 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Source Separation via Self-Supervised Training
Feb 08, 2022



We introduce two novel unsupervised (blind) source separation methods, which involve self-supervised training from single-channel two-source speech mixtures without any access to the ground truth source signals. Our first method employs permutation invariant training (PIT) to separate artificially-generated mixtures of the original mixtures back into the original mixtures, which we named mixture permutation invariant training (MixPIT). We found this challenging objective to be a valid proxy task for learning to separate the underlying sources. We improve upon this first method by creating mixtures of source estimates and employing PIT to separate these new mixtures in a cyclic fashion. We named this second method cyclic mixture permutation invariant training (MixCycle), where cyclic refers to the fact that we use the same model to produce artificial mixtures and to learn from them continuously. We show that MixPIT outperforms a common baseline (MixIT) on our small dataset (SC09Mix), and they have comparable performance on a standard dataset (LibriMix). Strikingly, we also show that MixCycle surpasses the performance of supervised PIT by being data-efficient, thanks to its inherent data augmentation mechanism. To the best of our knowledge, no other purely unsupervised method is able to match or exceed the performance of supervised training.
Weak Label Supervision for Monaural Source Separation Using Non-negative Denoising Variational Autoencoders
Nov 05, 2018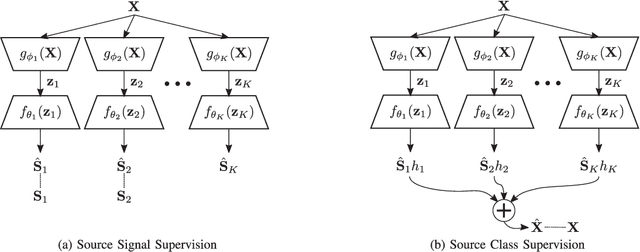
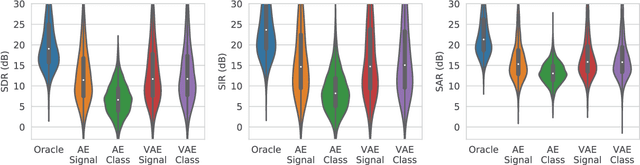
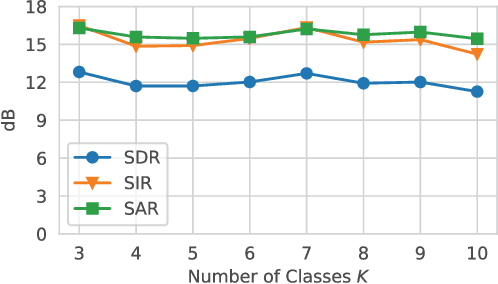
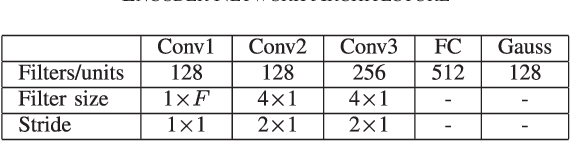
Deep learning models are very effective in source separation when there are large amounts of labeled data available. However it is not always possible to have carefully labeled datasets. In this paper, we propose a weak supervision method that only uses class information rather than source signals for learning to separate short utterance mixtures. We associate a variational autoencoder (VAE) with each class within a non-negative model. We demonstrate that deep convolutional VAEs provide a prior model to identify complex signals in a sound mixture without having access to any source signal. We show that the separation results are on par with source signal supervision.