 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralist vs Specialist Time Series Foundation Models: Investigating Potential Emergent Behaviors in Assessing Human Health Using PPG Signals
Oct 16, 2025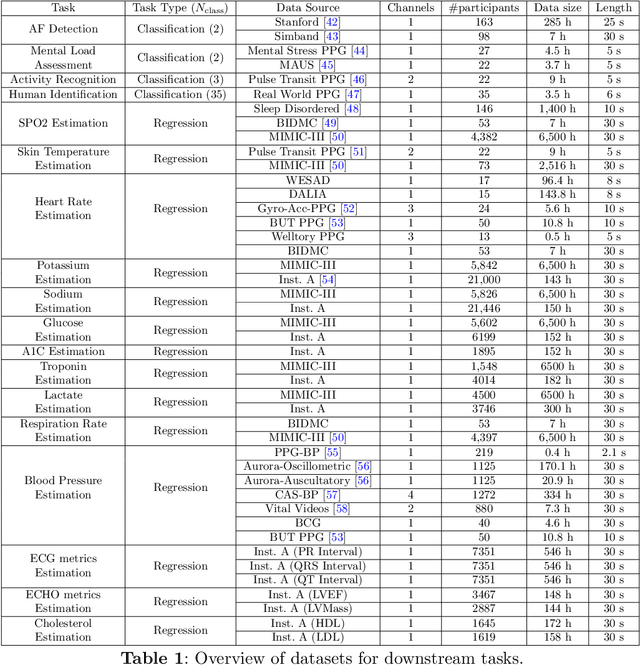
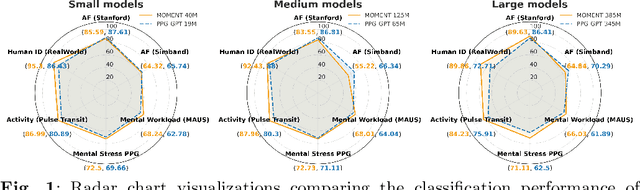
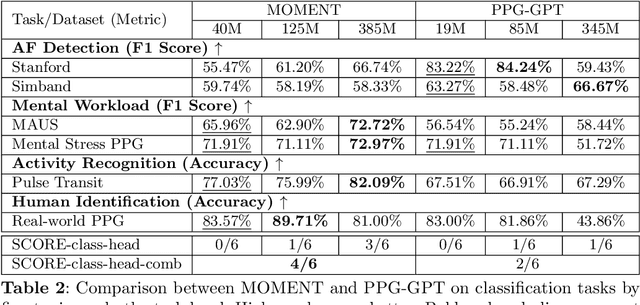
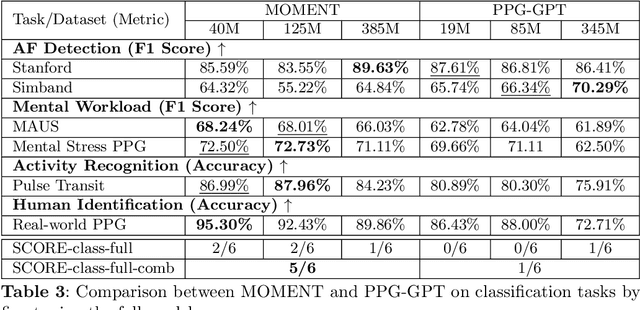
Foundation models are large-scale machine learning models that are pre-trained on massive amounts of data and can be adapted for various downstream tasks. They have been extensively applied to tasks in Natural Language Processing and Computer Vision with models such as GPT, BERT, and CLIP. They are now also increasingly gaining attention in time-series analysis, particularly for physiological sensing. However, most time series foundation models are specialist models - with data in pre-training and testing of the same type, such as Electrocardiogram, Electroencephalogram, and Photoplethysmogram (PPG). Recent works, such as MOMENT, train a generalist time series foundation model with data from multiple domains, such as weather, traffic, and electricity. This paper aims to conduct a comprehensive benchmarking study to compare the performance of generalist and specialist models, with a focus on PPG signals. Through an extensive suite of total 51 tasks covering cardiac state assessment, laboratory value estimation, and cross-modal inference, we comprehensively evaluate both models across seven dimensions, including win score, average performance, feature quality, tuning gain, performance variance, transferability, and scalability. These metrics jointly capture not only the models' capability but also their adaptability, robustness, and efficiency under different fine-tuning strategies, providing a holistic understanding of their strengths and limitations for diverse downstream scenarios. In a full-tuning scenario, we demonstrate that the specialist model achieves a 27% higher win score. Finally, we provide further analysis on generalization, fairness, attention visualizations, and the importance of training data choice.
PLANET: A Collection of Benchmarks for Evaluating LLMs' Planning Capabilities
Apr 21, 2025Planning is central to agents and agentic AI. The ability to plan, e.g., creating travel itineraries within a budget, holds immense potential in both scientific and commercial contexts. Moreover, optimal plans tend to require fewer resources compared to ad-hoc methods. To date, a comprehensive understanding of existing planning benchmarks appears to be lacking. Without it, comparing planning algorithms' performance across domains or selecting suitable algorithms for new scenarios remains challenging. In this paper, we examine a range of planning benchmarks to identify commonly used testbeds for algorithm development and highlight potential gaps. These benchmarks are categorized into embodied environments, web navigation, scheduling, games and puzzles, and everyday task automation. Our study recommends the most appropriate benchmarks for various algorithms and offers insights to guide future benchmark development.
GPT-PPG: A GPT-based Foundation Model for Photoplethysmography Signals
Mar 11, 2025This study introduces a novel application of a Generative Pre-trained Transformer (GPT) model tailored for photoplethysmography (PPG) signals, serving as a foundation model for various downstream tasks. Adapting the standard GPT architecture to suit the continuous characteristics of PPG signals, our approach demonstrates promising results. Our models are pre-trained on our extensive dataset that contains more than 200 million 30s PPG samples. We explored different supervised fine-tuning techniques to adapt our model to downstream tasks, resulting in performance comparable to or surpassing current state-of-the-art (SOTA) methods in tasks like atrial fibrillation detection. A standout feature of our GPT model is its inherent capability to perform generative tasks such as signal denoising effectively, without the need for further fine-tuning. This success is attributed to the generative nature of the GPT framework.
Systematic Analysis of LLM Contributions to Planning: Solver, Verifier, Heuristic
Dec 12, 2024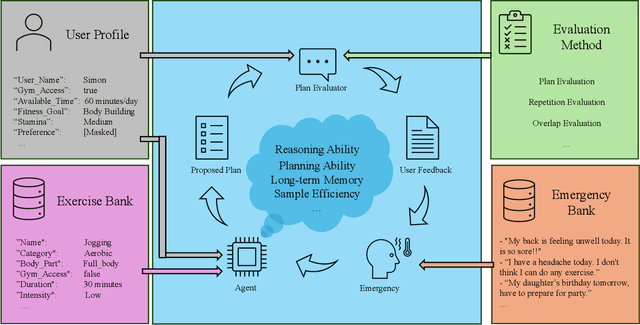
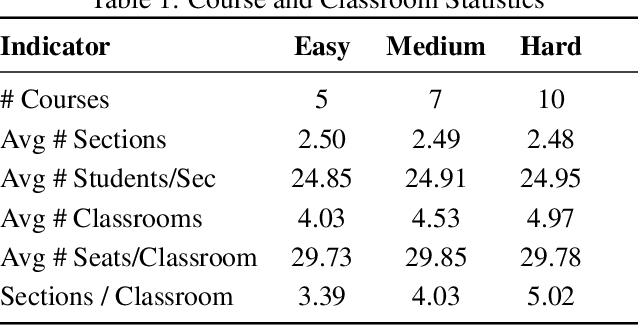
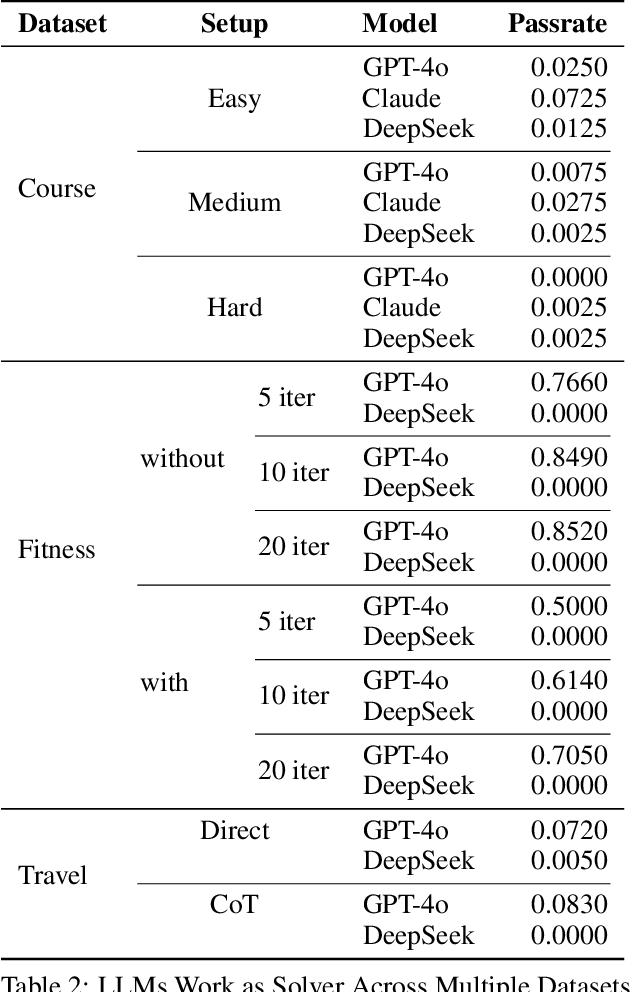
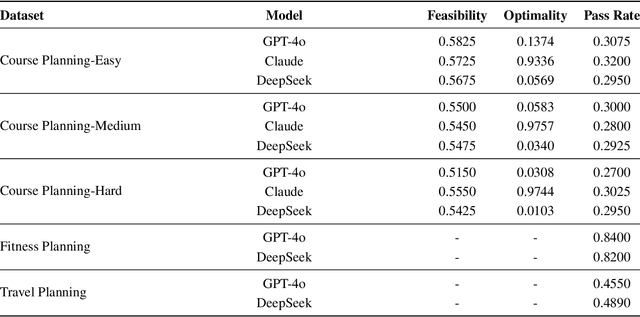
In this work, we provide a systematic analysis of how large language models (LLMs) contribute to solving planning problems. In particular, we examine how LLMs perform when they are used as problem solver, solution verifier, and heuristic guidance to improve intermediate solutions. Our analysis reveals that although it is difficult for LLMs to generate correct plans out-of-the-box, LLMs are much better at providing feedback signals to intermediate/incomplete solutions in the form of comparative heuristic functions. This evaluation framework provides insights into how future work may design better LLM-based tree-search algorithms to solve diverse planning and reasoning problems. We also propose a novel benchmark to evaluate LLM's ability to learn user preferences on the fly, which has wide applications in practical settings.
LASP: Surveying the State-of-the-Art in Large Language Model-Assisted AI Planning
Sep 03, 2024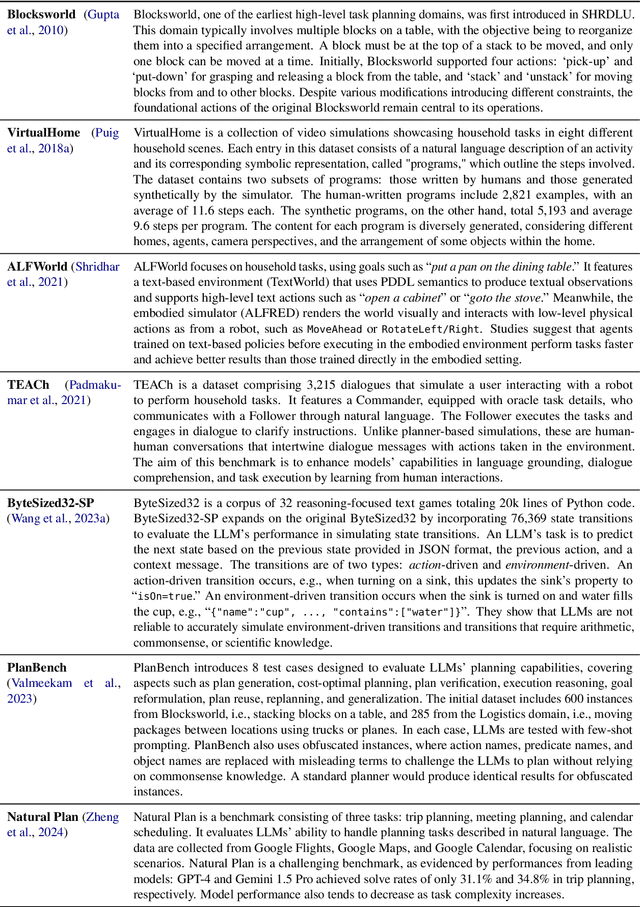
Effective planning is essential for the success of any task, from organizing a vacation to routing autonomous vehicles and developing corporate strategies. It involves setting goals, formulating plans, and allocating resources to achieve them. LLMs are particularly well-suited for automated planning due to their strong capabilities in commonsense reasoning. They can deduce a sequence of actions needed to achieve a goal from a given state and identify an effective course of action. However, it is frequently observed that plans generated through direct prompting often fail upon execution. Our survey aims to highlight the existing challenges in planning with language models, focusing on key areas such as embodied environments, optimal scheduling, competitive and cooperative games, task decomposition, reasoning, and planning. Through this study, we explore how LLMs transform AI planning and provide unique insights into the future of LM-assisted planning.
SiamQuality: A ConvNet-Based Foundation Model for Imperfect Physiological Signals
Apr 26, 2024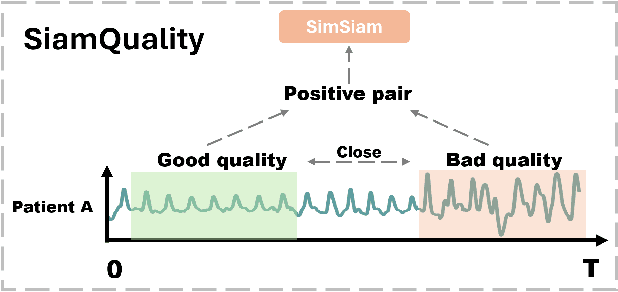

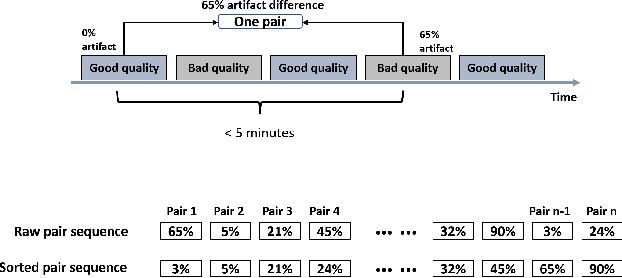
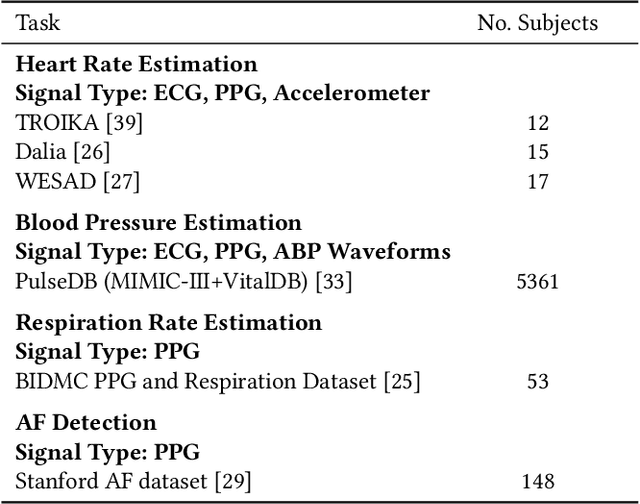
Foundation models, especially those using transformers as backbones, have gained significant popularity, particularly in language and language-vision tasks. However, large foundation models are typically trained on high-quality data, which poses a significant challenge, given the prevalence of poor-quality real-world data. This challenge is more pronounced for developing foundation models for physiological data; such data are often noisy, incomplete, or inconsistent. The present work aims to provide a toolset for developing foundation models on physiological data. We leverage a large dataset of photoplethysmography (PPG) signals from hospitalized intensive care patients. For this data, we propose SimQuality, a novel self-supervised learning task based on convolutional neural networks (CNNs) as the backbone to enforce representations to be similar for good and poor quality signals that are from similar physiological states. We pre-trained the SimQuality on over 36 million 30-second PPG pairs and then fine-tuned and tested on six downstream tasks using external datasets. The results demonstrate the superiority of the proposed approach on all the downstream tasks, which are extremely important for heart monitoring on wearable devices. Our method indicates that CNNs can be an effective backbone for foundation models that are robust to training data quality.
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
Apr 01, 2024



Uncovering early-stage metrics that reflect final model performance is one core principle for large-scale pretraining. The existing scaling law demonstrates the power-law correlation between pretraining loss and training flops, which serves as an important indicator of the current training state for large language models. However, this principle only focuses on the model's compression properties on the training data, resulting in an inconsistency with the ability improvements on the downstream tasks. Some follow-up works attempted to extend the scaling-law to more complex metrics (such as hyperparameters), but still lacked a comprehensive analysis of the dynamic differences among various capabilities during pretraining. To address the aforementioned limitations, this paper undertakes a comprehensive comparison of model capabilities at various pretraining intermediate checkpoints. Through this analysis, we confirm that specific downstream metrics exhibit similar training dynamics across models of different sizes, up to 67 billion parameters. In addition to our core findings, we've reproduced Amber and OpenLLaMA, releasing their intermediate checkpoints. This initiative offers valuable resources to the research community and facilitates the verification and exploration of LLM pretraining by open-source researchers. Besides, we provide empirical summaries, including performance comparisons of different models and capabilities, and tuition of key metrics for different training phases. Based on these findings, we provide a more user-friendly strategy for evaluating the optimization state, offering guidance for establishing a stable pretraining process.
ADEdgeDrop: Adversarial Edge Dropping for Robust Graph Neural Networks
Mar 14, 2024
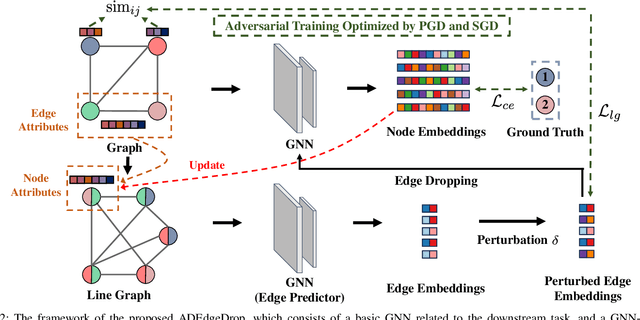

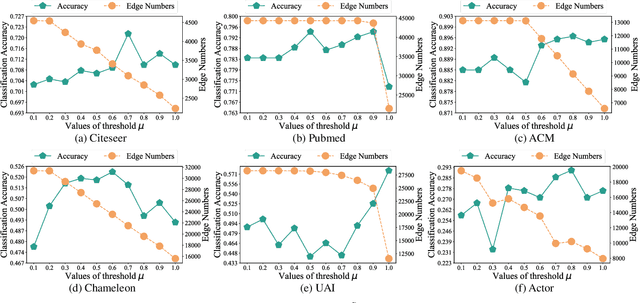
Although Graph Neural Networks (GNNs) have exhibited the powerful ability to gather graph-structured information from neighborhood nodes via various message-passing mechanisms, the performance of GNNs is limited by poor generalization and fragile robustness caused by noisy and redundant graph data. As a prominent solution, Graph Augmentation Learning (GAL) has recently received increasing attention. Among prior GAL approaches, edge-dropping methods that randomly remove edges from a graph during training are effective techniques to improve the robustness of GNNs. However, randomly dropping edges often results in bypassing critical edges, consequently weakening the effectiveness of message passing. In this paper, we propose a novel adversarial edge-dropping method (ADEdgeDrop) that leverages an adversarial edge predictor guiding the removal of edges, which can be flexibly incorporated into diverse GNN backbones. Employing an adversarial training framework, the edge predictor utilizes the line graph transformed from the original graph to estimate the edges to be dropped, which improves the interpretability of the edge-dropping method. The proposed ADEdgeDrop is optimized alternately by stochastic gradient descent and projected gradient descent. Comprehensive experiments on six graph benchmark datasets demonstrate that the proposed ADEdgeDrop outperforms state-of-the-art baselines across various GNN backbones, demonstrating improved generalization and robustness.
Attributed Multi-order Graph Convolutional Network for Heterogeneous Graphs
Apr 18, 2023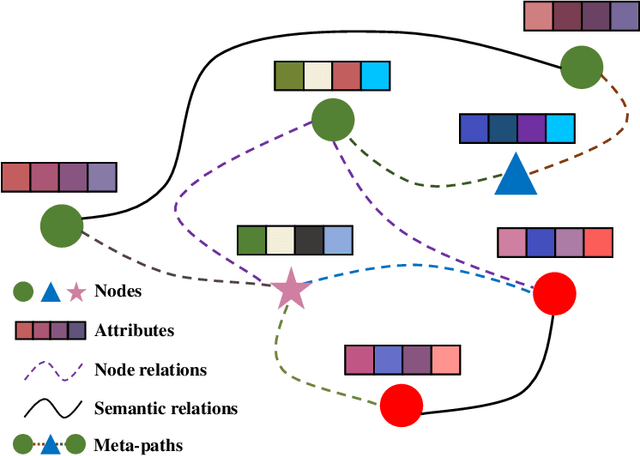
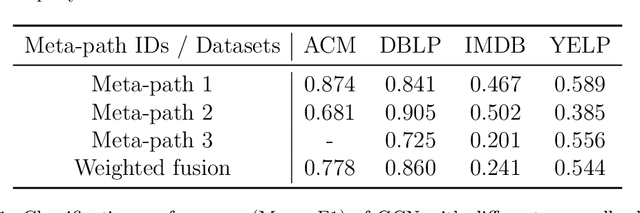
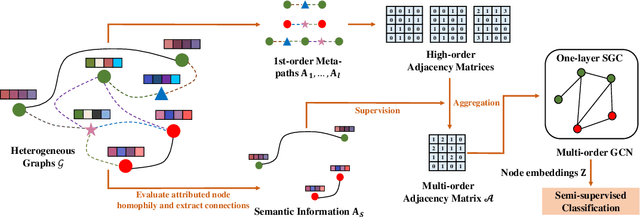
Heterogeneous graph neural networks aim to discover discriminative node embeddings and relations from multi-relational networks.One challenge of heterogeneous graph learning is the design of learnable meta-paths, which significantly influences the quality of learned embeddings.Thus, in this paper, we propose an Attributed Multi-Order Graph Convolutional Network (AMOGCN), which automatically studies meta-paths containing multi-hop neighbors from an adaptive aggregation of multi-order adjacency matrices. The proposed model first builds different orders of adjacency matrices from manually designed node connections. After that, an intact multi-order adjacency matrix is attached from the automatic fusion of various orders of adjacency matrices. This process is supervised by the node semantic information, which is extracted from the node homophily evaluated by attributes. Eventually, we utilize a one-layer simplifying graph convolutional network with the learned multi-order adjacency matrix, which is equivalent to the cross-hop node information propagation with multi-layer graph neural networks. Substantial experiments reveal that AMOGCN gains superior semi-supervised classification performance compared with state-of-the-art competitors.
AGNN: Alternating Graph-Regularized Neural Networks to Alleviate Over-Smoothing
Apr 14, 2023



Graph Convolutional Network (GCN) with the powerful capacity to explore graph-structural data has gained noticeable success in recent years. Nonetheless, most of the existing GCN-based models suffer from the notorious over-smoothing issue, owing to which shallow networks are extensively adopted. This may be problematic for complex graph datasets because a deeper GCN should be beneficial to propagating information across remote neighbors. Recent works have devoted effort to addressing over-smoothing problems, including establishing residual connection structure or fusing predictions from multi-layer models. Because of the indistinguishable embeddings from deep layers, it is reasonable to generate more reliable predictions before conducting the combination of outputs from various layers. In light of this, we propose an Alternating Graph-regularized Neural Network (AGNN) composed of Graph Convolutional Layer (GCL) and Graph Embedding Layer (GEL). GEL is derived from the graph-regularized optimization containing Laplacian embedding term, which can alleviate the over-smoothing problem by periodic projection from the low-order feature space onto the high-order space. With more distinguishable features of distinct layers, an improved Adaboost strategy is utilized to aggregate outputs from each layer, which explores integrated embeddings of multi-hop neighbors. The proposed model is evaluated via a large number of experiments including performance comparison with some multi-layer or multi-order graph neural networks, which reveals the superior performance improvement of AGNN compared with state-of-the-art models.