 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Aug 28, 2022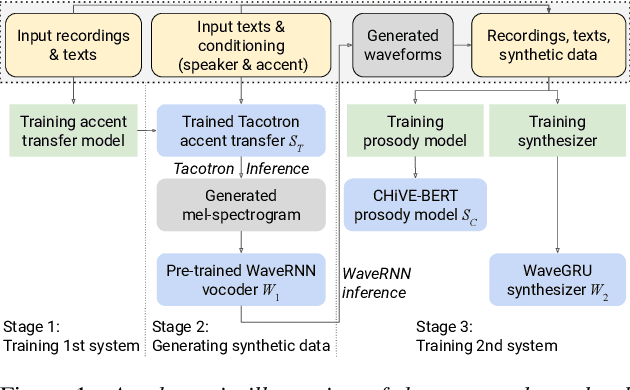
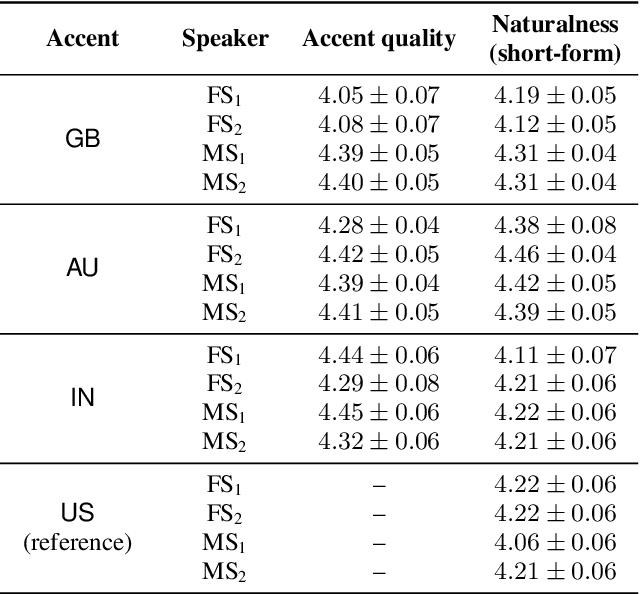
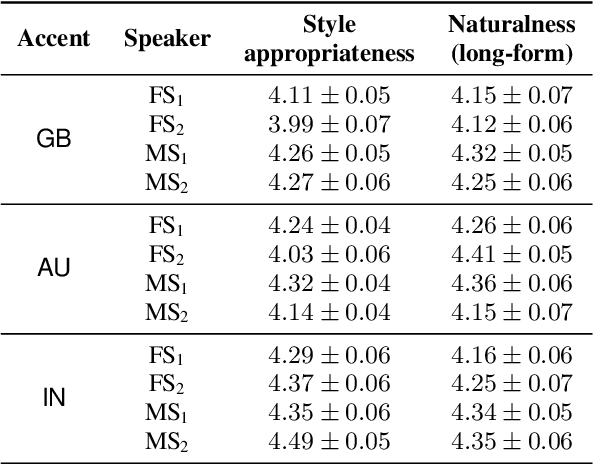
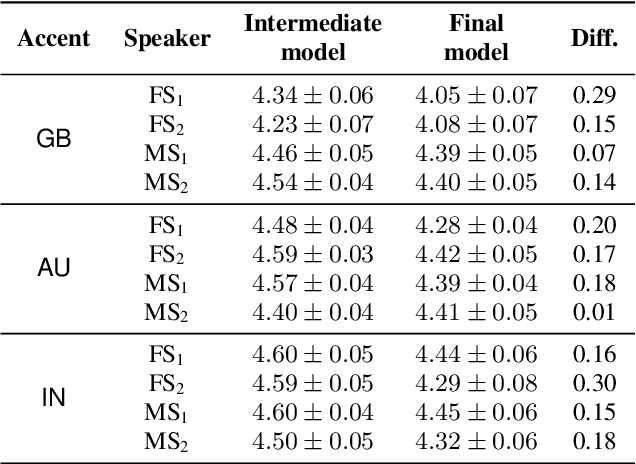
Transfer tasks in text-to-speech (TTS) synthesis - where one or more aspects of the speech of one set of speakers is transferred to another set of speakers that do not feature these aspects originally - remains a challenging task. One of the challenges is that models that have high-quality transfer capabilities can have issues in stability, making them impractical for user-facing critical tasks. This paper demonstrates that transfer can be obtained by training a robust TTS system on data generated by a less robust TTS system designed for a high-quality transfer task; in particular, a CHiVE-BERT monolingual TTS system is trained on the output of a Tacotron model designed for accent transfer. While some quality loss is inevitable with this approach, experimental results show that the models trained on synthetic data this way can produce high quality audio displaying accent transfer, while preserving speaker characteristics such as speaking style.
CHiVE: Varying Prosody in Speech Synthesis with a Linguistically Driven Dynamic Hierarchical Conditional Variational Network
Jun 04, 2019

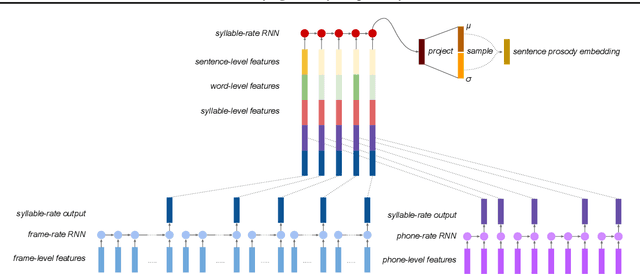

The prosodic aspects of speech signals produced by current text-to-speech systems are typically averaged over training material, and as such lack the variety and liveliness found in natural speech. To avoid monotony and averaged prosody contours, it is desirable to have a way of modeling the variation in the prosodic aspects of speech, so audio signals can be synthesized in multiple ways for a given text. We present a new, hierarchically structured conditional variational autoencoder to generate prosodic features (fundamental frequency, energy and duration) suitable for use with a vocoder or a generative model like WaveNet. At inference time, an embedding representing the prosody of a sentence may be sampled from the variational layer to allow for prosodic variation. To efficiently capture the hierarchical nature of the linguistic input (words, syllables and phones), both the encoder and decoder parts of the auto-encoder are hierarchical, in line with the linguistic structure, with layers being clocked dynamically at the respective rates. We show in our experiments that our dynamic hierarchical network outperforms a non-hierarchical state-of-the-art baseline, and, additionally, that prosody transfer across sentences is possible by employing the prosody embedding of one sentence to generate the speech signal of another.
Unsupervised Spoken Term Detection with Spoken Queries by Multi-level Acoustic Patterns with Varying Model Granularity
Sep 07, 2015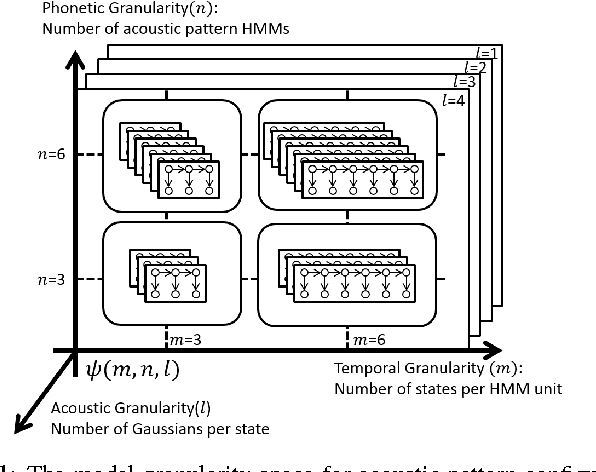
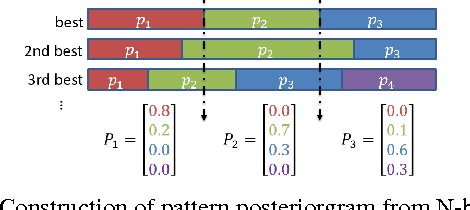
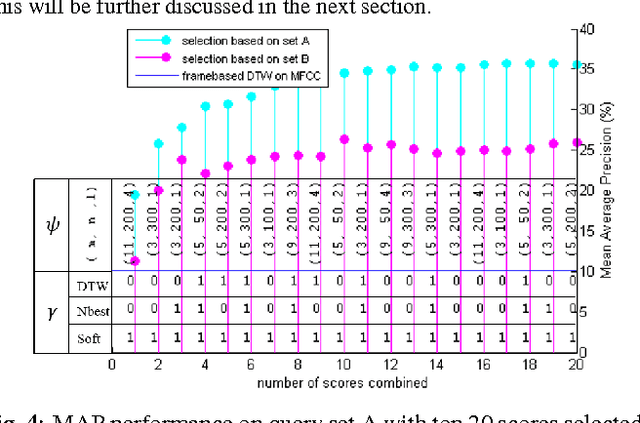
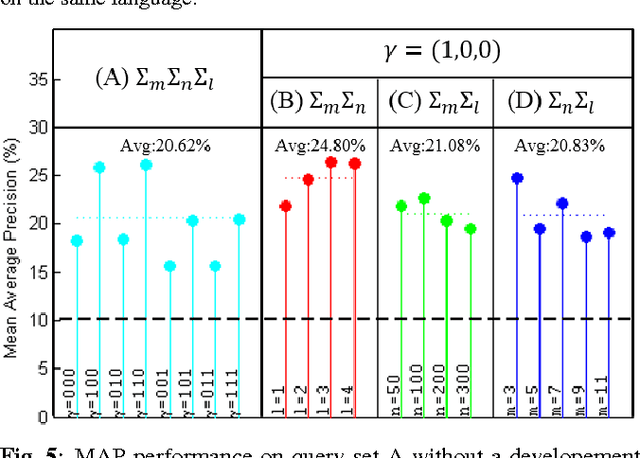
This paper presents a new approach for unsupervised Spoken Term Detection with spoken queries using multiple sets of acoustic patterns automatically discovered from the target corpus. The different pattern HMM configurations(number of states per model, number of distinct models, number of Gaussians per state)form a three-dimensional model granularity space. Different sets of acoustic patterns automatically discovered on different points properly distributed over this three-dimensional space are complementary to one another, thus can jointly capture the characteristics of the spoken terms. By representing the spoken content and spoken query as sequences of acoustic patterns, a series of approaches for matching the pattern index sequences while considering the signal variations are developed. In this way, not only the on-line computation load can be reduced, but the signal distributions caused by different speakers and acoustic conditions can be reasonably taken care of. The results indicate that this approach significantly outperformed the unsupervised feature-based DTW baseline by 16.16\% in mean average precision on the TIMIT corpus.
Unsupervised Discovery of Linguistic Structure Including Two-level Acoustic Patterns Using Three Cascaded Stages of Iterative Optimization
Sep 07, 2015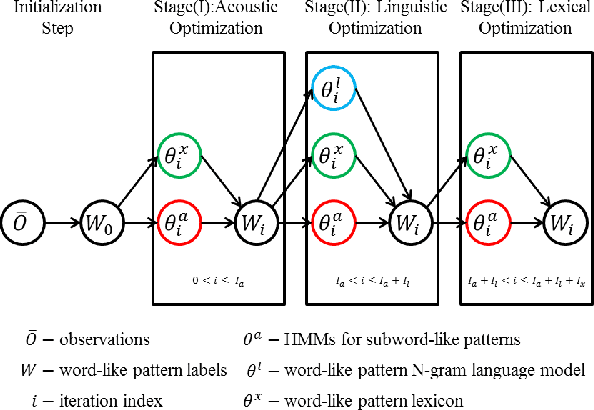
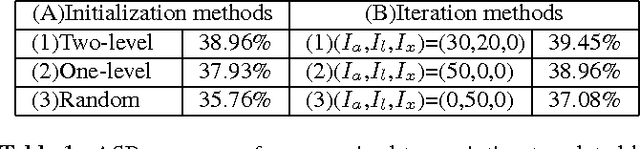
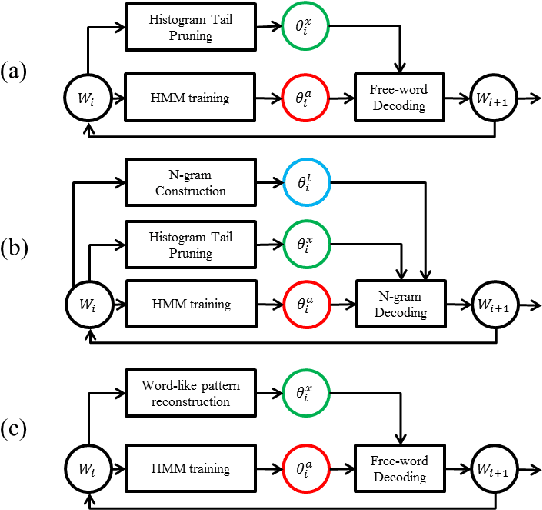

Techniques for unsupervised discovery of acoustic patterns are getting increasingly attractive, because huge quantities of speech data are becoming available but manual annotations remain hard to acquire. In this paper, we propose an approach for unsupervised discovery of linguistic structure for the target spoken language given raw speech data. This linguistic structure includes two-level (subword-like and word-like) acoustic patterns, the lexicon of word-like patterns in terms of subword-like patterns and the N-gram language model based on word-like patterns. All patterns, models, and parameters can be automatically learned from the unlabelled speech corpus. This is achieved by an initialization step followed by three cascaded stages for acoustic, linguistic, and lexical iterative optimization. The lexicon of word-like patterns defines allowed consecutive sequence of HMMs for subword-like patterns. In each iteration, model training and decoding produces updated labels from which the lexicon and HMMs can be further updated. In this way, model parameters and decoded labels are respectively optimized in each iteration, and the knowledge about the linguistic structure is learned gradually layer after layer. The proposed approach was tested in preliminary experiments on a corpus of Mandarin broadcast news, including a task of spoken term detection with performance compared to a parallel test using models trained in a supervised way. Results show that the proposed system not only yields reasonable performance on its own, but is also complimentary to existing large vocabulary ASR systems.