Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconsideration on evaluation of machine learning models in continuous monitoring using wearables
Paper and Code
Dec 04, 2023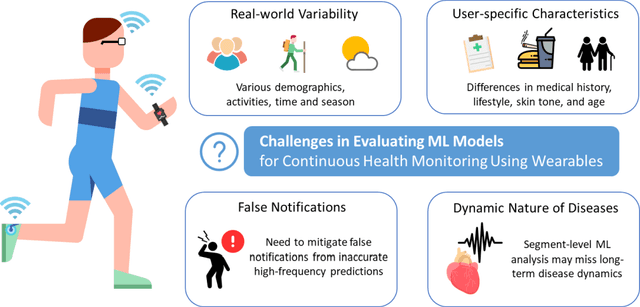
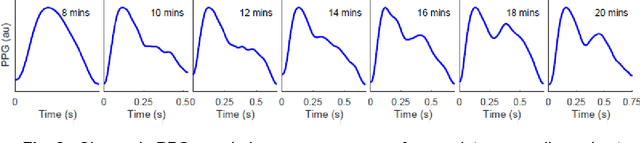

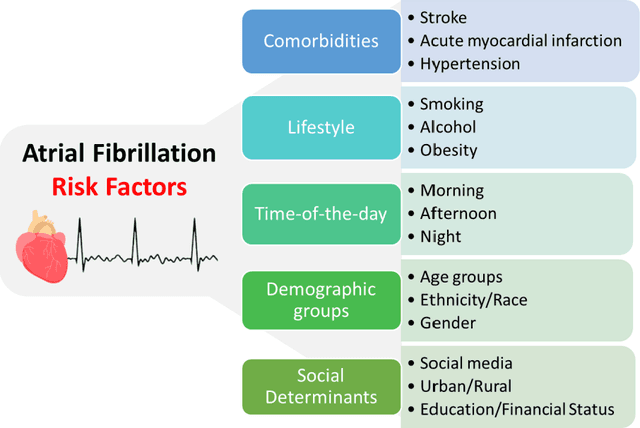
This paper explores the challenges in evaluating machine learning (ML) models for continuous health monitoring using wearable devices beyond conventional metrics. We state the complexities posed by real-world variability, disease dynamics, user-specific characteristics, and the prevalence of false notifications, necessitating novel evaluation strategies. Drawing insights from large-scale heart studies, the paper offers a comprehensive guideline for robust ML model evaluation on continuous health monitoring.
View paper on