 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI systems under uncertain ground truth: a case study in dermatology
Jul 05, 2023



For safety, AI systems in health undergo thorough evaluations before deployment, validating their predictions against a ground truth that is assumed certain. However, this is actually not the case and the ground truth may be uncertain. Unfortunately, this is largely ignored in standard evaluation of AI models but can have severe consequences such as overestimating the future performance. To avoid this, we measure the effects of ground truth uncertainty, which we assume decomposes into two main components: annotation uncertainty which stems from the lack of reliable annotations, and inherent uncertainty due to limited observational information. This ground truth uncertainty is ignored when estimating the ground truth by deterministically aggregating annotations, e.g., by majority voting or averaging. In contrast, we propose a framework where aggregation is done using a statistical model. Specifically, we frame aggregation of annotations as posterior inference of so-called plausibilities, representing distributions over classes in a classification setting, subject to a hyper-parameter encoding annotator reliability. Based on this model, we propose a metric for measuring annotation uncertainty and provide uncertainty-adjusted metrics for performance evaluation. We present a case study applying our framework to skin condition classification from images where annotations are provided in the form of differential diagnoses. The deterministic adjudication process called inverse rank normalization (IRN) from previous work ignores ground truth uncertainty in evaluation. Instead, we present two alternative statistical models: a probabilistic version of IRN and a Plackett-Luce-based model. We find that a large portion of the dataset exhibits significant ground truth uncertainty and standard IRN-based evaluation severely over-estimates performance without providing uncertainty estimates.
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Apr 13, 2022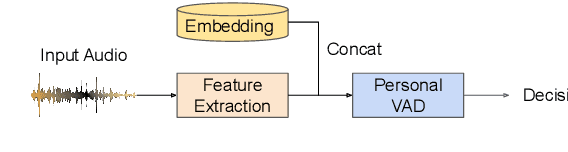
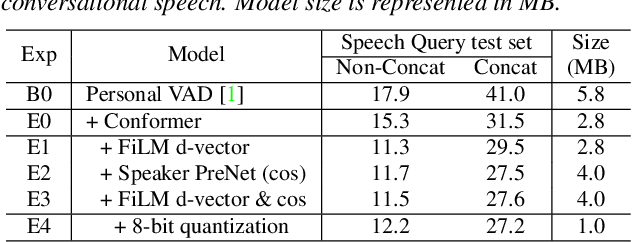
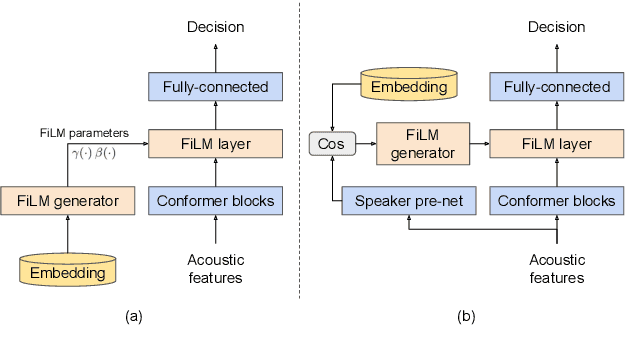
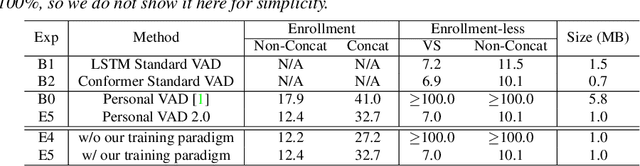
Personalization of on-device speech recognition (ASR) has seen explosive growth in recent years, largely due to the increasing popularity of personal assistant features on mobile devices and smart home speakers. In this work, we present Personal VAD 2.0, a personalized voice activity detector that detects the voice activity of a target speaker, as part of a streaming on-device ASR system. Although previous proof-of-concept studies have validated the effectiveness of Personal VAD, there are still several critical challenges to address before this model can be used in production: first, the quality must be satisfactory in both enrollment and enrollment-less scenarios; second, it should operate in a streaming fashion; and finally, the model size should be small enough to fit a limited latency and CPU/Memory budget. To meet the multi-faceted requirements, we propose a series of novel designs: 1) advanced speaker embedding modulation methods; 2) a new training paradigm to generalize to enrollment-less conditions; 3) architecture and runtime optimizations for latency and resource restrictions. Extensive experiments on a realistic speech recognition system demonstrated the state-of-the-art performance of our proposed method.
Closing the Gap between Single-User and Multi-User VoiceFilter-Lite
Feb 24, 2022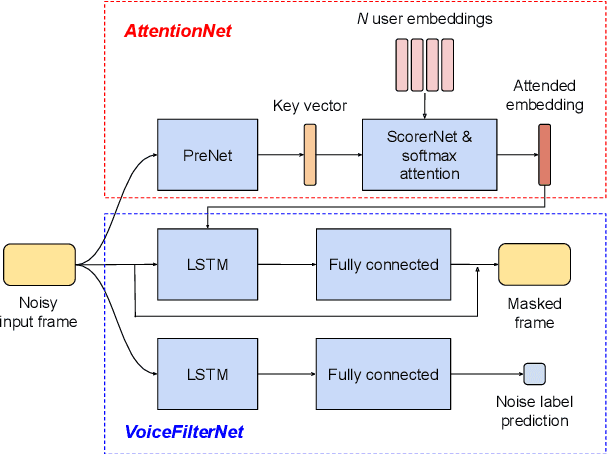
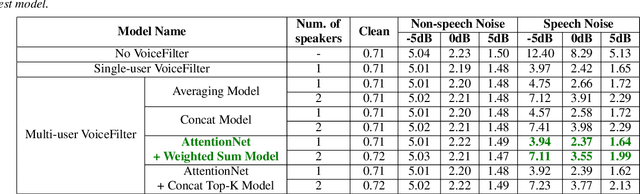
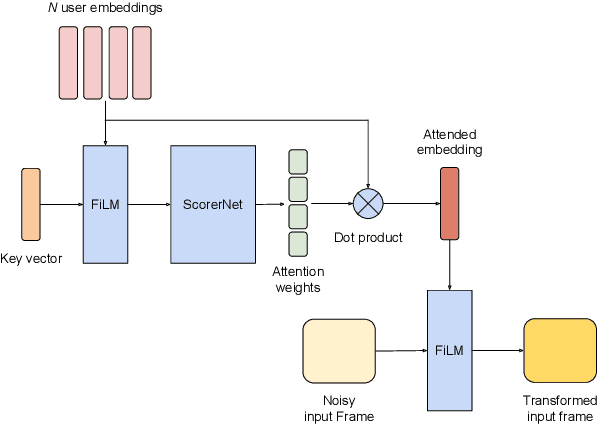
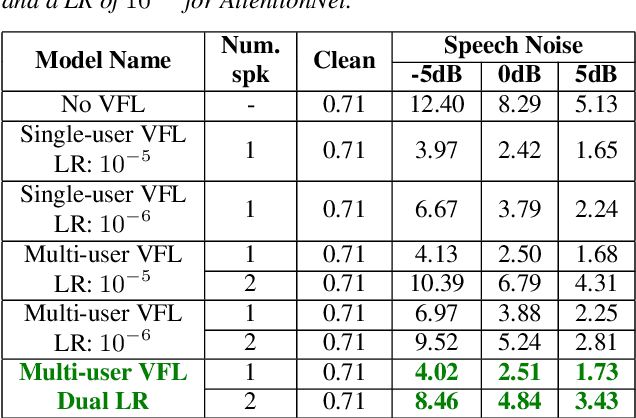
VoiceFilter-Lite is a speaker-conditioned voice separation model that plays a crucial role in improving speech recognition and speaker verification by suppressing overlapping speech from non-target speakers. However, one limitation of VoiceFilter-Lite, and other speaker-conditioned speech models in general, is that these models are usually limited to a single target speaker. This is undesirable as most smart home devices now support multiple enrolled users. In order to extend the benefits of personalization to multiple users, we previously developed an attention-based speaker selection mechanism and applied it to VoiceFilter-Lite. However, the original multi-user VoiceFilter-Lite model suffers from significant performance degradation compared with single-user models. In this paper, we devised a series of experiments to improve the multi-user VoiceFilter-Lite model. By incorporating a dual learning rate schedule and by using feature-wise linear modulation (FiLM) to condition the model with the attended speaker embedding, we successfully closed the performance gap between multi-user and single-user VoiceFilter-Lite models on single-speaker evaluations. At the same time, the new model can also be easily extended to support any number of users, and significantly outperforms our previously published model on multi-speaker evaluations.
Multi-user VoiceFilter-Lite via Attentive Speaker Embedding
Jul 02, 2021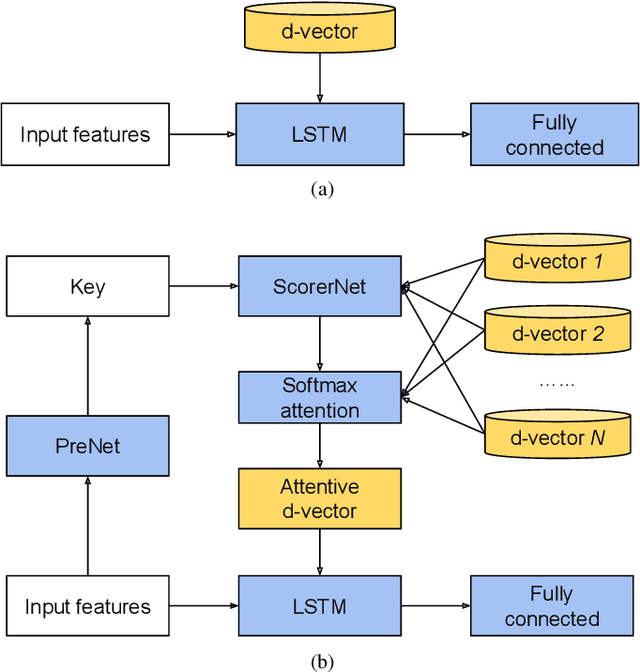
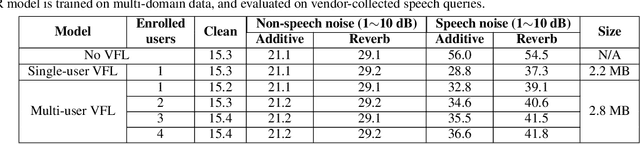
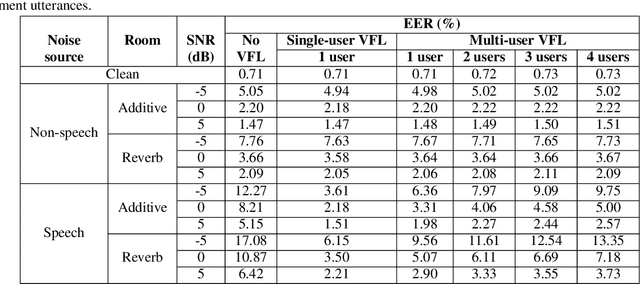
In this paper, we propose a solution to allow speaker conditioned speech models, such as VoiceFilter-Lite, to support an arbitrary number of enrolled users in a single pass. This is achieved by using an attention mechanism on multiple speaker embeddings to compute a single attentive embedding, which is then used as a side input to the model. We implemented multi-user VoiceFilter-Lite and evaluated it for three tasks: (1) a streaming automatic speech recognition (ASR) task; (2) a text-independent speaker verification task; and (3) a personalized keyphrase detection task, where ASR has to detect keyphrases from multiple enrolled users in a noisy environment. Our experiments show that, with up to four enrolled users, multi-user VoiceFilter-Lite is able to significantly reduce speech recognition and speaker verification errors when there is overlapping speech, without affecting performance under other acoustic conditions. This attentive speaker embedding approach can also be easily applied to other speaker-conditioned models such as personal VAD and personalized ASR.
Personalized Keyphrase Detection using Speaker and Environment Information
Apr 28, 2021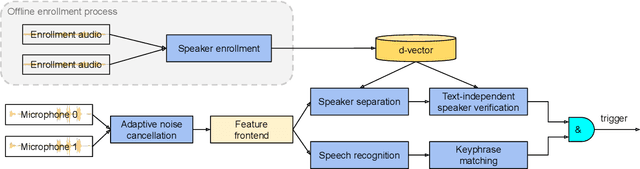
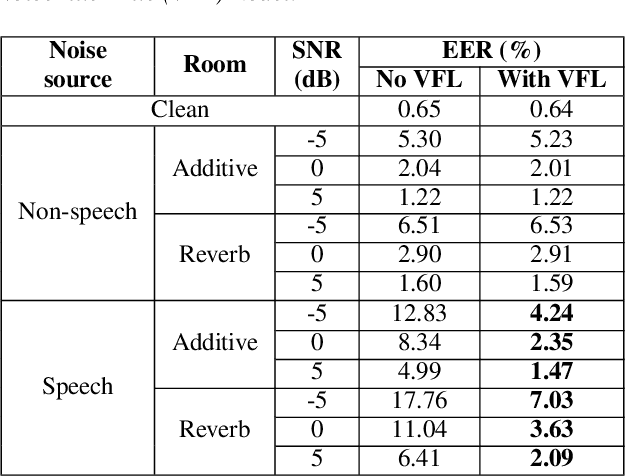
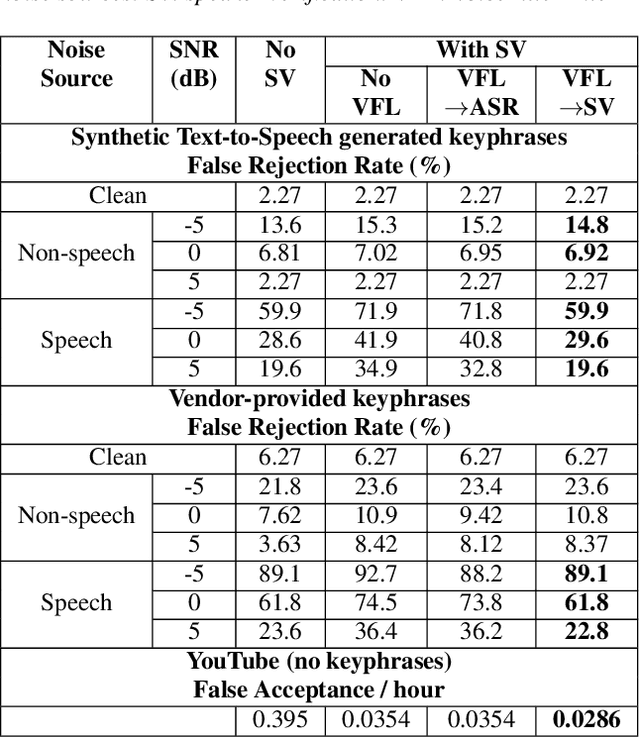
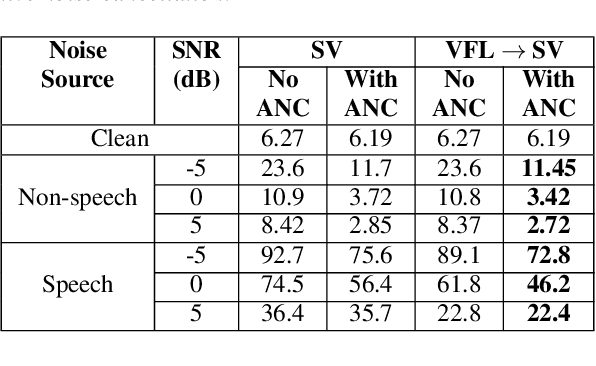
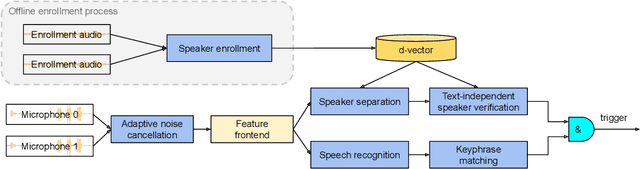
In this paper, we introduce a streaming keyphrase detection system that can be easily customized to accurately detect any phrase composed of words from a large vocabulary. The system is implemented with an end-to-end trained automatic speech recognition (ASR) model and a text-independent speaker verification model. To address the challenge of detecting these keyphrases under various noisy conditions, a speaker separation model is added to the feature frontend of the speaker verification model, and an adaptive noise cancellation (ANC) algorithm is included to exploit cross-microphone noise coherence. Our experiments show that the text-independent speaker verification model largely reduces the false triggering rate of the keyphrase detection, while the speaker separation model and adaptive noise cancellation largely reduce false rejections.