 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlowFocus: Enhancing Fine-grained Temporal Understanding in Video LLM
Feb 03, 2026Large language models (LLMs) have demonstrated exceptional capabilities in text understanding, which has paved the way for their expansion into video LLMs (Vid-LLMs) to analyze video data. However, current Vid-LLMs struggle to simultaneously retain high-quality frame-level semantic information (i.e., a sufficient number of tokens per frame) and comprehensive video-level temporal information (i.e., an adequate number of sampled frames per video). This limitation hinders the advancement of Vid-LLMs towards fine-grained video understanding. To address this issue, we introduce the SlowFocus mechanism, which significantly enhances the equivalent sampling frequency without compromising the quality of frame-level visual tokens. SlowFocus begins by identifying the query-related temporal segment based on the posed question, then performs dense sampling on this segment to extract local high-frequency features. A multi-frequency mixing attention module is further leveraged to aggregate these local high-frequency details with global low-frequency contexts for enhanced temporal comprehension. Additionally, to tailor Vid-LLMs to this innovative mechanism, we introduce a set of training strategies aimed at bolstering both temporal grounding and detailed temporal reasoning capabilities. Furthermore, we establish FineAction-CGR, a benchmark specifically devised to assess the ability of Vid-LLMs to process fine-grained temporal understanding tasks. Comprehensive experiments demonstrate the superiority of our mechanism across both existing public video understanding benchmarks and our proposed FineAction-CGR.
KFFocus: Highlighting Keyframes for Enhanced Video Understanding
Aug 12, 2025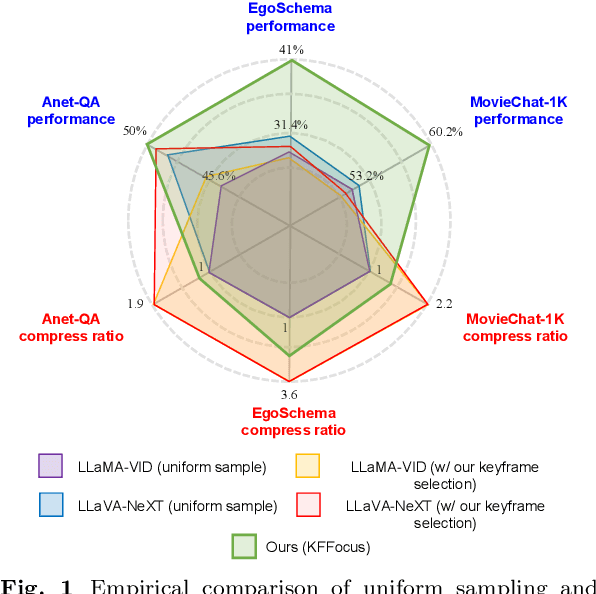
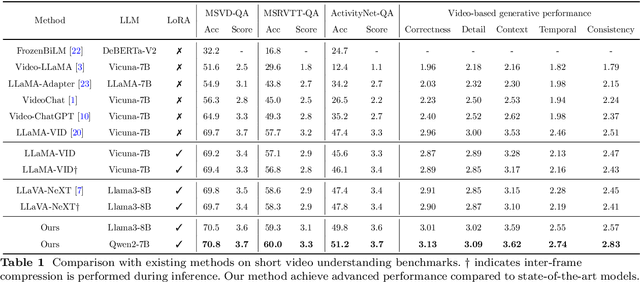
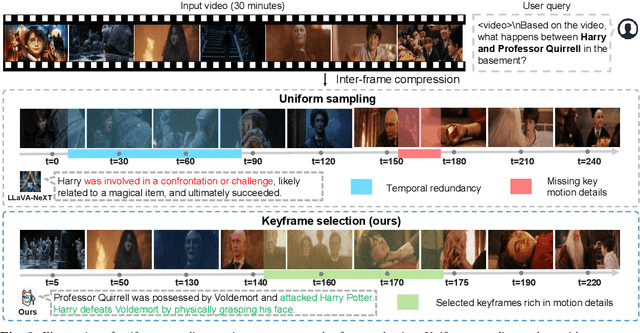
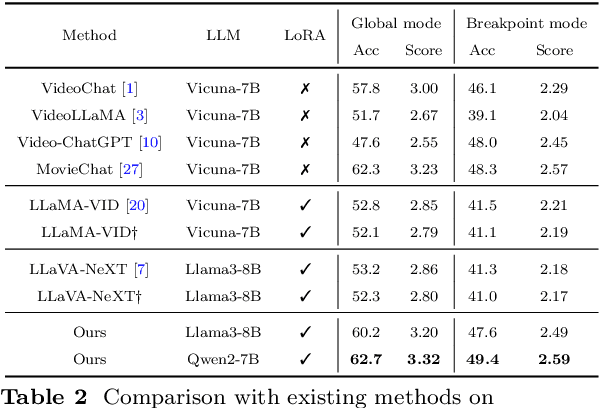
Recently, with the emergence of large language models, multimodal LLMs have demonstrated exceptional capabilities in image and video modalities. Despite advancements in video comprehension, the substantial computational demands of long video sequences lead current video LLMs (Vid-LLMs) to employ compression strategies at both the inter-frame level (e.g., uniform sampling of video frames) and intra-frame level (e.g., condensing all visual tokens of each frame into a limited number). However, this approach often neglects the uneven temporal distribution of critical information across frames, risking the omission of keyframes that contain essential temporal and semantic details. To tackle these challenges, we propose KFFocus, a method designed to efficiently compress video tokens and emphasize the informative context present within video frames. We substitute uniform sampling with a refined approach inspired by classic video compression principles to identify and capture keyframes based on their temporal redundancy. By assigning varying condensation ratios to frames based on their contextual relevance, KFFocus efficiently reduces token redundancy while preserving informative content details. Additionally, we introduce a spatiotemporal modeling module that encodes both the temporal relationships between video frames and the spatial structure within each frame, thus providing Vid-LLMs with a nuanced understanding of spatial-temporal dynamics. Extensive experiments on widely recognized video understanding benchmarks, especially long video scenarios, demonstrate that KFFocus significantly outperforms existing methods, achieving substantial computational efficiency and enhanced accuracy.
LaneCorrect: Self-supervised Lane Detection
Apr 23, 2024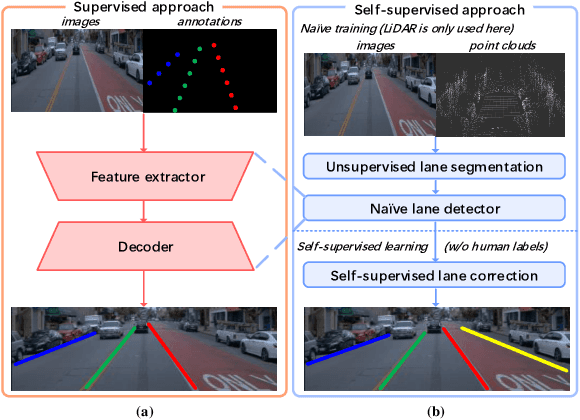



Lane detection has evolved highly functional autonomous driving system to understand driving scenes even under complex environments. In this paper, we work towards developing a generalized computer vision system able to detect lanes without using any annotation. We make the following contributions: (i) We illustrate how to perform unsupervised 3D lane segmentation by leveraging the distinctive intensity of lanes on the LiDAR point cloud frames, and then obtain the noisy lane labels in the 2D plane by projecting the 3D points; (ii) We propose a novel self-supervised training scheme, dubbed LaneCorrect, that automatically corrects the lane label by learning geometric consistency and instance awareness from the adversarial augmentations; (iii) With the self-supervised pre-trained model, we distill to train a student network for arbitrary target lane (e.g., TuSimple) detection without any human labels; (iv) We thoroughly evaluate our self-supervised method on four major lane detection benchmarks (including TuSimple, CULane, CurveLanes and LLAMAS) and demonstrate excellent performance compared with existing supervised counterpart, whilst showing more effective results on alleviating the domain gap, i.e., training on CULane and test on TuSimple.
Reason2Drive: Towards Interpretable and Chain-based Reasoning for Autonomous Driving
Dec 06, 2023Large vision-language models (VLMs) have garnered increasing interest in autonomous driving areas, due to their advanced capabilities in complex reasoning tasks essential for highly autonomous vehicle behavior. Despite their potential, research in autonomous systems is hindered by the lack of datasets with annotated reasoning chains that explain the decision-making processes in driving. To bridge this gap, we present Reason2Drive, a benchmark dataset with over 600K video-text pairs, aimed at facilitating the study of interpretable reasoning in complex driving environments. We distinctly characterize the autonomous driving process as a sequential combination of perception, prediction, and reasoning steps, and the question-answer pairs are automatically collected from a diverse range of open-source outdoor driving datasets, including nuScenes, Waymo and ONCE. Moreover, we introduce a novel aggregated evaluation metric to assess chain-based reasoning performance in autonomous systems, addressing the semantic ambiguities of existing metrics such as BLEU and CIDEr. Based on the proposed benchmark, we conduct experiments to assess various existing VLMs, revealing insights into their reasoning capabilities. Additionally, we develop an efficient approach to empower VLMs to leverage object-level perceptual elements in both feature extraction and prediction, further enhancing their reasoning accuracy. The code and dataset will be released.
PARTNER: Level up the Polar Representation for LiDAR 3D Object Detection
Aug 08, 2023



Recently, polar-based representation has shown promising properties in perceptual tasks. In addition to Cartesian-based approaches, which separate point clouds unevenly, representing point clouds as polar grids has been recognized as an alternative due to (1) its advantage in robust performance under different resolutions and (2) its superiority in streaming-based approaches. However, state-of-the-art polar-based detection methods inevitably suffer from the feature distortion problem because of the non-uniform division of polar representation, resulting in a non-negligible performance gap compared to Cartesian-based approaches. To tackle this issue, we present PARTNER, a novel 3D object detector in the polar coordinate. PARTNER alleviates the dilemma of feature distortion with global representation re-alignment and facilitates the regression by introducing instance-level geometric information into the detection head. Extensive experiments show overwhelming advantages in streaming-based detection and different resolutions. Furthermore, our method outperforms the previous polar-based works with remarkable margins of 3.68% and 9.15% on Waymo and ONCE validation set, thus achieving competitive results over the state-of-the-art methods.
ONCE-3DLanes: Building Monocular 3D Lane Detection
May 14, 2022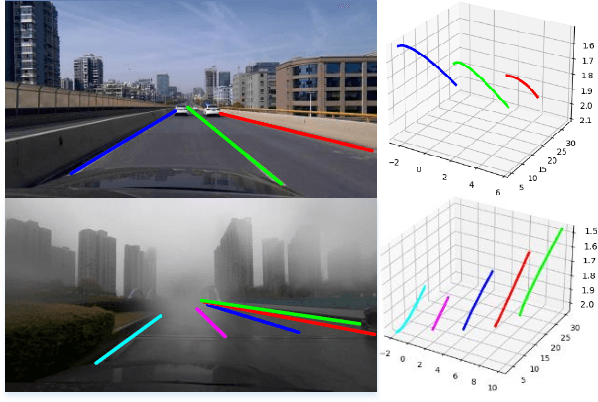
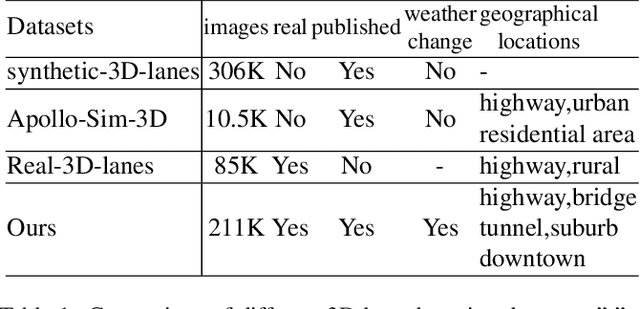
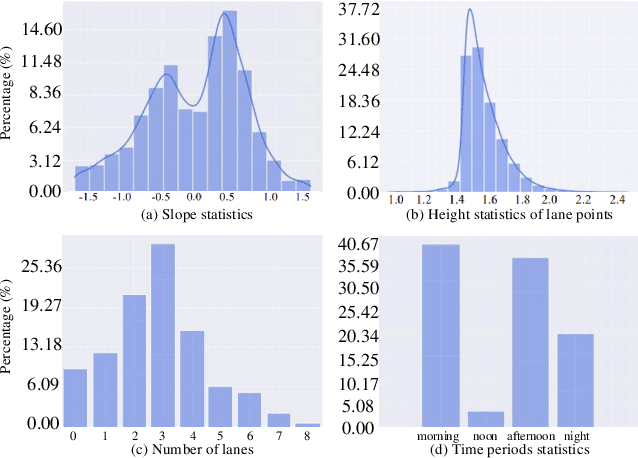
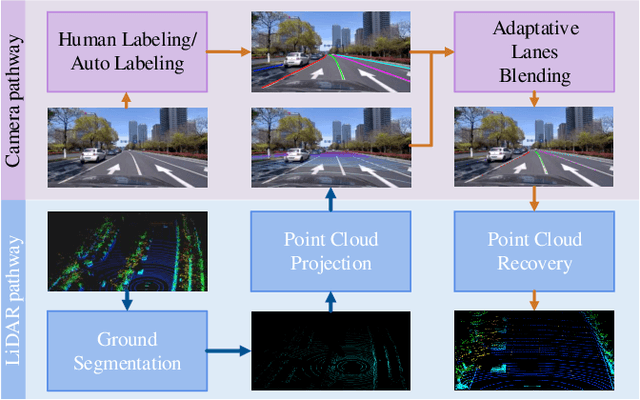
We present ONCE-3DLanes, a real-world autonomous driving dataset with lane layout annotation in 3D space. Conventional 2D lane detection from a monocular image yields poor performance of following planning and control tasks in autonomous driving due to the case of uneven road. Predicting the 3D lane layout is thus necessary and enables effective and safe driving. However, existing 3D lane detection datasets are either unpublished or synthesized from a simulated environment, severely hampering the development of this field. In this paper, we take steps towards addressing these issues. By exploiting the explicit relationship between point clouds and image pixels, a dataset annotation pipeline is designed to automatically generate high-quality 3D lane locations from 2D lane annotations in 211K road scenes. In addition, we present an extrinsic-free, anchor-free method, called SALAD, regressing the 3D coordinates of lanes in image view without converting the feature map into the bird's-eye view (BEV). To facilitate future research on 3D lane detection, we benchmark the dataset and provide a novel evaluation metric, performing extensive experiments of both existing approaches and our proposed method. The aim of our work is to revive the interest of 3D lane detection in a real-world scenario. We believe our work can lead to the expected and unexpected innovations in both academia and industry.