 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPET-SPK: A Unified Framework for Parameter-Efficient Tuning of Pre-trained Speech Models for Robust Speaker Verification
Jan 27, 2025With excellent generalization ability, SSL speech models have shown impressive performance on various downstream tasks in the pre-training and fine-tuning paradigm. However, as the size of pre-trained models grows, fine-tuning becomes practically unfeasible due to expanding computation and storage requirements and the risk of overfitting. This study explores parameter-efficient tuning (PET) methods for adapting large-scale pre-trained SSL speech models to speaker verification task. Correspondingly, we propose three PET methods: (i)an adapter-tuning method, (ii)a prompt-tuning method, and (iii)a unified framework that effectively incorporates adapter-tuning and prompt-tuning with a dynamically learnable gating mechanism. First, we propose the Inner+Inter Adapter framework, which inserts two types of adapters into pre-trained models, allowing for adaptation of latent features within the intermediate Transformer layers and output embeddings from all Transformer layers, through a parallel adapter design. Second, we propose the Deep Speaker Prompting method that concatenates trainable prompt tokens into the input space of pre-trained models to guide adaptation. Lastly, we propose the UniPET-SPK, a unified framework that effectively incorporates these two alternate PET methods into a single framework with a dynamic trainable gating mechanism. The proposed UniPET-SPK learns to find the optimal mixture of PET methods to match different datasets and scenarios. We conduct a comprehensive set of experiments on several datasets to validate the effectiveness of the proposed PET methods. Experimental results on VoxCeleb, CN-Celeb, and 1st 48-UTD forensic datasets demonstrate that the proposed UniPET-SPK consistently outperforms the two PET methods, fine-tuning, and other parameter-efficient tuning methods, achieving superior performance while updating only 5.4% of the parameters.
Efficient Adapter Tuning of Pre-trained Speech Models for Automatic Speaker Verification
Mar 01, 2024



With excellent generalization ability, self-supervised speech models have shown impressive performance on various downstream speech tasks in the pre-training and fine-tuning paradigm. However, as the growing size of pre-trained models, fine-tuning becomes practically unfeasible due to heavy computation and storage overhead, as well as the risk of overfitting. Adapters are lightweight modules inserted into pre-trained models to facilitate parameter-efficient adaptation. In this paper, we propose an effective adapter framework designed for adapting self-supervised speech models to the speaker verification task. With a parallel adapter design, our proposed framework inserts two types of adapters into the pre-trained model, allowing the adaptation of latent features within intermediate Transformer layers and output embeddings from all Transformer layers. We conduct comprehensive experiments to validate the efficiency and effectiveness of the proposed framework. Experimental results on the VoxCeleb1 dataset demonstrate that the proposed adapters surpass fine-tuning and other parameter-efficient transfer learning methods, achieving superior performance while updating only 5% of the parameters.
Improving Transformer-based Networks With Locality For Automatic Speaker Verification
Feb 28, 2023

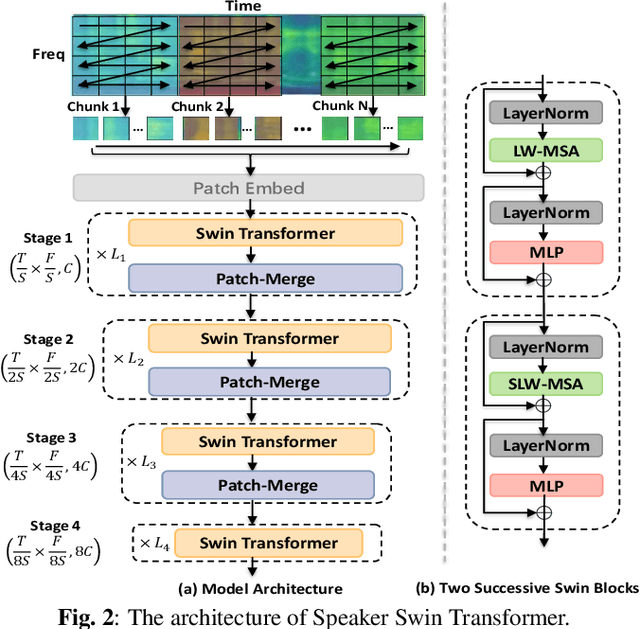

Recently, Transformer-based architectures have been explored for speaker embedding extraction. Although the Transformer employs the self-attention mechanism to efficiently model the global interaction between token embeddings, it is inadequate for capturing short-range local context, which is essential for the accurate extraction of speaker information. In this study, we enhance the Transformer with the enhanced locality modeling in two directions. First, we propose the Locality-Enhanced Conformer (LE-Confomer) by introducing depth-wise convolution and channel-wise attention into the Conformer blocks. Second, we present the Speaker Swin Transformer (SST) by adapting the Swin Transformer, originally proposed for vision tasks, into speaker embedding network. We evaluate the proposed approaches on the VoxCeleb datasets and a large-scale Microsoft internal multilingual (MS-internal) dataset. The proposed models achieve 0.75% EER on VoxCeleb 1 test set, outperforming the previously proposed Transformer-based models and CNN-based models, such as ResNet34 and ECAPA-TDNN. When trained on the MS-internal dataset, the proposed models achieve promising results with 14.6% relative reduction in EER over the Res2Net50 model.
Multi-Frequency Information Enhanced Channel Attention Module for Speaker Representation Learning
Jul 10, 2022
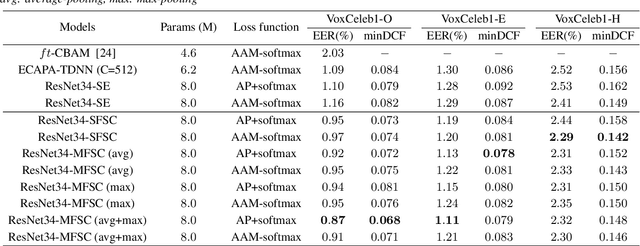
Recently, attention mechanisms have been applied successfully in neural network-based speaker verification systems. Incorporating the Squeeze-and-Excitation block into convolutional neural networks has achieved remarkable performance. However, it uses global average pooling (GAP) to simply average the features along time and frequency dimensions, which is incapable of preserving sufficient speaker information in the feature maps. In this study, we show that GAP is a special case of a discrete cosine transform (DCT) on time-frequency domain mathematically using only the lowest frequency component in frequency decomposition. To strengthen the speaker information extraction ability, we propose to utilize multi-frequency information and design two novel and effective attention modules, called Single-Frequency Single-Channel (SFSC) attention module and Multi-Frequency Single-Channel (MFSC) attention module. The proposed attention modules can effectively capture more speaker information from multiple frequency components on the basis of DCT. We conduct comprehensive experiments on the VoxCeleb datasets and a probe evaluation on the 1st 48-UTD forensic corpus. Experimental results demonstrate that our proposed SFSC and MFSC attention modules can efficiently generate more discriminative speaker representations and outperform ResNet34-SE and ECAPA-TDNN systems with relative 20.9% and 20.2% reduction in EER, without adding extra network parameters.
Self-Supervised Speaker Verification with Simple Siamese Network and Self-Supervised Regularization
Dec 08, 2021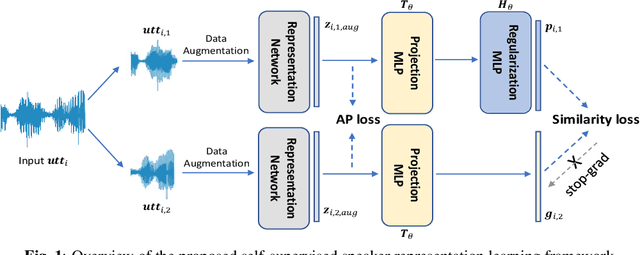

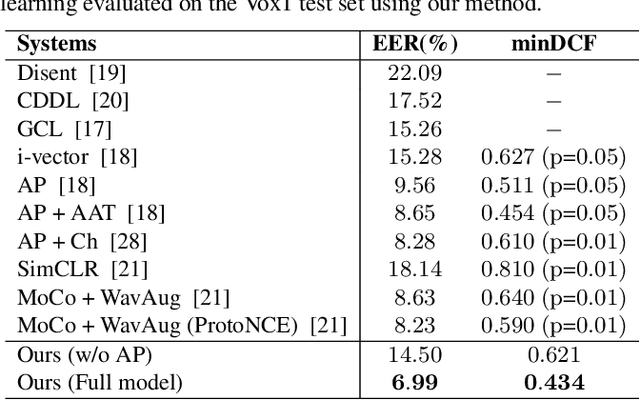

Training speaker-discriminative and robust speaker verification systems without speaker labels is still challenging and worthwhile to explore. In this study, we propose an effective self-supervised learning framework and a novel regularization strategy to facilitate self-supervised speaker representation learning. Different from contrastive learning-based self-supervised learning methods, the proposed self-supervised regularization (SSReg) focuses exclusively on the similarity between the latent representations of positive data pairs. We also explore the effectiveness of alternative online data augmentation strategies on both the time domain and frequency domain. With our strong online data augmentation strategy, the proposed SSReg shows the potential of self-supervised learning without using negative pairs and it can significantly improve the performance of self-supervised speaker representation learning with a simple Siamese network architecture. Comprehensive experiments on the VoxCeleb datasets demonstrate that our proposed self-supervised approach obtains a 23.4% relative improvement by adding the effective self-supervised regularization and outperforms other previous works.
DEAAN: Disentangled Embedding and Adversarial Adaptation Network for Robust Speaker Representation Learning
Dec 12, 2020

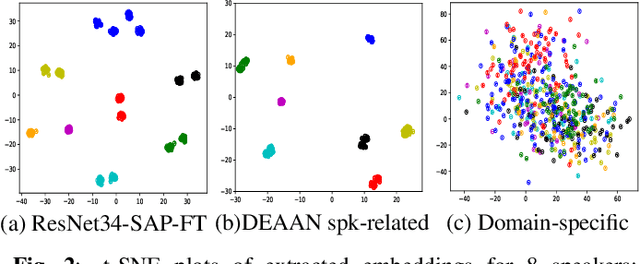
Despite speaker verification has achieved significant performance improvement with the development of deep neural networks, domain mismatch is still a challenging problem in this field. In this study, we propose a novel framework to disentangle speaker-related and domain-specific features and apply domain adaptation on the speaker-related feature space solely. Instead of performing domain adaptation directly on the feature space where domain information is not removed, using disentanglement can efficiently boost adaptation performance. To be specific, our model's input speech from the source and target domains is first encoded into different latent feature spaces. The adversarial domain adaptation is conducted on the shared speaker-related feature space to encourage the property of domain-invariance. Further, we minimize the mutual information between speaker-related and domain-specific features for both domains to enforce the disentanglement. Experimental results on the VOiCES dataset demonstrate that our proposed framework can effectively generate more speaker-discriminative and domain-invariant speaker representations with a relative 20.3% reduction of EER compared to the original ResNet-based system.
Open-set Short Utterance Forensic Speaker Verification using Teacher-Student Network with Explicit Inductive Bias
Sep 21, 2020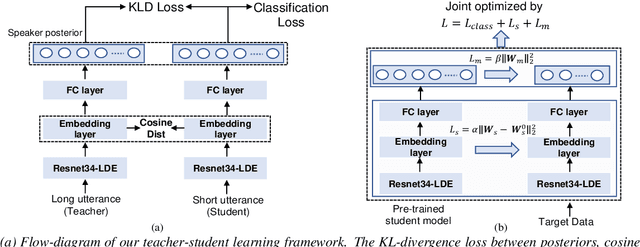

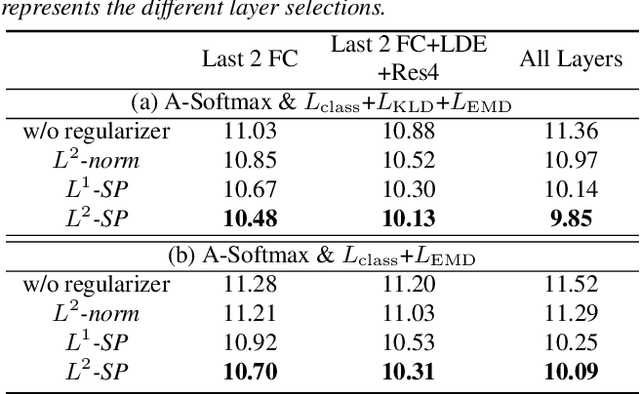
In forensic applications, it is very common that only small naturalistic datasets consisting of short utterances in complex or unknown acoustic environments are available. In this study, we propose a pipeline solution to improve speaker verification on a small actual forensic field dataset. By leveraging large-scale out-of-domain datasets, a knowledge distillation based objective function is proposed for teacher-student learning, which is applied for short utterance forensic speaker verification. The objective function collectively considers speaker classification loss, Kullback-Leibler divergence, and similarity of embeddings. In order to advance the trained deep speaker embedding network to be robust for a small target dataset, we introduce a novel strategy to fine-tune the pre-trained student model towards a forensic target domain by utilizing the model as a finetuning start point and a reference in regularization. The proposed approaches are evaluated on the 1st48-UTD forensic corpus, a newly established naturalistic dataset of actual homicide investigations consisting of short utterances recorded in uncontrolled conditions. We show that the proposed objective function can efficiently improve the performance of teacher-student learning on short utterances and that our fine-tuning strategy outperforms the commonly used weight decay method by providing an explicit inductive bias towards the pre-trained model.