 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint2Seq: Detecting 3D Objects as Sequences
Paper and Code
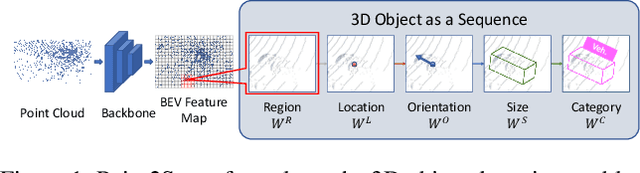
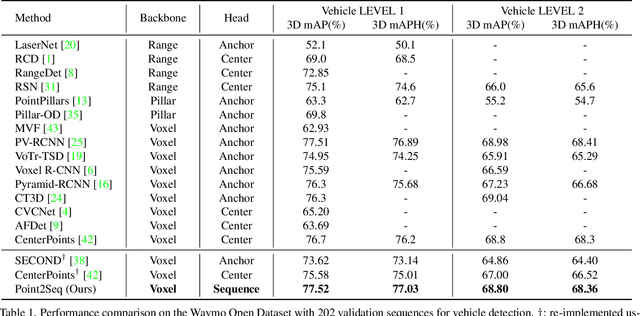
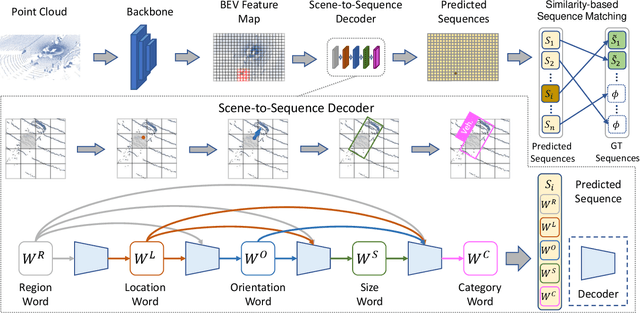
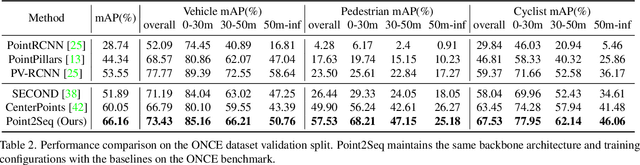
We present a simple and effective framework, named Point2Seq, for 3D object detection from point clouds. In contrast to previous methods that normally {predict attributes of 3D objects all at once}, we expressively model the interdependencies between attributes of 3D objects, which in turn enables a better detection accuracy. Specifically, we view each 3D object as a sequence of words and reformulate the 3D object detection task as decoding words from 3D scenes in an auto-regressive manner. We further propose a lightweight scene-to-sequence decoder that can auto-regressively generate words conditioned on features from a 3D scene as well as cues from the preceding words. The predicted words eventually constitute a set of sequences that completely describe the 3D objects in the scene, and all the predicted sequences are then automatically assigned to the respective ground truths through similarity-based sequence matching. Our approach is conceptually intuitive and can be readily plugged upon most existing 3D-detection backbones without adding too much computational overhead; the sequential decoding paradigm we proposed, on the other hand, can better exploit information from complex 3D scenes with the aid of preceding predicted words. Without bells and whistles, our method significantly outperforms previous anchor- and center-based 3D object detection frameworks, yielding the new state of the art on the challenging ONCE dataset as well as the Waymo Open Dataset. Code is available at \url{https://github.com/ocNflag/point2seq}.