 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Audio-Visual Noise Suppression
Paper and Code
Nov 07, 2022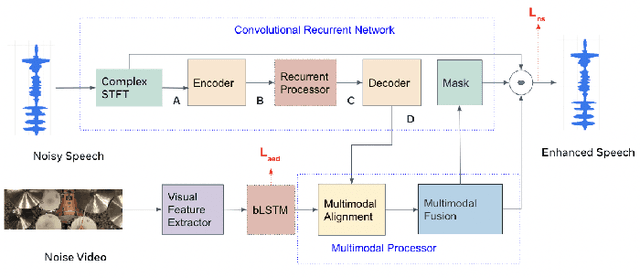
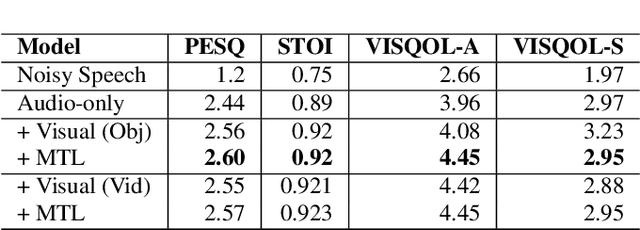
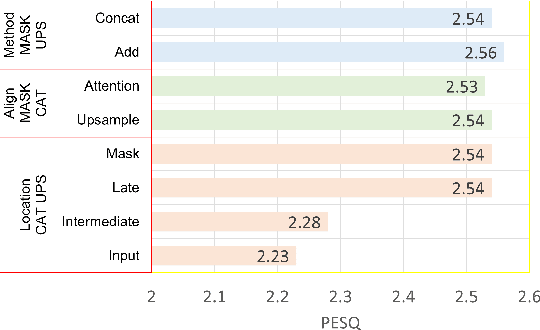

This paper studies audio-visual suppression for egocentric videos -- where the speaker is not captured in the video. Instead, potential noise sources are visible on screen with the camera emulating the off-screen speaker's view of the outside world. This setting is different from prior work in audio-visual speech enhancement that relies on lip and facial visuals. In this paper, we first demonstrate that egocentric visual information is helpful for noise suppression. We compare object recognition and action classification based visual feature extractors, and investigate methods to align audio and visual representations. Then, we examine different fusion strategies for the aligned features, and locations within the noise suppression model to incorporate visual information. Experiments demonstrate that visual features are most helpful when used to generate additive correction masks. Finally, in order to ensure that the visual features are discriminative with respect to different noise types, we introduce a multi-task learning framework that jointly optimizes audio-visual noise suppression and video based acoustic event detection. This proposed multi-task framework outperforms the audio only baseline on all metrics, including a 0.16 PESQ improvement. Extensive ablations reveal the improved performance of the proposed model with multiple active distractors, over all noise types and across different SNRs.