 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlipedRAG: Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models
Jan 06, 2025Retrieval-Augmented Generation (RAG) addresses hallucination and real-time constraints by dynamically retrieving relevant information from a knowledge database to supplement the LLMs' input. When presented with a query, RAG selects the most semantically similar texts from its knowledge bases and uses them as context for the LLMs to generate more accurate responses. RAG also creates a new attack surface, especially since RAG databases are frequently sourced from public domains. While existing studies have predominantly focused on optimizing RAG's performance and efficiency, emerging research has begun addressing the security concerns associated with RAG. However, these works have some limitations, typically focusing on either white-box methodologies or heuristic-based black-box attacks. Furthermore, prior research has mainly targeted simple factoid question answering, which is neither practically challenging nor resistant to correction. In this paper, we unveil a more realistic and threatening scenario: opinion manipulation for controversial topics against RAG. Particularly, we propose a novel RAG black-box attack method, termed FlipedRAG, which is transfer-based. By leveraging instruction engineering, we obtain partial retrieval model outputs from black-box RAG system, facilitating the training of surrogate models to enhance the effectiveness of opinion manipulation attack. Extensive experimental results confirms that our approach significantly enhances the average success rate of opinion manipulation by 16.7%. It achieves an average of a 50% directional change in the opinion polarity of RAG responses across four themes. Additionally, it induces a 20% shift in user cognition. Furthermore, we discuss the efficacy of potential defense mechanisms and conclude that they are insufficient in mitigating this type of attack, highlighting the urgent need to develop novel defensive strategies.
Every Part Matters: Integrity Verification of Scientific Figures Based on Multimodal Large Language Models
Jul 26, 2024



This paper tackles a key issue in the interpretation of scientific figures: the fine-grained alignment of text and figures. It advances beyond prior research that primarily dealt with straightforward, data-driven visualizations such as bar and pie charts and only offered a basic understanding of diagrams through captioning and classification. We introduce a novel task, Figure Integrity Verification, designed to evaluate the precision of technologies in aligning textual knowledge with visual elements in scientific figures. To support this, we develop a semi-automated method for constructing a large-scale dataset, Figure-seg, specifically designed for this task. Additionally, we propose an innovative framework, Every Part Matters (EPM), which leverages Multimodal Large Language Models (MLLMs) to not only incrementally improve the alignment and verification of text-figure integrity but also enhance integrity through analogical reasoning. Our comprehensive experiments show that these innovations substantially improve upon existing methods, allowing for more precise and thorough analysis of complex scientific figures. This progress not only enhances our understanding of multimodal technologies but also stimulates further research and practical applications across fields requiring the accurate interpretation of complex visual data.
Black-Box Opinion Manipulation Attacks to Retrieval-Augmented Generation of Large Language Models
Jul 18, 2024



Retrieval-Augmented Generation (RAG) is applied to solve hallucination problems and real-time constraints of large language models, but it also induces vulnerabilities against retrieval corruption attacks. Existing research mainly explores the unreliability of RAG in white-box and closed-domain QA tasks. In this paper, we aim to reveal the vulnerabilities of Retrieval-Enhanced Generative (RAG) models when faced with black-box attacks for opinion manipulation. We explore the impact of such attacks on user cognition and decision-making, providing new insight to enhance the reliability and security of RAG models. We manipulate the ranking results of the retrieval model in RAG with instruction and use these results as data to train a surrogate model. By employing adversarial retrieval attack methods to the surrogate model, black-box transfer attacks on RAG are further realized. Experiments conducted on opinion datasets across multiple topics show that the proposed attack strategy can significantly alter the opinion polarity of the content generated by RAG. This demonstrates the model's vulnerability and, more importantly, reveals the potential negative impact on user cognition and decision-making, making it easier to mislead users into accepting incorrect or biased information.
From Model-centered to Human-Centered: Revision Distance as a Metric for Text Evaluation in LLMs-based Applications
Apr 11, 2024



Evaluating large language models (LLMs) is fundamental, particularly in the context of practical applications. Conventional evaluation methods, typically designed primarily for LLM development, yield numerical scores that ignore the user experience. Therefore, our study shifts the focus from model-centered to human-centered evaluation in the context of AI-powered writing assistance applications. Our proposed metric, termed ``Revision Distance,'' utilizes LLMs to suggest revision edits that mimic the human writing process. It is determined by counting the revision edits generated by LLMs. Benefiting from the generated revision edit details, our metric can provide a self-explained text evaluation result in a human-understandable manner beyond the context-independent score. Our results show that for the easy-writing task, ``Revision Distance'' is consistent with established metrics (ROUGE, Bert-score, and GPT-score), but offers more insightful, detailed feedback and better distinguishes between texts. Moreover, in the context of challenging academic writing tasks, our metric still delivers reliable evaluations where other metrics tend to struggle. Furthermore, our metric also holds significant potential for scenarios lacking reference texts.
Let's Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning
Feb 16, 2024



Demonstration ordering, which is an important strategy for in-context learning (ICL), can significantly affects the performance of large language models (LLMs). However, most of the current approaches of ordering require additional knowledge and similarity calculation. We advocate the few-shot in-context curriculum learning (ICCL), a simple but effective demonstration ordering method for ICL, which implies gradually increasing the complexity of prompt demonstrations during the inference process. Then we design three experiments to discuss the effectiveness of ICCL, the formation mechanism of LLM's ICCL capability, and the impact of ordering subjects. Experimental results demonstrate that ICCL, developed during the instruction-tuning stage, is effective for open-source LLMs. Moreover, LLMs exhibit a weaker capacity compared to humans in discerning the difficulty levels of demonstrations. We release our code at https://github.com/61peng/curri_learning.
Know Where to Go: Make LLM a Relevant, Responsible, and Trustworthy Searcher
Oct 19, 2023The advent of Large Language Models (LLMs) has shown the potential to improve relevance and provide direct answers in web searches. However, challenges arise in validating the reliability of generated results and the credibility of contributing sources, due to the limitations of traditional information retrieval algorithms and the LLM hallucination problem. Aiming to create a "PageRank" for the LLM era, we strive to transform LLM into a relevant, responsible, and trustworthy searcher. We propose a novel generative retrieval framework leveraging the knowledge of LLMs to foster a direct link between queries and online sources. This framework consists of three core modules: Generator, Validator, and Optimizer, each focusing on generating trustworthy online sources, verifying source reliability, and refining unreliable sources, respectively. Extensive experiments and evaluations highlight our method's superior relevance, responsibility, and trustfulness against various SOTA methods.
Low-Resource Multi-Granularity Academic Function Recognition Based on Multiple Prompt Knowledge
May 05, 2023

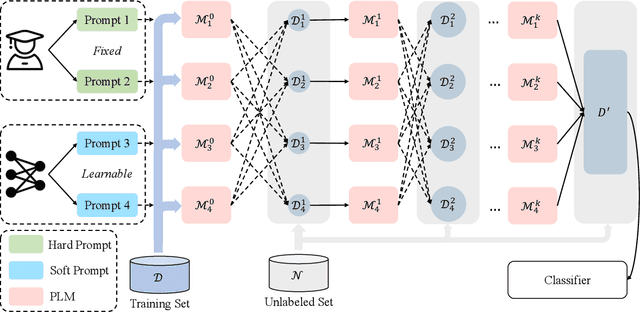
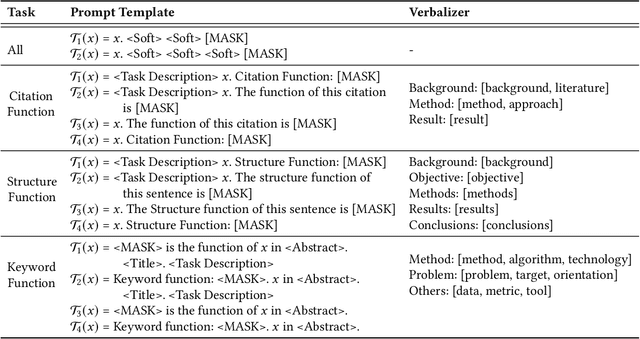
Fine-tuning pre-trained language models (PLMs), e.g., SciBERT, generally requires large numbers of annotated data to achieve state-of-the-art performance on a range of NLP tasks in the scientific domain. However, obtaining the fine-tune data for scientific NLP task is still challenging and expensive. Inspired by recent advancement in prompt learning, in this paper, we propose the Mix Prompt Tuning (MPT), which is a semi-supervised method to alleviate the dependence on annotated data and improve the performance of multi-granularity academic function recognition tasks with a small number of labeled examples. Specifically, the proposed method provides multi-perspective representations by combining manual prompt templates with automatically learned continuous prompt templates to help the given academic function recognition task take full advantage of knowledge in PLMs. Based on these prompt templates and the fine-tuned PLM, a large number of pseudo labels are assigned to the unlabeled examples. Finally, we fine-tune the PLM using the pseudo training set. We evaluate our method on three academic function recognition tasks of different granularity including the citation function, the abstract sentence function, and the keyword function, with datasets from computer science domain and biomedical domain. Extensive experiments demonstrate the effectiveness of our method and statistically significant improvements against strong baselines. In particular, it achieves an average increase of 5% in Macro-F1 score compared with fine-tuning, and 6% in Macro-F1 score compared with other semi-supervised method under low-resource settings. In addition, MPT is a general method that can be easily applied to other low-resource scientific classification tasks.