 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling the Alignment for Wake Word Detection: A Comparison Between Alignment-Based, Alignment-Free and Hybrid Approaches
Paper and Code
Feb 17, 2023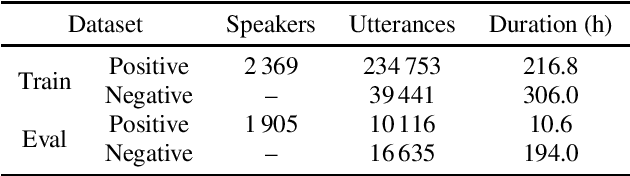
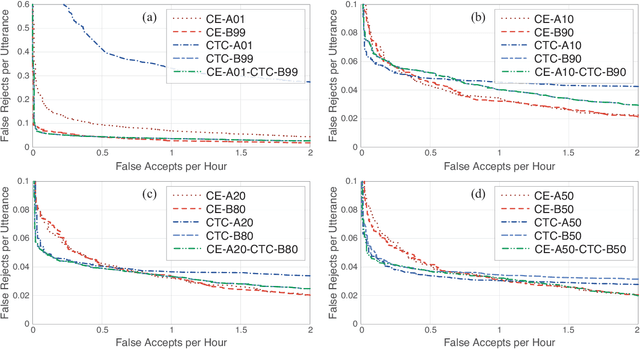
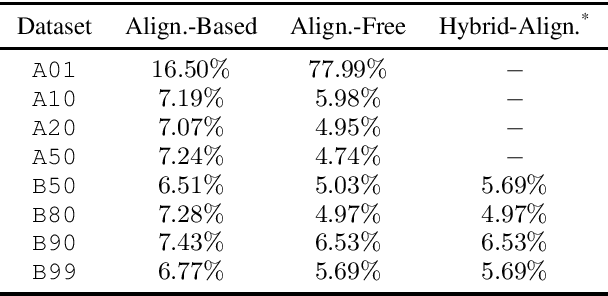

Wake word detection exists in most intelligent homes and portable devices. It offers these devices the ability to "wake up" when summoned at a low cost of power and computing. This paper focuses on understanding alignment's role in developing a wake-word system that answers a generic phrase. We discuss three approaches. The first is alignment-based, where the model is trained with frame-wise cross-entropy. The second is alignment-free, where the model is trained with CTC. The third, proposed by us, is a hybrid solution in which the model is trained with a small set of aligned data and then tuned with a sizeable unaligned dataset. We compare the three approaches and evaluate the impact of the different aligned-to-unaligned ratios for hybrid training. Our results show that the alignment-free system performs better alignment-based for the target operating point, and with a small fraction of the data (20%), we can train a model that complies with our initial constraints.