 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Spoken Term Detection with Spoken Queries by Multi-level Acoustic Patterns with Varying Model Granularity
Paper and Code
Sep 07, 2015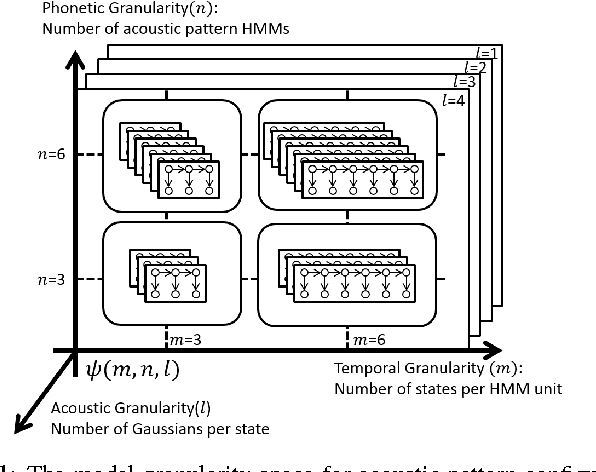
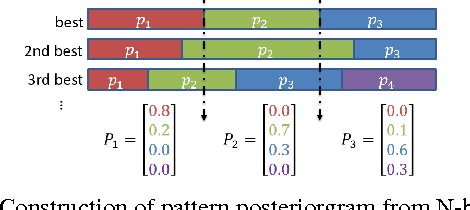
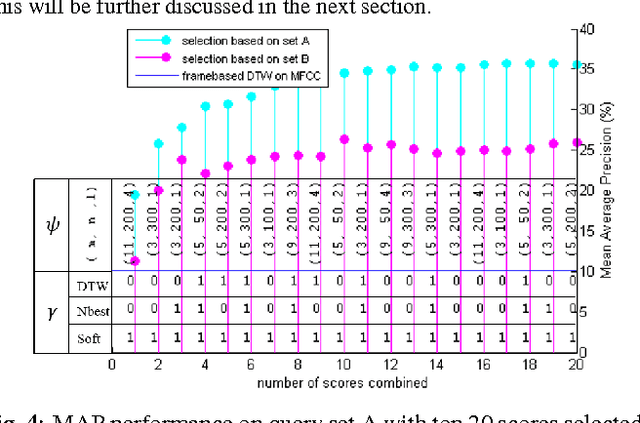
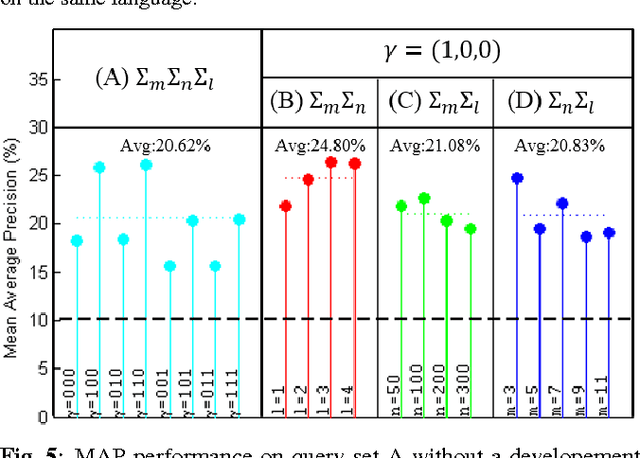
This paper presents a new approach for unsupervised Spoken Term Detection with spoken queries using multiple sets of acoustic patterns automatically discovered from the target corpus. The different pattern HMM configurations(number of states per model, number of distinct models, number of Gaussians per state)form a three-dimensional model granularity space. Different sets of acoustic patterns automatically discovered on different points properly distributed over this three-dimensional space are complementary to one another, thus can jointly capture the characteristics of the spoken terms. By representing the spoken content and spoken query as sequences of acoustic patterns, a series of approaches for matching the pattern index sequences while considering the signal variations are developed. In this way, not only the on-line computation load can be reduced, but the signal distributions caused by different speakers and acoustic conditions can be reasonably taken care of. The results indicate that this approach significantly outperformed the unsupervised feature-based DTW baseline by 16.16\% in mean average precision on the TIMIT corpus.