 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation biases: will we achieve complete understanding by analyzing representations?
Jul 29, 2025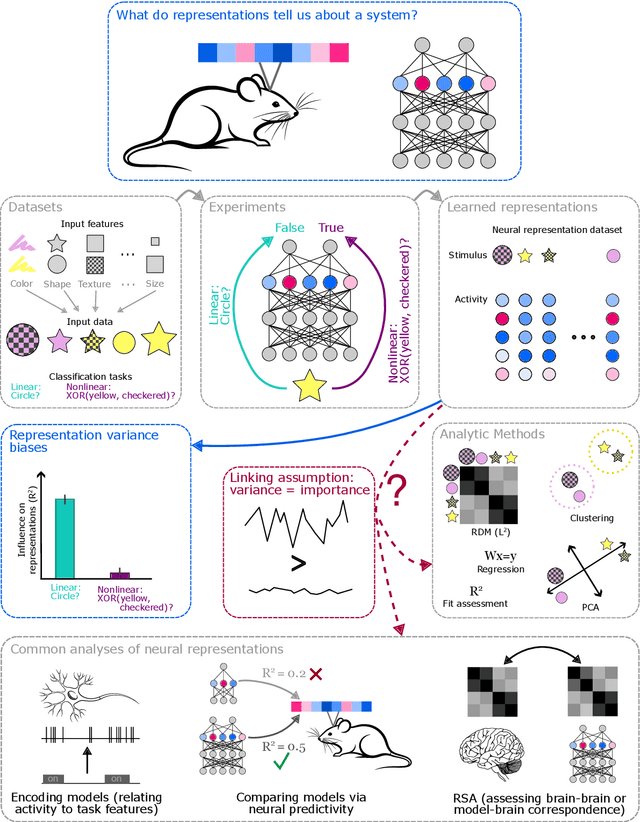
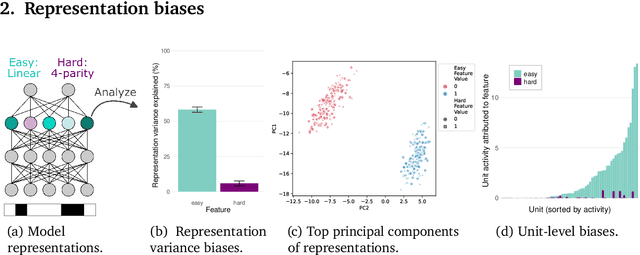
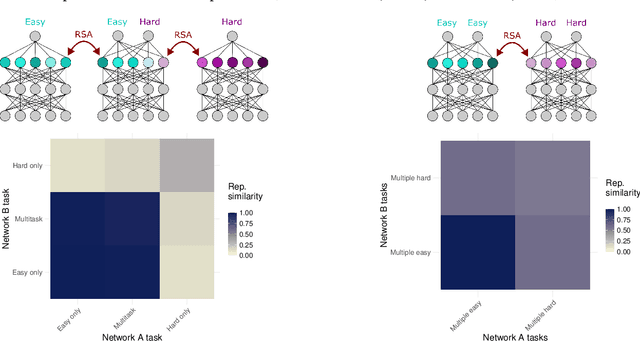
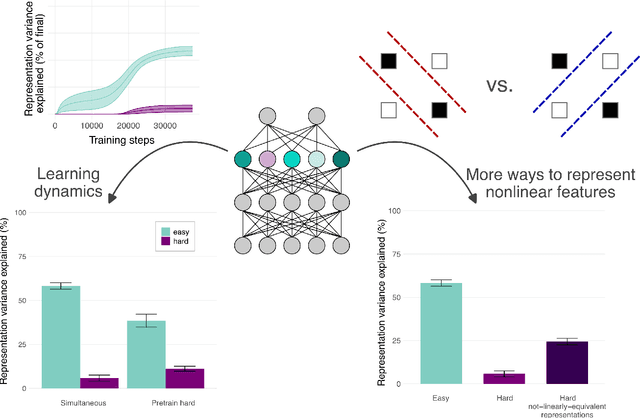
A common approach in neuroscience is to study neural representations as a means to understand a system -- increasingly, by relating the neural representations to the internal representations learned by computational models. However, a recent work in machine learning (Lampinen, 2024) shows that learned feature representations may be biased to over-represent certain features, and represent others more weakly and less-consistently. For example, simple (linear) features may be more strongly and more consistently represented than complex (highly nonlinear) features. These biases could pose challenges for achieving full understanding of a system through representational analysis. In this perspective, we illustrate these challenges -- showing how feature representation biases can lead to strongly biased inferences from common analyses like PCA, regression, and RSA. We also present homomorphic encryption as a simple case study of the potential for strong dissociation between patterns of representation and computation. We discuss the implications of these results for representational comparisons between systems, and for neuroscience more generally.
Understanding Visual Feature Reliance through the Lens of Complexity
Jul 08, 2024



Recent studies suggest that deep learning models inductive bias towards favoring simpler features may be one of the sources of shortcut learning. Yet, there has been limited focus on understanding the complexity of the myriad features that models learn. In this work, we introduce a new metric for quantifying feature complexity, based on $\mathscr{V}$-information and capturing whether a feature requires complex computational transformations to be extracted. Using this $\mathscr{V}$-information metric, we analyze the complexities of 10,000 features, represented as directions in the penultimate layer, that were extracted from a standard ImageNet-trained vision model. Our study addresses four key questions: First, we ask what features look like as a function of complexity and find a spectrum of simple to complex features present within the model. Second, we ask when features are learned during training. We find that simpler features dominate early in training, and more complex features emerge gradually. Third, we investigate where within the network simple and complex features flow, and find that simpler features tend to bypass the visual hierarchy via residual connections. Fourth, we explore the connection between features complexity and their importance in driving the networks decision. We find that complex features tend to be less important. Surprisingly, important features become accessible at earlier layers during training, like a sedimentation process, allowing the model to build upon these foundational elements.
Learned feature representations are biased by complexity, learning order, position, and more
May 09, 2024
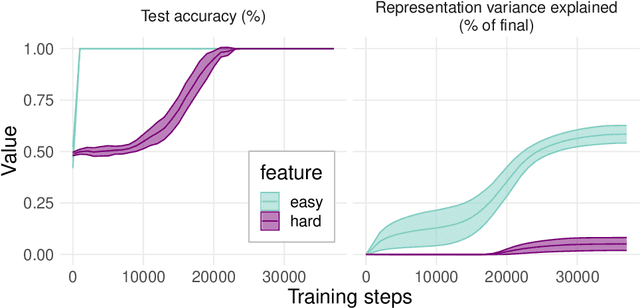

Representation learning, and interpreting learned representations, are key areas of focus in machine learning and neuroscience. Both fields generally use representations as a means to understand or improve a system's computations. In this work, however, we explore surprising dissociations between representation and computation that may pose challenges for such efforts. We create datasets in which we attempt to match the computational role that different features play, while manipulating other properties of the features or the data. We train various deep learning architectures to compute these multiple abstract features about their inputs. We find that their learned feature representations are systematically biased towards representing some features more strongly than others, depending upon extraneous properties such as feature complexity, the order in which features are learned, and the distribution of features over the inputs. For example, features that are simpler to compute or learned first tend to be represented more strongly and densely than features that are more complex or learned later, even if all features are learned equally well. We also explore how these biases are affected by architectures, optimizers, and training regimes (e.g., in transformers, features decoded earlier in the output sequence also tend to be represented more strongly). Our results help to characterize the inductive biases of gradient-based representation learning. These results also highlight a key challenge for interpretability $-$ or for comparing the representations of models and brains $-$ disentangling extraneous biases from the computationally important aspects of a system's internal representations.
Improving neural network representations using human similarity judgments
Jun 07, 2023Deep neural networks have reached human-level performance on many computer vision tasks. However, the objectives used to train these networks enforce only that similar images are embedded at similar locations in the representation space, and do not directly constrain the global structure of the resulting space. Here, we explore the impact of supervising this global structure by linearly aligning it with human similarity judgments. We find that a naive approach leads to large changes in local representational structure that harm downstream performance. Thus, we propose a novel method that aligns the global structure of representations while preserving their local structure. This global-local transform considerably improves accuracy across a variety of few-shot learning and anomaly detection tasks. Our results indicate that human visual representations are globally organized in a way that facilitates learning from few examples, and incorporating this global structure into neural network representations improves performance on downstream tasks.