Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Label Supervision for Monaural Source Separation Using Non-negative Denoising Variational Autoencoders
Paper and Code
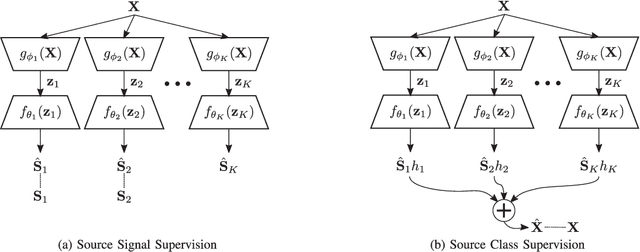
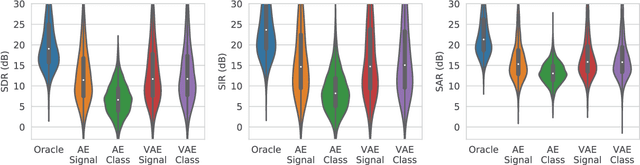
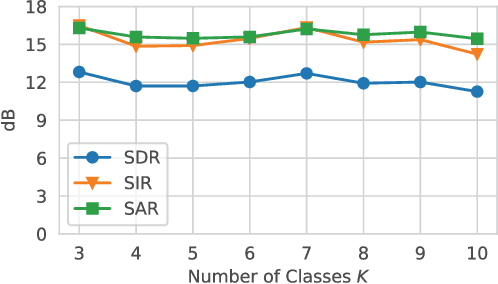
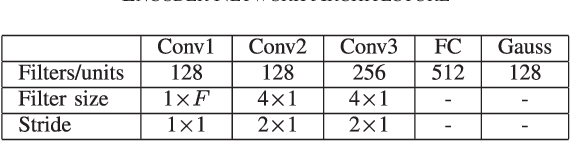
Deep learning models are very effective in source separation when there are large amounts of labeled data available. However it is not always possible to have carefully labeled datasets. In this paper, we propose a weak supervision method that only uses class information rather than source signals for learning to separate short utterance mixtures. We associate a variational autoencoder (VAE) with each class within a non-negative model. We demonstrate that deep convolutional VAEs provide a prior model to identify complex signals in a sound mixture without having access to any source signal. We show that the separation results are on par with source signal supervision.
View paper on