 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Speech Recognition For The Edge
Paper and Code
Sep 26, 2019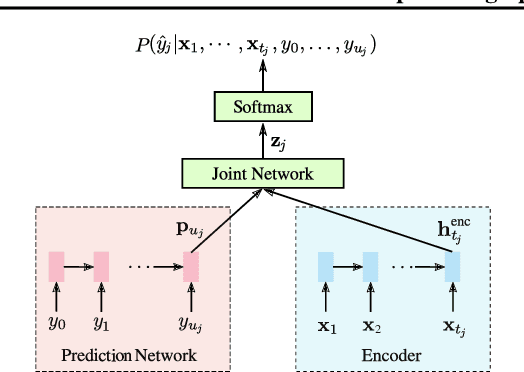



While most deployed speech recognition systems today still run on servers, we are in the midst of a transition towards deployments on edge devices. This leap to the edge is powered by the progression from traditional speech recognition pipelines to end-to-end (E2E) neural architectures, and the parallel development of more efficient neural network topologies and optimization techniques. Thus, we are now able to create highly accurate speech recognizers that are both small and fast enough to execute on typical mobile devices. In this paper, we begin with a baseline RNN-Transducer architecture comprised of Long Short-Term Memory (LSTM) layers. We then experiment with a variety of more computationally efficient layer types, as well as apply optimization techniques like neural connection pruning and parameter quantization to construct a small, high quality, on-device speech recognizer that is an order of magnitude smaller than the baseline system without any optimizations.