 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAAN: Disentangled Embedding and Adversarial Adaptation Network for Robust Speaker Representation Learning
Paper and Code
Dec 12, 2020

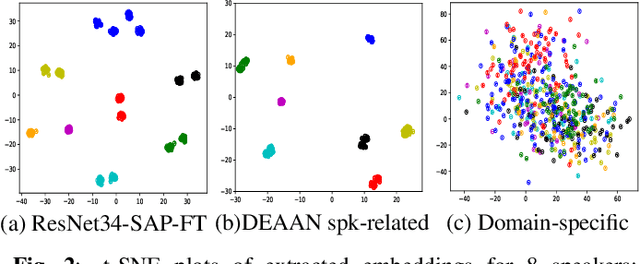
Despite speaker verification has achieved significant performance improvement with the development of deep neural networks, domain mismatch is still a challenging problem in this field. In this study, we propose a novel framework to disentangle speaker-related and domain-specific features and apply domain adaptation on the speaker-related feature space solely. Instead of performing domain adaptation directly on the feature space where domain information is not removed, using disentanglement can efficiently boost adaptation performance. To be specific, our model's input speech from the source and target domains is first encoded into different latent feature spaces. The adversarial domain adaptation is conducted on the shared speaker-related feature space to encourage the property of domain-invariance. Further, we minimize the mutual information between speaker-related and domain-specific features for both domains to enforce the disentanglement. Experimental results on the VOiCES dataset demonstrate that our proposed framework can effectively generate more speaker-discriminative and domain-invariant speaker representations with a relative 20.3% reduction of EER compared to the original ResNet-based system.