 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the quantization of recurrent neural networks
Paper and Code
Jan 14, 2021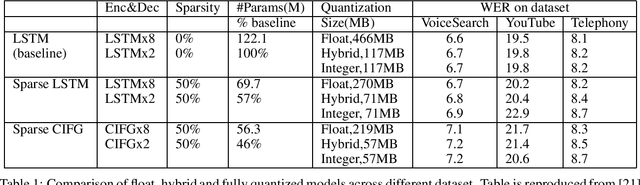
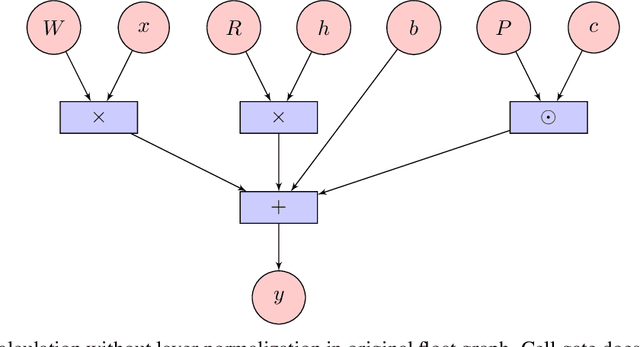
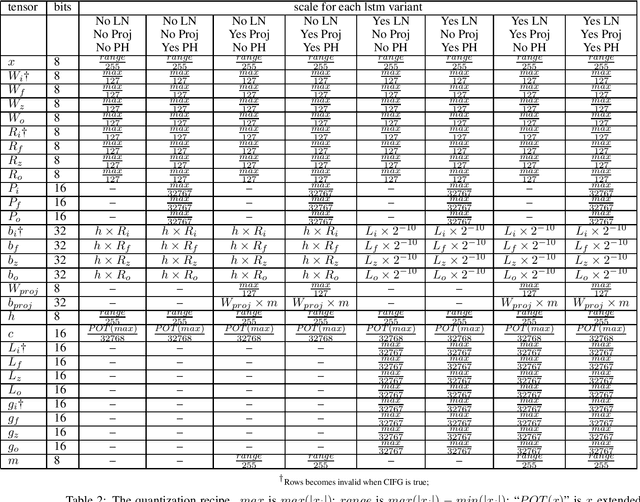
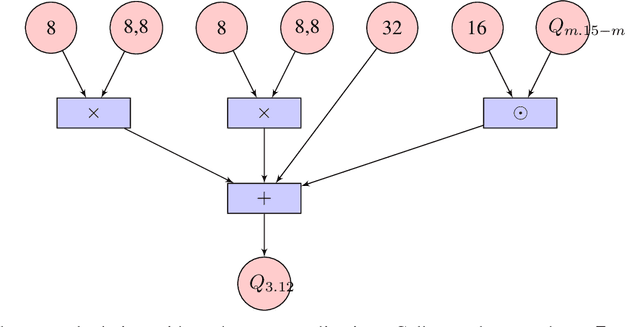
Integer quantization of neural networks can be defined as the approximation of the high precision computation of the canonical neural network formulation, using reduced integer precision. It plays a significant role in the efficient deployment and execution of machine learning (ML) systems, reducing memory consumption and leveraging typically faster computations. In this work, we present an integer-only quantization strategy for Long Short-Term Memory (LSTM) neural network topologies, which themselves are the foundation of many production ML systems. Our quantization strategy is accurate (e.g. works well with quantization post-training), efficient and fast to execute (utilizing 8 bit integer weights and mostly 8 bit activations), and is able to target a variety of hardware (by leveraging instructions sets available in common CPU architectures, as well as available neural accelerators).