer
Paper and Code
Oct 20, 2022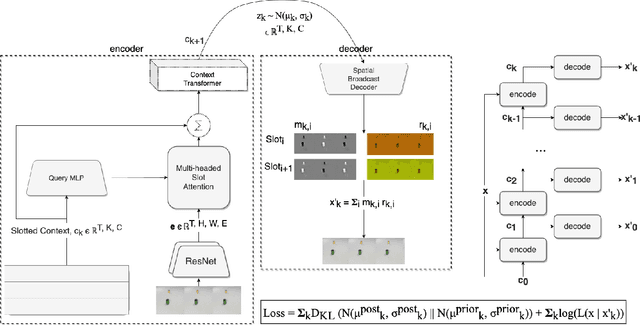
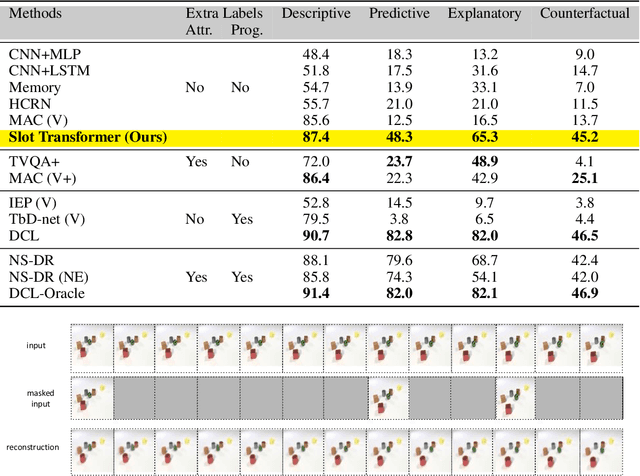
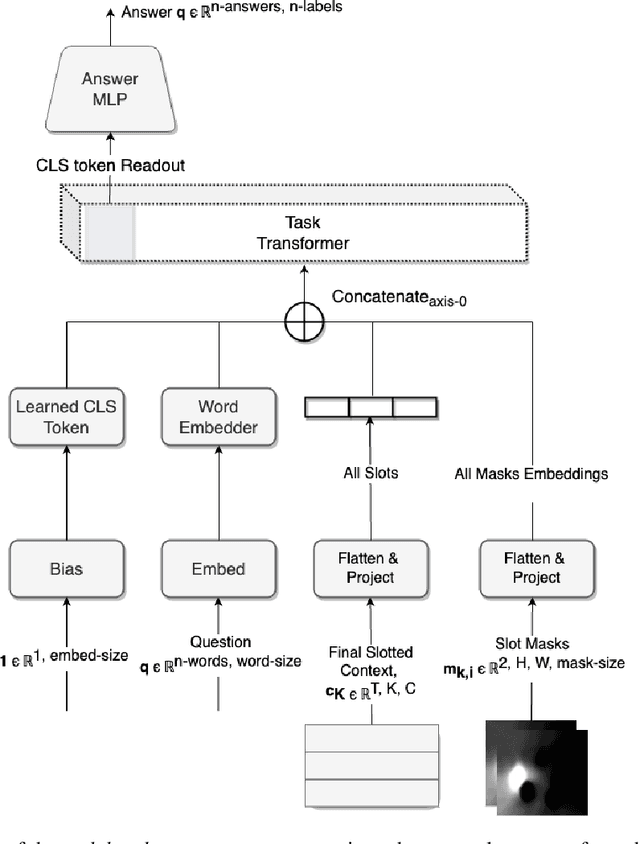
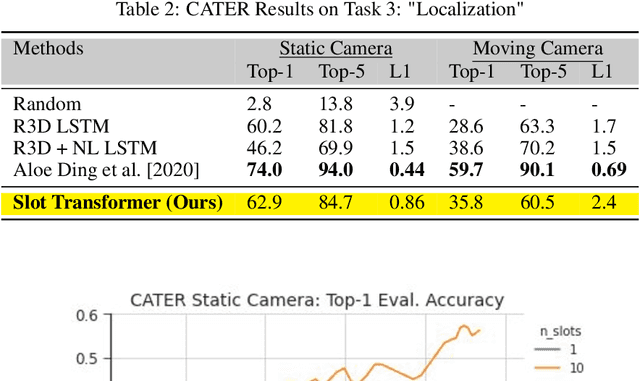
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.