 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal prediction under ambiguous ground truth
Jul 18, 2023



In safety-critical classification tasks, conformal prediction allows to perform rigorous uncertainty quantification by providing confidence sets including the true class with a user-specified probability. This generally assumes the availability of a held-out calibration set with access to ground truth labels. Unfortunately, in many domains, such labels are difficult to obtain and usually approximated by aggregating expert opinions. In fact, this holds true for almost all datasets, including well-known ones such as CIFAR and ImageNet. Applying conformal prediction using such labels underestimates uncertainty. Indeed, when expert opinions are not resolvable, there is inherent ambiguity present in the labels. That is, we do not have ``crisp'', definitive ground truth labels and this uncertainty should be taken into account during calibration. In this paper, we develop a conformal prediction framework for such ambiguous ground truth settings which relies on an approximation of the underlying posterior distribution of labels given inputs. We demonstrate our methodology on synthetic and real datasets, including a case study of skin condition classification in dermatology.
Evaluating AI systems under uncertain ground truth: a case study in dermatology
Jul 05, 2023



For safety, AI systems in health undergo thorough evaluations before deployment, validating their predictions against a ground truth that is assumed certain. However, this is actually not the case and the ground truth may be uncertain. Unfortunately, this is largely ignored in standard evaluation of AI models but can have severe consequences such as overestimating the future performance. To avoid this, we measure the effects of ground truth uncertainty, which we assume decomposes into two main components: annotation uncertainty which stems from the lack of reliable annotations, and inherent uncertainty due to limited observational information. This ground truth uncertainty is ignored when estimating the ground truth by deterministically aggregating annotations, e.g., by majority voting or averaging. In contrast, we propose a framework where aggregation is done using a statistical model. Specifically, we frame aggregation of annotations as posterior inference of so-called plausibilities, representing distributions over classes in a classification setting, subject to a hyper-parameter encoding annotator reliability. Based on this model, we propose a metric for measuring annotation uncertainty and provide uncertainty-adjusted metrics for performance evaluation. We present a case study applying our framework to skin condition classification from images where annotations are provided in the form of differential diagnoses. The deterministic adjudication process called inverse rank normalization (IRN) from previous work ignores ground truth uncertainty in evaluation. Instead, we present two alternative statistical models: a probabilistic version of IRN and a Plackett-Luce-based model. We find that a large portion of the dataset exhibits significant ground truth uncertainty and standard IRN-based evaluation severely over-estimates performance without providing uncertainty estimates.
Transformers Meet Directed Graphs
Jan 31, 2023Transformers were originally proposed as a sequence-to-sequence model for text but have become vital for a wide range of modalities, including images, audio, video, and undirected graphs. However, transformers for directed graphs are a surprisingly underexplored topic, despite their applicability to ubiquitous domains including source code and logic circuits. In this work, we propose two direction- and structure-aware positional encodings for directed graphs: (1) the eigenvectors of the Magnetic Laplacian - a direction-aware generalization of the combinatorial Laplacian; (2) directional random walk encodings. Empirically, we show that the extra directionality information is useful in various downstream tasks, including correctness testing of sorting networks and source code understanding. Together with a data-flow-centric graph construction, our model outperforms the prior state of the art on the Open Graph Benchmark Code2 relatively by 14.7%.
Learning Optimal Conformal Classifiers
Oct 18, 2021



Modern deep learning based classifiers show very high accuracy on test data but this does not provide sufficient guarantees for safe deployment, especially in high-stake AI applications such as medical diagnosis. Usually, predictions are obtained without a reliable uncertainty estimate or a formal guarantee. Conformal prediction (CP) addresses these issues by using the classifier's probability estimates to predict confidence sets containing the true class with a user-specified probability. However, using CP as a separate processing step after training prevents the underlying model from adapting to the prediction of confidence sets. Thus, this paper explores strategies to differentiate through CP during training with the goal of training model with the conformal wrapper end-to-end. In our approach, conformal training (ConfTr), we specifically "simulate" conformalization on mini-batches during training. We show that CT outperforms state-of-the-art CP methods for classification by reducing the average confidence set size (inefficiency). Moreover, it allows to "shape" the confidence sets predicted at test time, which is difficult for standard CP. On experiments with several datasets, we show ConfTr can influence how inefficiency is distributed across classes, or guide the composition of confidence sets in terms of the included classes, while retaining the guarantees offered by CP.
Towards Fair Personalization by Avoiding Feedback Loops
Dec 20, 2020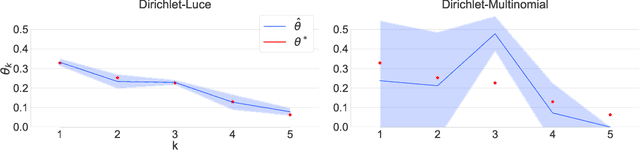
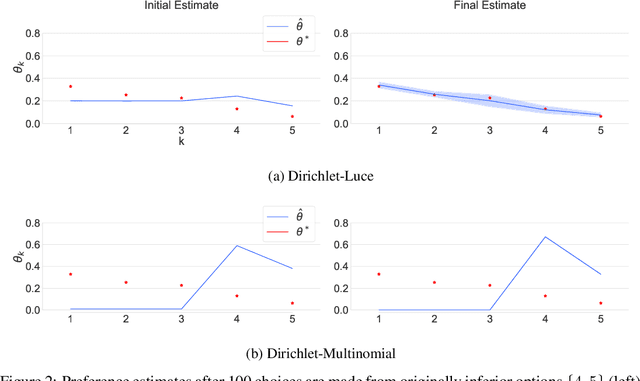

Self-reinforcing feedback loops are both cause and effect of over and/or under-presentation of some content in interactive recommender systems. This leads to erroneous user preference estimates, namely, overestimation of over-presented content while violating the right to be presented of each alternative, contrary of which we define as a fair system. We consider two models that explicitly incorporate, or ignore the systematic and limited exposure to alternatives. By simulations, we demonstrate that ignoring the systematic presentations overestimates promoted options and underestimates censored alternatives. Simply conditioning on the limited exposure is a remedy for these biases.
Intermittent Demand Forecasting with Renewal Processes
Oct 04, 2020
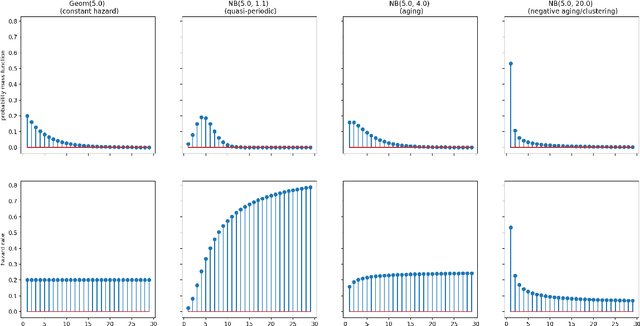


Intermittency is a common and challenging problem in demand forecasting. We introduce a new, unified framework for building intermittent demand forecasting models, which incorporates and allows to generalize existing methods in several directions. Our framework is based on extensions of well-established model-based methods to discrete-time renewal processes, which can parsimoniously account for patterns such as aging, clustering and quasi-periodicity in demand arrivals. The connection to discrete-time renewal processes allows not only for a principled extension of Croston-type models, but also for an natural inclusion of neural network based models---by replacing exponential smoothing with a recurrent neural network. We also demonstrate that modeling continuous-time demand arrivals, i.e., with a temporal point process, is possible via a trivial extension of our framework. This leads to more flexible modeling in scenarios where data of individual purchase orders are directly available with granular timestamps. Complementing this theoretical advancement, we demonstrate the efficacy of our framework for forecasting practice via an extensive empirical study on standard intermittent demand data sets, in which we report predictive accuracy in a variety of scenarios that compares favorably to the state of the art.
A Bayesian Choice Model for Eliminating Feedback Loops
Aug 21, 2019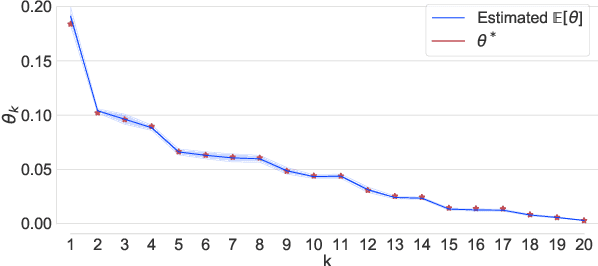

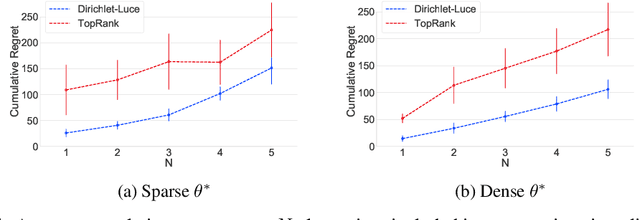
Self-reinforcing feedback loops in personalization systems are typically caused by users choosing from a limited set of alternatives presented systematically based on previous choices. We propose a Bayesian choice model built on Luce axioms that explicitly accounts for users' limited exposure to alternatives. Our model is fair---it does not impose negative bias towards unpresented alternatives, and practical---preference estimates are accurately inferred upon observing a small number of interactions. It also allows efficient sampling, leading to a straightforward online presentation mechanism based on Thompson sampling. Our approach achieves low regret in learning to present upon exploration of only a small fraction of possible presentations. The proposed structure can be reused as a building block in interactive systems, e.g., recommender systems, free of feedback loops.
Bayesian Allocation Model: Inference by Sequential Monte Carlo for Nonnegative Tensor Factorizations and Topic Models using Polya Urns
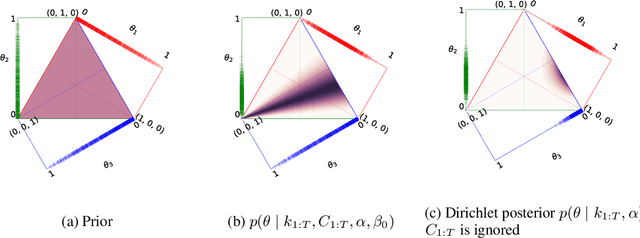
Mar 11, 2019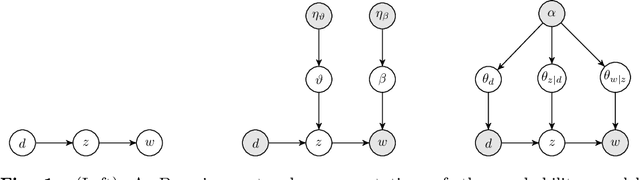
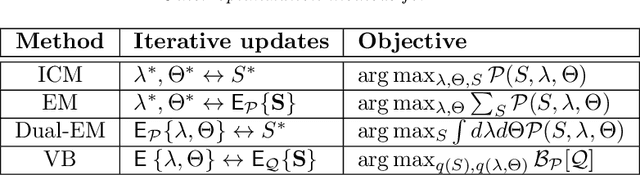
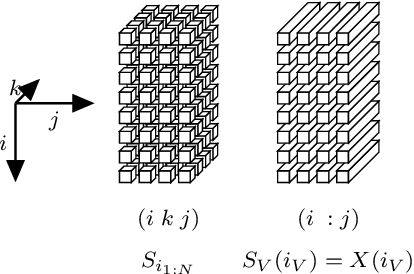
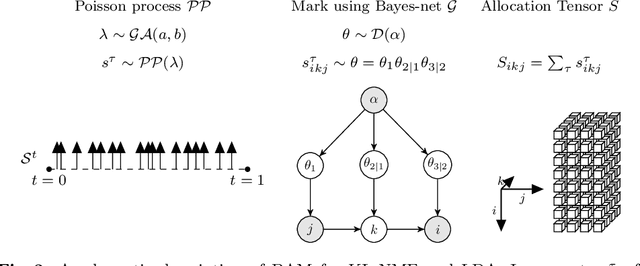
We introduce a dynamic generative model, Bayesian allocation model (BAM), which establishes explicit connections between nonnegative tensor factorization (NTF), graphical models of discrete probability distributions and their Bayesian extensions, and the topic models such as the latent Dirichlet allocation. BAM is based on a Poisson process, whose events are marked by using a Bayesian network, where the conditional probability tables of this network are then integrated out analytically. We show that the resulting marginal process turns out to be a Polya urn, an integer valued self-reinforcing process. This urn processes, which we name a Polya-Bayes process, obey certain conditional independence properties that provide further insight about the nature of NTF. These insights also let us develop space efficient simulation algorithms that respect the potential sparsity of data: we propose a class of sequential importance sampling algorithms for computing NTF and approximating their marginal likelihood, which would be useful for model selection. The resulting methods can also be viewed as a model scoring method for topic models and discrete Bayesian networks with hidden variables. The new algorithms have favourable properties in the sparse data regime when contrasted with variational algorithms that become more accurate when the total sum of the elements of the observed tensor goes to infinity. We illustrate the performance on several examples and numerically study the behaviour of the algorithms for various data regimes.
Weak Label Supervision for Monaural Source Separation Using Non-negative Denoising Variational Autoencoders
Nov 05, 2018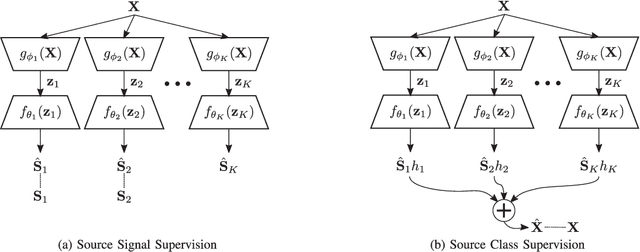
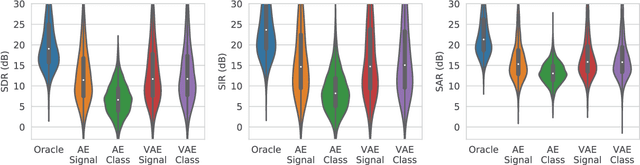
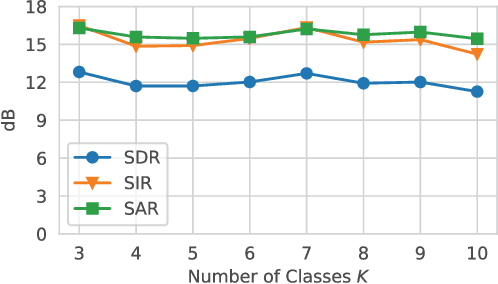
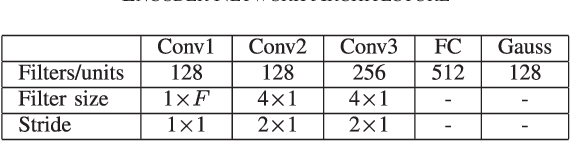
Deep learning models are very effective in source separation when there are large amounts of labeled data available. However it is not always possible to have carefully labeled datasets. In this paper, we propose a weak supervision method that only uses class information rather than source signals for learning to separate short utterance mixtures. We associate a variational autoencoder (VAE) with each class within a non-negative model. We demonstrate that deep convolutional VAEs provide a prior model to identify complex signals in a sound mixture without having access to any source signal. We show that the separation results are on par with source signal supervision.
Differentially Private Variational Dropout
Dec 16, 2017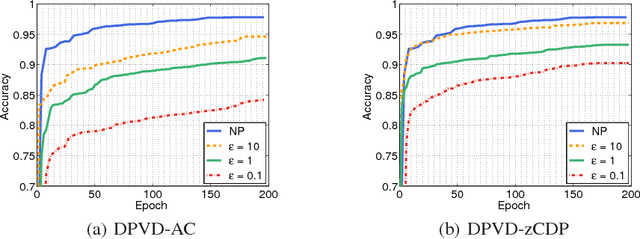
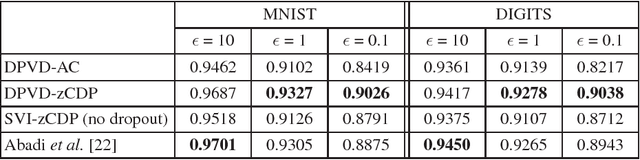
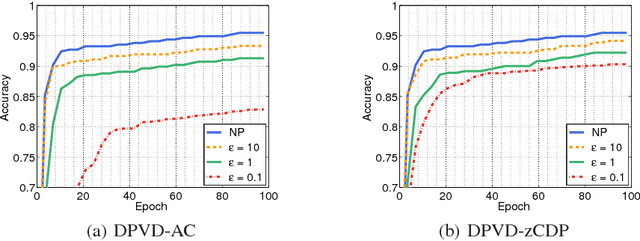
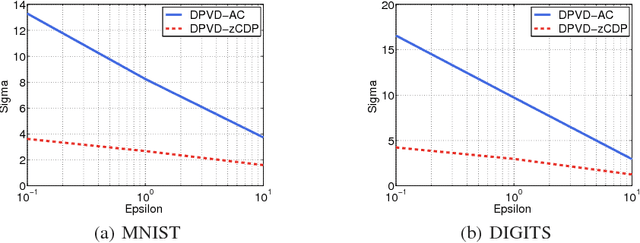
Deep neural networks with their large number of parameters are highly flexible learning systems. The high flexibility in such networks brings with some serious problems such as overfitting, and regularization is used to address this problem. A currently popular and effective regularization technique for controlling the overfitting is dropout. Often, large data collections required for neural networks contain sensitive information such as the medical histories of patients, and the privacy of the training data should be protected. In this paper, we modify the recently proposed variational dropout technique which provided an elegant Bayesian interpretation to dropout, and show that the intrinsic noise in the variational dropout can be exploited to obtain a degree of differential privacy. The iterative nature of training neural networks presents a challenge for privacy-preserving estimation since multiple iterations increase the amount of noise added. We overcome this by using a relaxed notion of differential privacy, called concentrated differential privacy, which provides tighter estimates on the overall privacy loss. We demonstrate the accuracy of our privacy-preserving variational dropout algorithm on benchmark datasets.