 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Symbolic Reasoning for Neural-Network Verification
Mar 23, 2023



The neural network has become an integral part of modern software systems. However, they still suffer from various problems, in particular, vulnerability to adversarial attacks. In this work, we present a novel program reasoning framework for neural-network verification, which we refer to as symbolic reasoning. The key components of our framework are the use of the symbolic domain and the quadratic relation. The symbolic domain has very flexible semantics, and the quadratic relation is quite expressive. They allow us to encode many verification problems for neural networks as quadratic programs. Our scheme then relaxes the quadratic programs to semidefinite programs, which can be efficiently solved. This framework allows us to verify various neural-network properties under different scenarios, especially those that appear challenging for non-symbolic domains. Moreover, it introduces new representations and perspectives for the verification tasks. We believe that our framework can bring new theoretical insights and practical tools to verification problems for neural networks.
(Certified!!) Adversarial Robustness for Free!
Jun 21, 2022
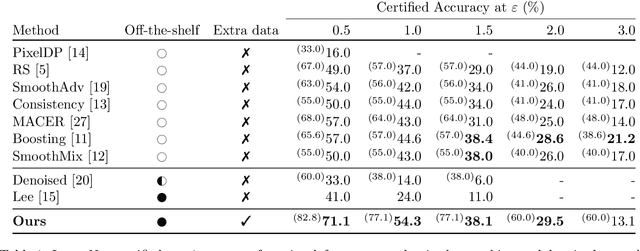
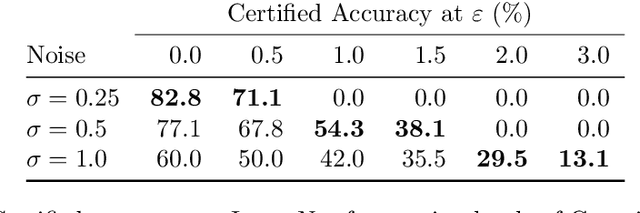

In this paper we show how to achieve state-of-the-art certified adversarial robustness to 2-norm bounded perturbations by relying exclusively on off-the-shelf pretrained models. To do so, we instantiate the denoised smoothing approach of Salman et al. by combining a pretrained denoising diffusion probabilistic model and a standard high-accuracy classifier. This allows us to certify 71% accuracy on ImageNet under adversarial perturbations constrained to be within a 2-norm of 0.5, an improvement of 14 percentage points over the prior certified SoTA using any approach, or an improvement of 30 percentage points over denoised smoothing. We obtain these results using only pretrained diffusion models and image classifiers, without requiring any fine tuning or retraining of model parameters.
A Fine-Grained Analysis on Distribution Shift
Oct 21, 2021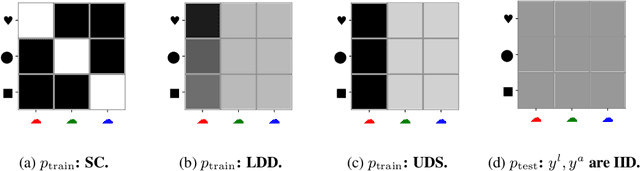

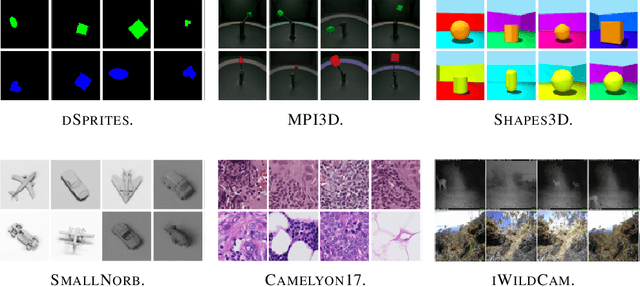

Robustness to distribution shifts is critical for deploying machine learning models in the real world. Despite this necessity, there has been little work in defining the underlying mechanisms that cause these shifts and evaluating the robustness of algorithms across multiple, different distribution shifts. To this end, we introduce a framework that enables fine-grained analysis of various distribution shifts. We provide a holistic analysis of current state-of-the-art methods by evaluating 19 distinct methods grouped into five categories across both synthetic and real-world datasets. Overall, we train more than 85K models. Our experimental framework can be easily extended to include new methods, shifts, and datasets. We find, unlike previous work~\citep{Gulrajani20}, that progress has been made over a standard ERM baseline; in particular, pretraining and augmentations (learned or heuristic) offer large gains in many cases. However, the best methods are not consistent over different datasets and shifts.
Learning Optimal Conformal Classifiers
Oct 18, 2021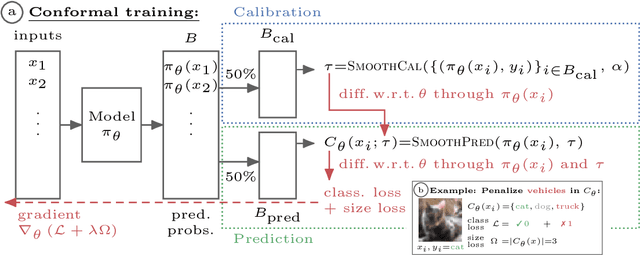



Modern deep learning based classifiers show very high accuracy on test data but this does not provide sufficient guarantees for safe deployment, especially in high-stake AI applications such as medical diagnosis. Usually, predictions are obtained without a reliable uncertainty estimate or a formal guarantee. Conformal prediction (CP) addresses these issues by using the classifier's probability estimates to predict confidence sets containing the true class with a user-specified probability. However, using CP as a separate processing step after training prevents the underlying model from adapting to the prediction of confidence sets. Thus, this paper explores strategies to differentiate through CP during training with the goal of training model with the conformal wrapper end-to-end. In our approach, conformal training (ConfTr), we specifically "simulate" conformalization on mini-batches during training. We show that CT outperforms state-of-the-art CP methods for classification by reducing the average confidence set size (inefficiency). Moreover, it allows to "shape" the confidence sets predicted at test time, which is difficult for standard CP. On experiments with several datasets, we show ConfTr can influence how inefficiency is distributed across classes, or guide the composition of confidence sets in terms of the included classes, while retaining the guarantees offered by CP.
Verifying Probabilistic Specifications with Functional Lagrangians
Feb 18, 2021
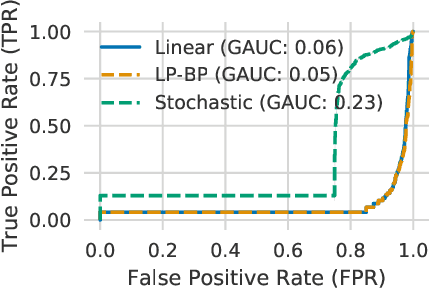
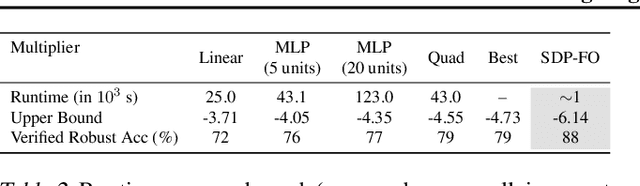
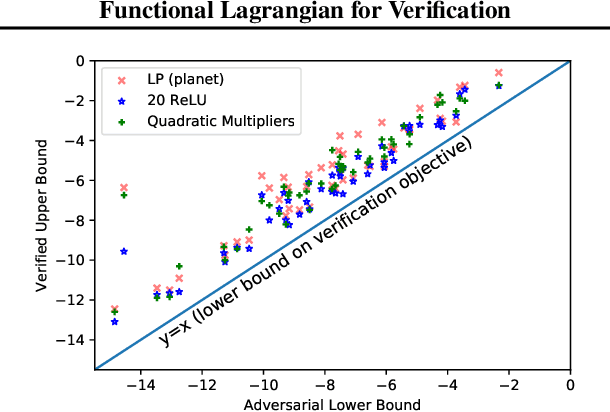
We propose a general framework for verifying input-output specifications of neural networks using functional Lagrange multipliers that generalizes standard Lagrangian duality. We derive theoretical properties of the framework, which can handle arbitrary probabilistic specifications, showing that it provably leads to tight verification when a sufficiently flexible class of functional multipliers is chosen. With a judicious choice of the class of functional multipliers, the framework can accommodate desired trade-offs between tightness and complexity. We demonstrate empirically that the framework can handle a diverse set of networks, including Bayesian neural networks with Gaussian posterior approximations, MC-dropout networks, and verify specifications on adversarial robustness and out-of-distribution(OOD) detection. Our framework improves upon prior work in some settings and also generalizes to new stochastic networks and probabilistic specifications, like distributionally robust OOD detection.
Towards transformation-resilient provenance detection of digital media
Nov 14, 2020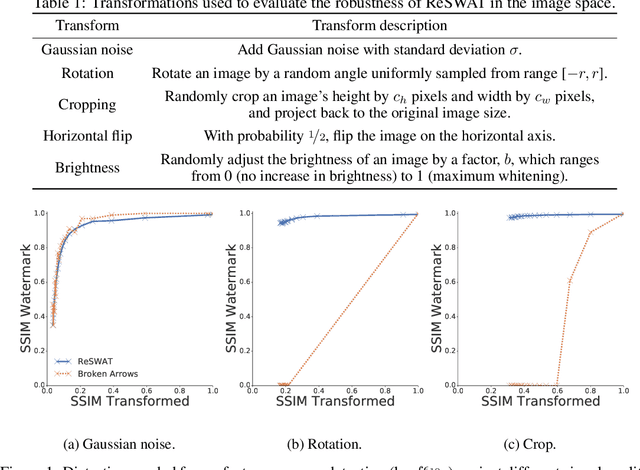
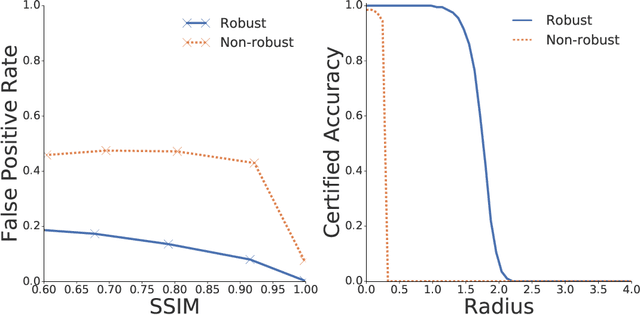

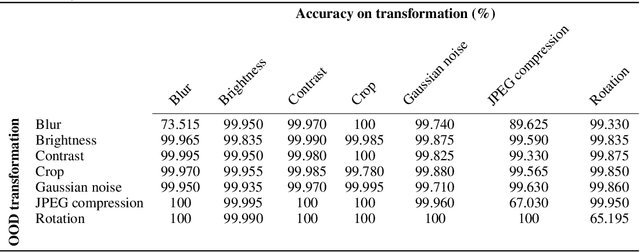
Advancements in deep generative models have made it possible to synthesize images, videos and audio signals that are difficult to distinguish from natural signals, creating opportunities for potential abuse of these capabilities. This motivates the problem of tracking the provenance of signals, i.e., being able to determine the original source of a signal. Watermarking the signal at the time of signal creation is a potential solution, but current techniques are brittle and watermark detection mechanisms can easily be bypassed by applying post-processing transformations (cropping images, shifting pitch in the audio etc.). In this paper, we introduce ReSWAT (Resilient Signal Watermarking via Adversarial Training), a framework for learning transformation-resilient watermark detectors that are able to detect a watermark even after a signal has been through several post-processing transformations. Our detection method can be applied to domains with continuous data representations such as images, videos or sound signals. Experiments on watermarking image and audio signals show that our method can reliably detect the provenance of a signal, even if it has been through several post-processing transformations, and improve upon related work in this setting. Furthermore, we show that for specific kinds of transformations (perturbations bounded in the L2 norm), we can even get formal guarantees on the ability of our model to detect the watermark. We provide qualitative examples of watermarked image and audio samples in https://drive.google.com/open?id=1-yZ0WIGNu2Iez7UpXBjtjVgZu3jJjFga.
An efficient nonconvex reformulation of stagewise convex optimization problems
Oct 27, 2020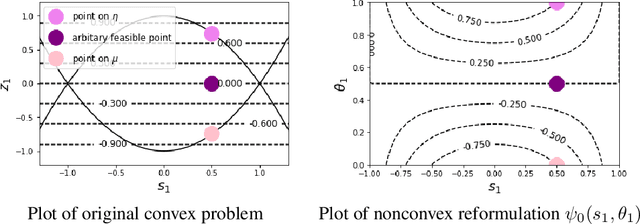
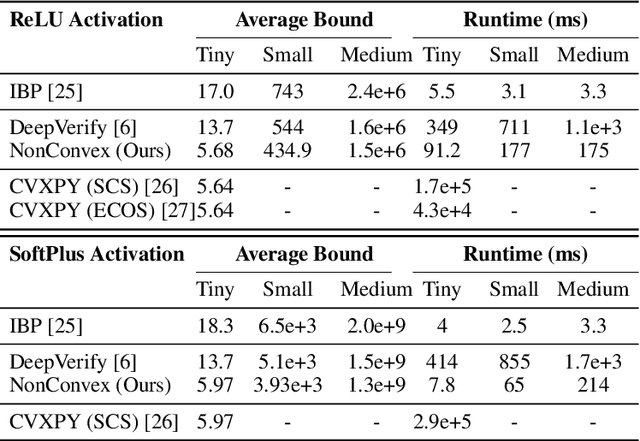
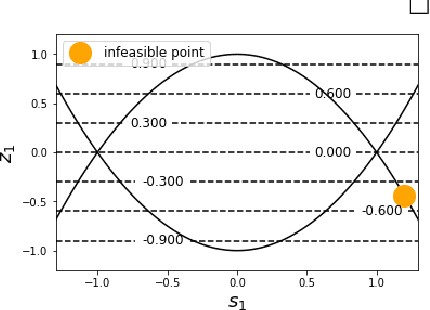
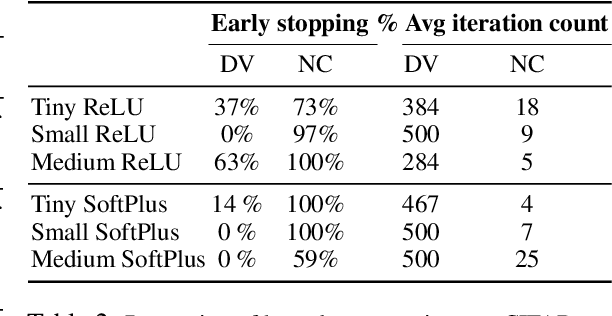
Convex optimization problems with staged structure appear in several contexts, including optimal control, verification of deep neural networks, and isotonic regression. Off-the-shelf solvers can solve these problems but may scale poorly. We develop a nonconvex reformulation designed to exploit this staged structure. Our reformulation has only simple bound constraints, enabling solution via projected gradient methods and their accelerated variants. The method automatically generates a sequence of primal and dual feasible solutions to the original convex problem, making optimality certification easy. We establish theoretical properties of the nonconvex formulation, showing that it is (almost) free of spurious local minima and has the same global optimum as the convex problem. We modify PGD to avoid spurious local minimizers so it always converges to the global minimizer. For neural network verification, our approach obtains small duality gaps in only a few gradient steps. Consequently, it can quickly solve large-scale verification problems faster than both off-the-shelf and specialized solvers.
Adversarial Robustness through Local Linearization
Jul 04, 2019
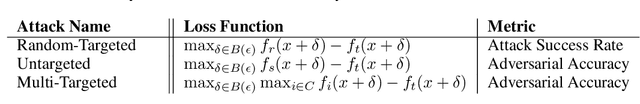
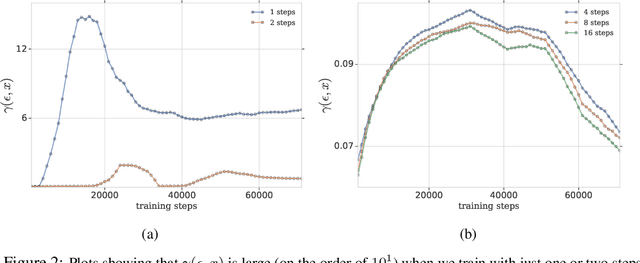
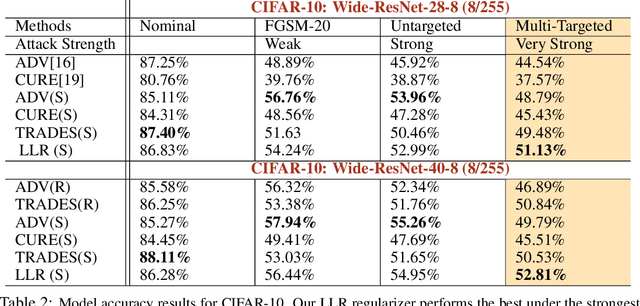
Adversarial training is an effective methodology for training deep neural networks that are robust against adversarial, norm-bounded perturbations. However, the computational cost of adversarial training grows prohibitively as the size of the model and number of input dimensions increase. Further, training against less expensive and therefore weaker adversaries produces models that are robust against weak attacks but break down under attacks that are stronger. This is often attributed to the phenomenon of gradient obfuscation; such models have a highly non-linear loss surface in the vicinity of training examples, making it hard for gradient-based attacks to succeed even though adversarial examples still exist. In this work, we introduce a novel regularizer that encourages the loss to behave linearly in the vicinity of the training data, thereby penalizing gradient obfuscation while encouraging robustness. We show via extensive experiments on CIFAR-10 and ImageNet, that models trained with our regularizer avoid gradient obfuscation and can be trained significantly faster than adversarial training. Using this regularizer, we exceed current state of the art and achieve 47% adversarial accuracy for ImageNet with l-infinity adversarial perturbations of radius 4/255 under an untargeted, strong, white-box attack. Additionally, we match state of the art results for CIFAR-10 at 8/255.
Verification of Non-Linear Specifications for Neural Networks
Feb 25, 2019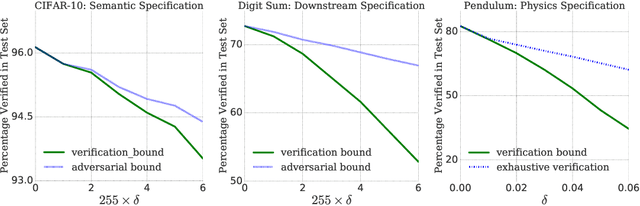
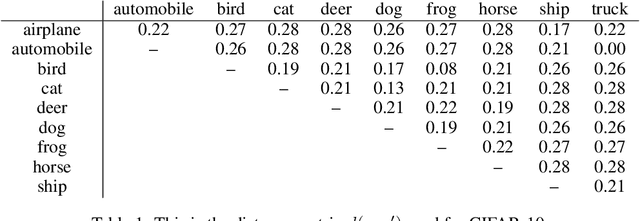
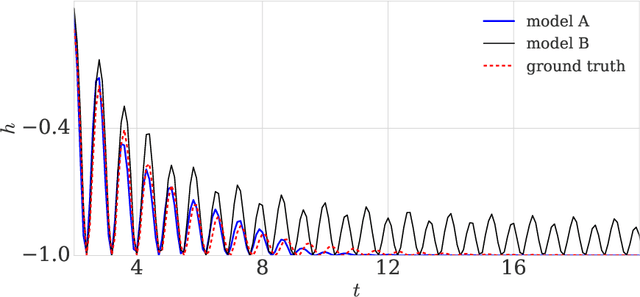
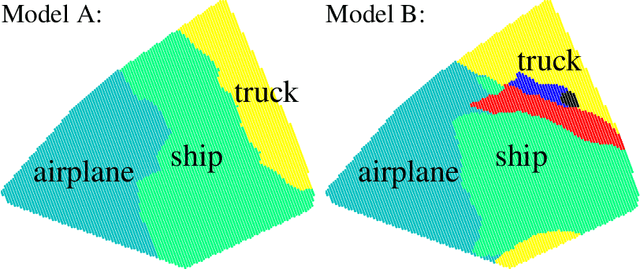
Prior work on neural network verification has focused on specifications that are linear functions of the output of the network, e.g., invariance of the classifier output under adversarial perturbations of the input. In this paper, we extend verification algorithms to be able to certify richer properties of neural networks. To do this we introduce the class of convex-relaxable specifications, which constitute nonlinear specifications that can be verified using a convex relaxation. We show that a number of important properties of interest can be modeled within this class, including conservation of energy in a learned dynamics model of a physical system; semantic consistency of a classifier's output labels under adversarial perturbations and bounding errors in a system that predicts the summation of handwritten digits. Our experimental evaluation shows that our method is able to effectively verify these specifications. Moreover, our evaluation exposes the failure modes in models which cannot be verified to satisfy these specifications. Thus, emphasizing the importance of training models not just to fit training data but also to be consistent with specifications.
A Dual Approach to Scalable Verification of Deep Networks
Aug 03, 2018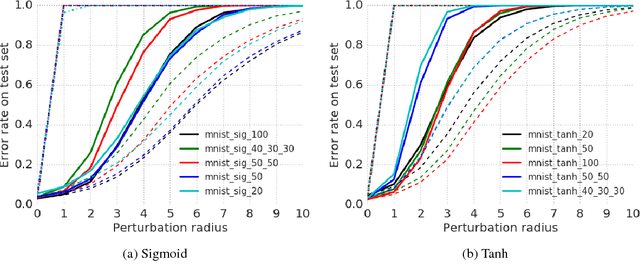
This paper addresses the problem of formally verifying desirable properties of neural networks, i.e., obtaining provable guarantees that neural networks satisfy specifications relating their inputs and outputs (robustness to bounded norm adversarial perturbations, for example). Most previous work on this topic was limited in its applicability by the size of the network, network architecture and the complexity of properties to be verified. In contrast, our framework applies to a general class of activation functions and specifications on neural network inputs and outputs. We formulate verification as an optimization problem (seeking to find the largest violation of the specification) and solve a Lagrangian relaxation of the optimization problem to obtain an upper bound on the worst case violation of the specification being verified. Our approach is anytime i.e. it can be stopped at any time and a valid bound on the maximum violation can be obtained. We develop specialized verification algorithms with provable tightness guarantees under special assumptions and demonstrate the practical significance of our general verification approach on a variety of verification tasks.