Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal Combination for Language Identification
Nov 04, 2019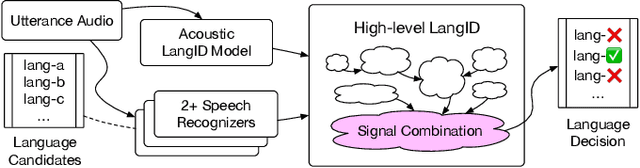


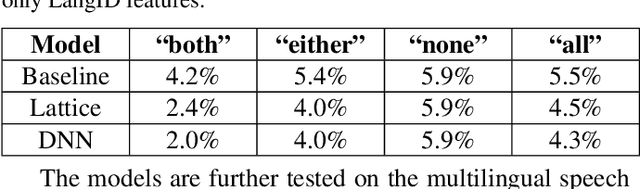
Google's multilingual speech recognition system combines low-level acoustic signals with language-specific recognizer signals to better predict the language of an utterance. This paper presents our experience with different signal combination methods to improve overall language identification accuracy. We compare the performance of a lattice-based ensemble model and a deep neural network model to combine signals from recognizers with that of a baseline that only uses low-level acoustic signals. Experimental results show that the deep neural network model outperforms the lattice-based ensemble model, and it reduced the error rate from 5.5% in the baseline to 4.3%, which is a 21.8% relative reduction.
Via