 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVP: Polar Representation Boost for 3D Semantic Occupancy Prediction
Dec 10, 2024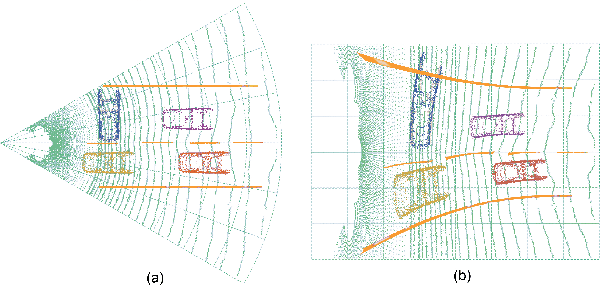
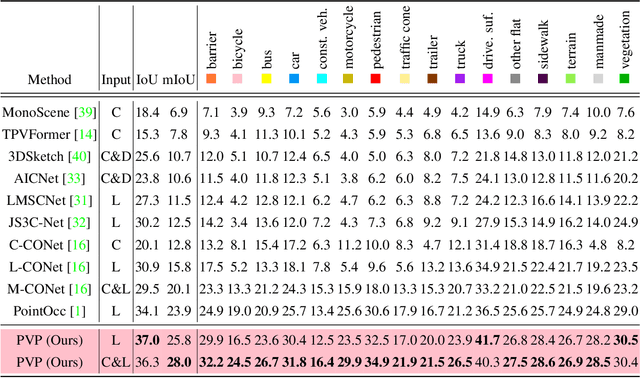
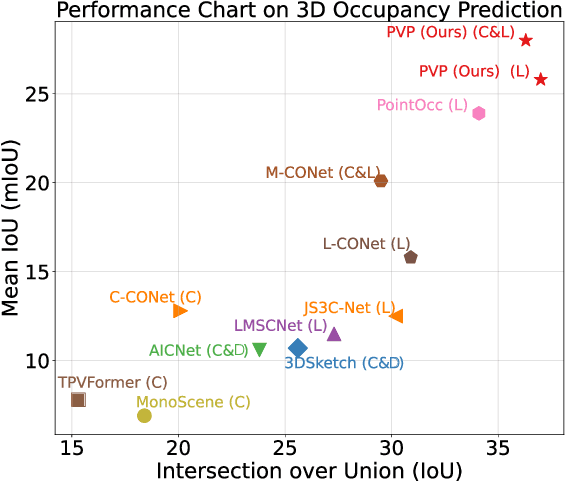
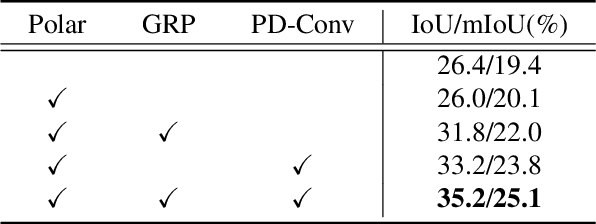
Recently, polar coordinate-based representations have shown promise for 3D perceptual tasks. Compared to Cartesian methods, polar grids provide a viable alternative, offering better detail preservation in nearby spaces while covering larger areas. However, they face feature distortion due to non-uniform division. To address these issues, we introduce the Polar Voxel Occupancy Predictor (PVP), a novel 3D multi-modal predictor that operates in polar coordinates. PVP features two key design elements to overcome distortion: a Global Represent Propagation (GRP) module that integrates global spatial data into 3D volumes, and a Plane Decomposed Convolution (PD-Conv) that simplifies 3D distortions into 2D convolutions. These innovations enable PVP to outperform existing methods, achieving significant improvements in mIoU and IoU metrics on the OpenOccupancy dataset.
PARTNER: Level up the Polar Representation for LiDAR 3D Object Detection
Aug 08, 2023



Recently, polar-based representation has shown promising properties in perceptual tasks. In addition to Cartesian-based approaches, which separate point clouds unevenly, representing point clouds as polar grids has been recognized as an alternative due to (1) its advantage in robust performance under different resolutions and (2) its superiority in streaming-based approaches. However, state-of-the-art polar-based detection methods inevitably suffer from the feature distortion problem because of the non-uniform division of polar representation, resulting in a non-negligible performance gap compared to Cartesian-based approaches. To tackle this issue, we present PARTNER, a novel 3D object detector in the polar coordinate. PARTNER alleviates the dilemma of feature distortion with global representation re-alignment and facilitates the regression by introducing instance-level geometric information into the detection head. Extensive experiments show overwhelming advantages in streaming-based detection and different resolutions. Furthermore, our method outperforms the previous polar-based works with remarkable margins of 3.68% and 9.15% on Waymo and ONCE validation set, thus achieving competitive results over the state-of-the-art methods.
Point2Seq: Detecting 3D Objects as Sequences
Mar 25, 2022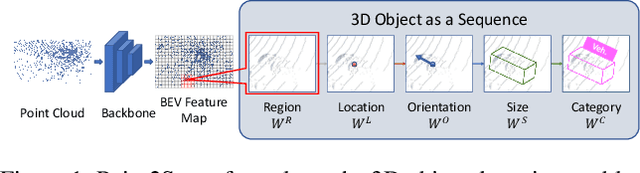
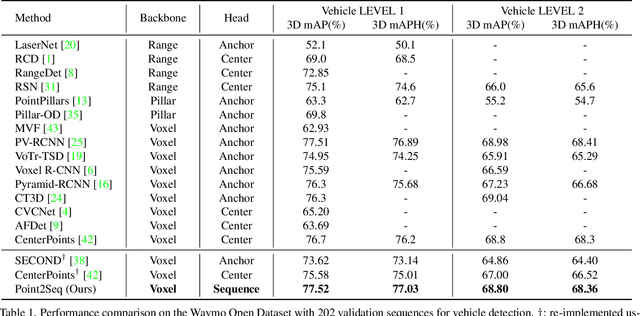
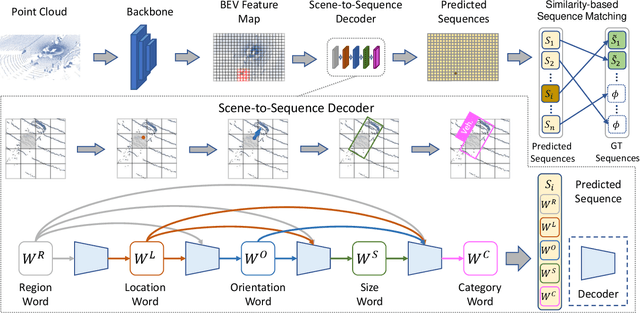
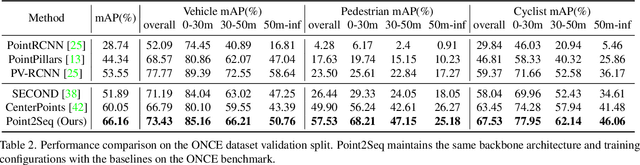
We present a simple and effective framework, named Point2Seq, for 3D object detection from point clouds. In contrast to previous methods that normally {predict attributes of 3D objects all at once}, we expressively model the interdependencies between attributes of 3D objects, which in turn enables a better detection accuracy. Specifically, we view each 3D object as a sequence of words and reformulate the 3D object detection task as decoding words from 3D scenes in an auto-regressive manner. We further propose a lightweight scene-to-sequence decoder that can auto-regressively generate words conditioned on features from a 3D scene as well as cues from the preceding words. The predicted words eventually constitute a set of sequences that completely describe the 3D objects in the scene, and all the predicted sequences are then automatically assigned to the respective ground truths through similarity-based sequence matching. Our approach is conceptually intuitive and can be readily plugged upon most existing 3D-detection backbones without adding too much computational overhead; the sequential decoding paradigm we proposed, on the other hand, can better exploit information from complex 3D scenes with the aid of preceding predicted words. Without bells and whistles, our method significantly outperforms previous anchor- and center-based 3D object detection frameworks, yielding the new state of the art on the challenging ONCE dataset as well as the Waymo Open Dataset. Code is available at \url{https://github.com/ocNflag/point2seq}.
Voxel Transformer for 3D Object Detection
Sep 13, 2021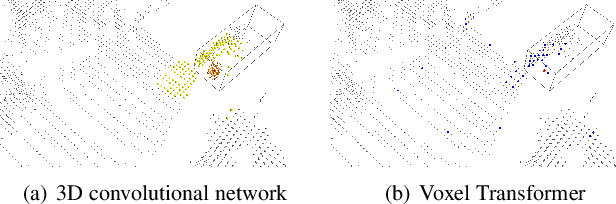
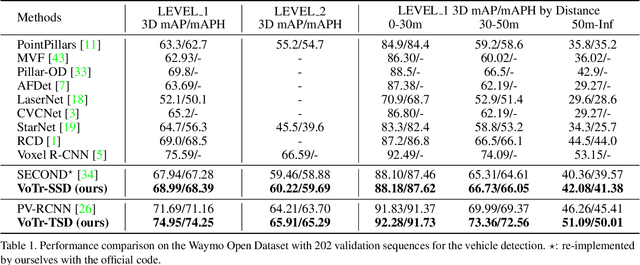
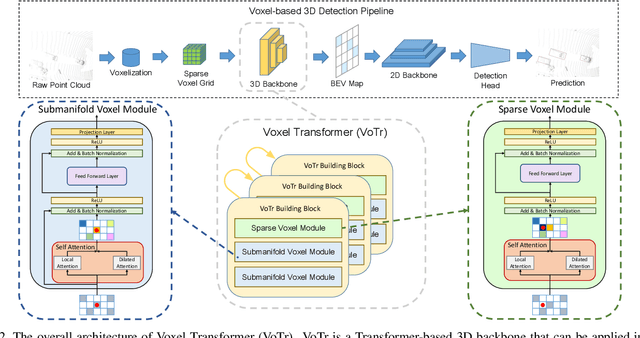
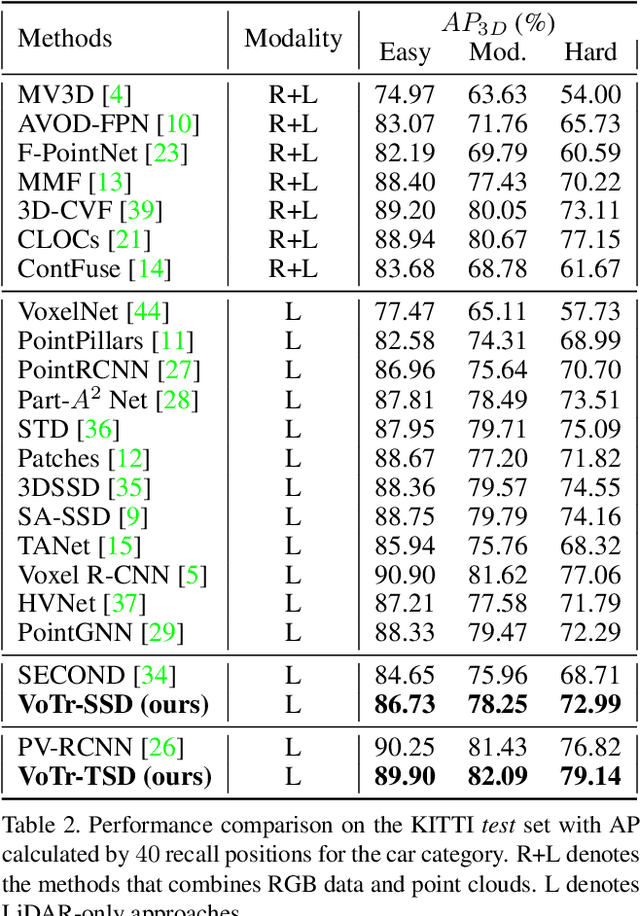
We present Voxel Transformer (VoTr), a novel and effective voxel-based Transformer backbone for 3D object detection from point clouds. Conventional 3D convolutional backbones in voxel-based 3D detectors cannot efficiently capture large context information, which is crucial for object recognition and localization, owing to the limited receptive fields. In this paper, we resolve the problem by introducing a Transformer-based architecture that enables long-range relationships between voxels by self-attention. Given the fact that non-empty voxels are naturally sparse but numerous, directly applying standard Transformer on voxels is non-trivial. To this end, we propose the sparse voxel module and the submanifold voxel module, which can operate on the empty and non-empty voxel positions effectively. To further enlarge the attention range while maintaining comparable computational overhead to the convolutional counterparts, we propose two attention mechanisms for multi-head attention in those two modules: Local Attention and Dilated Attention, and we further propose Fast Voxel Query to accelerate the querying process in multi-head attention. VoTr contains a series of sparse and submanifold voxel modules and can be applied in most voxel-based detectors. Our proposed VoTr shows consistent improvement over the convolutional baselines while maintaining computational efficiency on the KITTI dataset and the Waymo Open dataset.
AutoSpace: Neural Architecture Search with Less Human Interference
Mar 22, 2021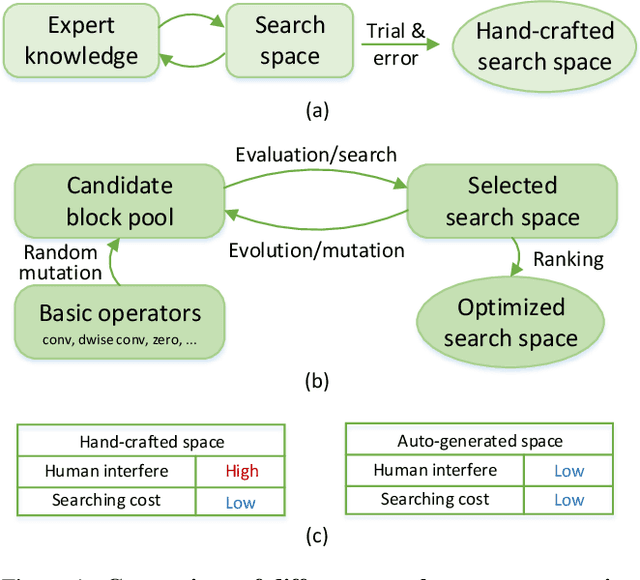
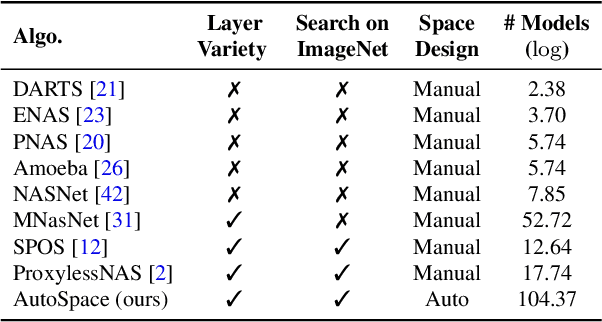
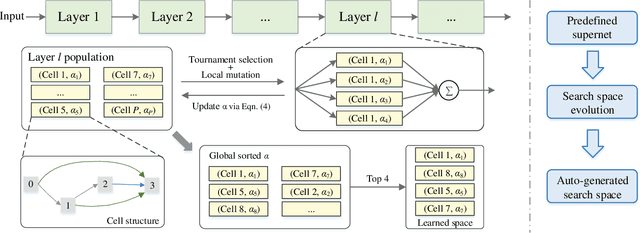
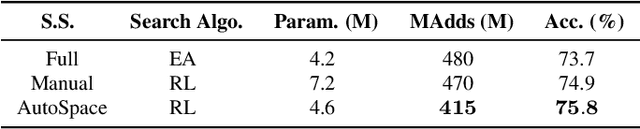
Current neural architecture search (NAS) algorithms still require expert knowledge and effort to design a search space for network construction. In this paper, we consider automating the search space design to minimize human interference, which however faces two challenges: the explosive complexity of the exploration space and the expensive computation cost to evaluate the quality of different search spaces. To solve them, we propose a novel differentiable evolutionary framework named AutoSpace, which evolves the search space to an optimal one with following novel techniques: a differentiable fitness scoring function to efficiently evaluate the performance of cells and a reference architecture to speedup the evolution procedure and avoid falling into sub-optimal solutions. The framework is generic and compatible with additional computational constraints, making it feasible to learn specialized search spaces that fit different computational budgets. With the learned search space, the performance of recent NAS algorithms can be improved significantly compared with using previously manually designed spaces. Remarkably, the models generated from the new search space achieve 77.8% top-1 accuracy on ImageNet under the mobile setting (MAdds < 500M), out-performing previous SOTA EfficientNet-B0 by 0.7%. All codes will be made public.