 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Linguistic Structure Including Two-level Acoustic Patterns Using Three Cascaded Stages of Iterative Optimization
Paper and Code
Sep 07, 2015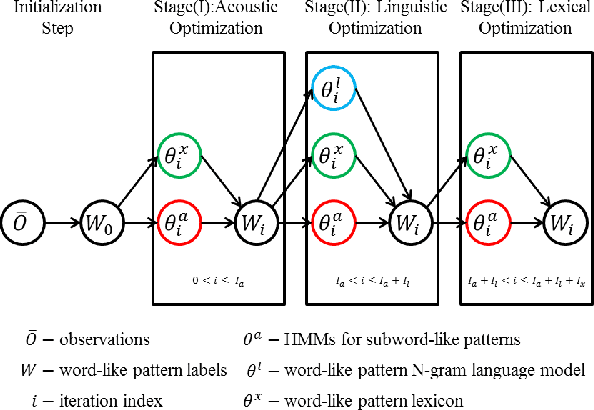
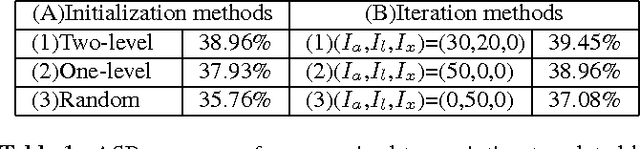
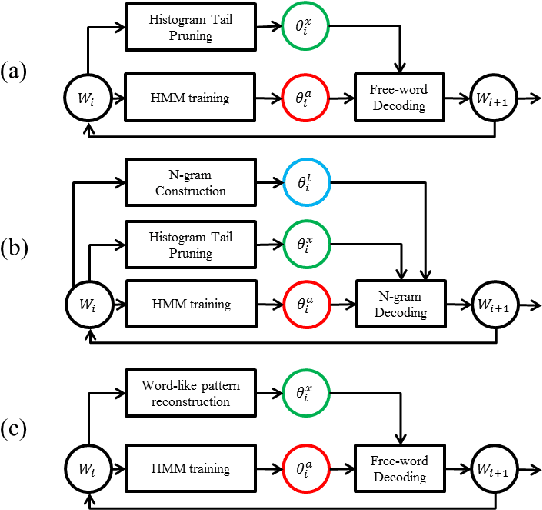

Techniques for unsupervised discovery of acoustic patterns are getting increasingly attractive, because huge quantities of speech data are becoming available but manual annotations remain hard to acquire. In this paper, we propose an approach for unsupervised discovery of linguistic structure for the target spoken language given raw speech data. This linguistic structure includes two-level (subword-like and word-like) acoustic patterns, the lexicon of word-like patterns in terms of subword-like patterns and the N-gram language model based on word-like patterns. All patterns, models, and parameters can be automatically learned from the unlabelled speech corpus. This is achieved by an initialization step followed by three cascaded stages for acoustic, linguistic, and lexical iterative optimization. The lexicon of word-like patterns defines allowed consecutive sequence of HMMs for subword-like patterns. In each iteration, model training and decoding produces updated labels from which the lexicon and HMMs can be further updated. In this way, model parameters and decoded labels are respectively optimized in each iteration, and the knowledge about the linguistic structure is learned gradually layer after layer. The proposed approach was tested in preliminary experiments on a corpus of Mandarin broadcast news, including a task of spoken term detection with performance compared to a parallel test using models trained in a supervised way. Results show that the proposed system not only yields reasonable performance on its own, but is also complimentary to existing large vocabulary ASR systems.