 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
PASemiQA: Plan-Assisted Agent for Question Answering on Semi-Structured Data with Text and Relational Information
Feb 28, 2025Large language models (LLMs) have shown impressive abilities in answering questions across various domains, but they often encounter hallucination issues on questions that require professional and up-to-date knowledge. To address this limitation, retrieval-augmented generation (RAG) techniques have been proposed, which retrieve relevant information from external sources to inform their responses. However, existing RAG methods typically focus on a single type of external data, such as vectorized text database or knowledge graphs, and cannot well handle real-world questions on semi-structured data containing both text and relational information. To bridge this gap, we introduce PASemiQA, a novel approach that jointly leverages text and relational information in semi-structured data to answer questions. PASemiQA first generates a plan to identify relevant text and relational information to answer the question in semi-structured data, and then uses an LLM agent to traverse the semi-structured data and extract necessary information. Our empirical results demonstrate the effectiveness of PASemiQA across different semi-structured datasets from various domains, showcasing its potential to improve the accuracy and reliability of question answering systems on semi-structured data.
Corrupted but Not Broken: Rethinking the Impact of Corrupted Data in Visual Instruction Tuning
Feb 18, 2025Visual Instruction Tuning (VIT) enhances Multimodal Large Language Models (MLLMs) but it is hindered by corrupted datasets containing hallucinated content, incorrect responses, and poor OCR quality. While prior works focus on dataset refinement through high-quality data collection or rule-based filtering, they are costly or limited to specific types of corruption. To deeply understand how corrupted data affects MLLMs, in this paper, we systematically investigate this issue and find that while corrupted data degrades the performance of MLLMs, its effects are largely superficial in that the performance of MLLMs can be largely restored by either disabling a small subset of parameters or post-training with a small amount of clean data. Additionally, corrupted MLLMs exhibit improved ability to distinguish clean samples from corrupted ones, enabling the dataset cleaning without external help. Based on those insights, we propose a corruption-robust training paradigm combining self-validation and post-training, which significantly outperforms existing corruption mitigation strategies.
Mixup Augmentation with Multiple Interpolations
Jun 03, 2024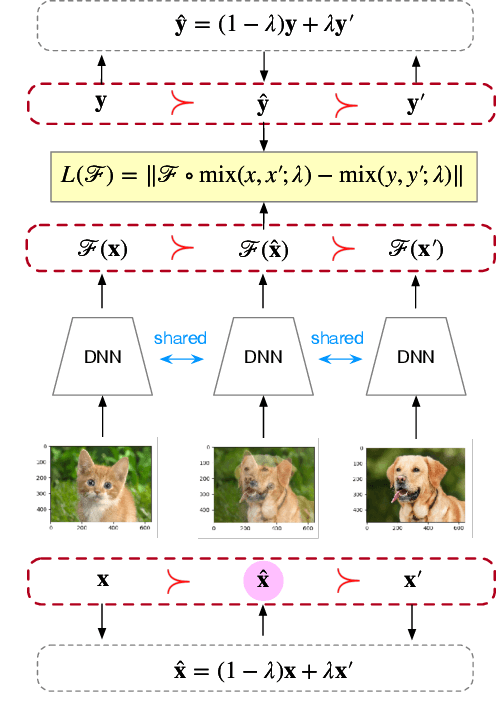


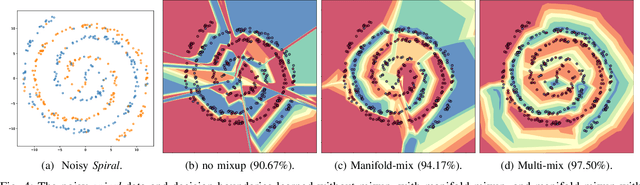
Mixup and its variants form a popular class of data augmentation techniques.Using a random sample pair, it generates a new sample by linear interpolation of the inputs and labels. However, generating only one single interpolation may limit its augmentation ability. In this paper, we propose a simple yet effective extension called multi-mix, which generates multiple interpolations from a sample pair. With an ordered sequence of generated samples, multi-mix can better guide the training process than standard mixup. Moreover, theoretically, this can also reduce the stochastic gradient variance. Extensive experiments on a number of synthetic and large-scale data sets demonstrate that multi-mix outperforms various mixup variants and non-mixup-based baselines in terms of generalization, robustness, and calibration.
Loss-aware Curriculum Learning for Heterogeneous Graph Neural Networks
Feb 29, 2024Heterogeneous Graph Neural Networks (HGNNs) are a class of deep learning models designed specifically for heterogeneous graphs, which are graphs that contain different types of nodes and edges. This paper investigates the application of curriculum learning techniques to improve the performance and robustness of Heterogeneous Graph Neural Networks (GNNs). To better classify the quality of the data, we design a loss-aware training schedule, named LTS that measures the quality of every nodes of the data and incorporate the training dataset into the model in a progressive manner that increases difficulty step by step. LTS can be seamlessly integrated into various frameworks, effectively reducing bias and variance, mitigating the impact of noisy data, and enhancing overall accuracy. Our findings demonstrate the efficacy of curriculum learning in enhancing HGNNs capabilities for analyzing complex graph-structured data. The code is public at https: //github.com/LARS-research/CLGNN/.
Positive-Unlabeled Node Classification with Structure-aware Graph Learning
Oct 20, 2023Node classification on graphs is an important research problem with many applications. Real-world graph data sets may not be balanced and accurate as assumed by most existing works. A challenging setting is positive-unlabeled (PU) node classification, where labeled nodes are restricted to positive nodes. It has diverse applications, e.g., pandemic prediction or network anomaly detection. Existing works on PU node classification overlook information in the graph structure, which can be critical. In this paper, we propose to better utilize graph structure for PU node classification. We first propose a distance-aware PU loss that uses homophily in graphs to introduce more accurate supervision. We also propose a regularizer to align the model with graph structure. Theoretical analysis shows that minimizing the proposed loss also leads to minimizing the expected loss with both positive and negative labels. Extensive empirical evaluation on diverse graph data sets demonstrates its superior performance over existing state-of-the-art methods.
An Adaptive Policy to Employ Sharpness-Aware Minimization
Apr 28, 2023Sharpness-aware minimization (SAM), which searches for flat minima by min-max optimization, has been shown to be useful in improving model generalization. However, since each SAM update requires computing two gradients, its computational cost and training time are both doubled compared to standard empirical risk minimization (ERM). Recent state-of-the-arts reduce the fraction of SAM updates and thus accelerate SAM by switching between SAM and ERM updates randomly or periodically. In this paper, we design an adaptive policy to employ SAM based on the loss landscape geometry. Two efficient algorithms, AE-SAM and AE-LookSAM, are proposed. We theoretically show that AE-SAM has the same convergence rate as SAM. Experimental results on various datasets and architectures demonstrate the efficiency and effectiveness of the adaptive policy.
Leveraging per Image-Token Consistency for Vision-Language Pre-training
Nov 20, 2022Most existing vision-language pre-training (VLP) approaches adopt cross-modal masked language modeling (CMLM) to learn vision-language associations. However, we find that CMLM is insufficient for this purpose according to our observations: (1) Modality bias: a considerable amount of masked tokens in CMLM can be recovered with only the language information, ignoring the visual inputs. (2) Under-utilization of the unmasked tokens: CMLM primarily focuses on the masked token but it cannot simultaneously leverage other tokens to learn vision-language associations. To handle those limitations, we propose EPIC (lEveraging Per Image-Token Consistency for vision-language pre-training). In EPIC, for each image-sentence pair, we mask tokens that are salient to the image (i.e., Saliency-based Masking Strategy) and replace them with alternatives sampled from a language model (i.e., Inconsistent Token Generation Procedure), and then the model is required to determine for each token in the sentence whether they are consistent with the image (i.e., Image-Text Consistent Task). The proposed EPIC method is easily combined with pre-training methods. Extensive experiments show that the combination of the EPIC method and state-of-the-art pre-training approaches, including ViLT, ALBEF, METER, and X-VLM, leads to significant improvements on downstream tasks.
AutoWeird: Weird Translational Scoring Function Identified by Random Search
Jul 24, 2022



Scoring function (SF) measures the plausibility of triplets in knowledge graphs. Different scoring functions can lead to huge differences in link prediction performances on different knowledge graphs. In this report, we describe a weird scoring function found by random search on the open graph benchmark (OGB). This scoring function, called AutoWeird, only uses tail entity and relation in a triplet to compute its plausibility score. Experimental results show that AutoWeird achieves top-1 performance on ogbl-wikikg2 data set, but has much worse performance than other methods on ogbl-biokg data set. By analyzing the tail entity distribution and evaluation protocol of these two data sets, we attribute the unexpected success of AutoWeird on ogbl-wikikg2 to inappropriate evaluation and concentrated tail entity distribution. Such results may motivate further research on how to accurately evaluate the performance of different link prediction methods for knowledge graphs.
Tensorizing Subgraph Search in the Supernet
Jan 04, 2021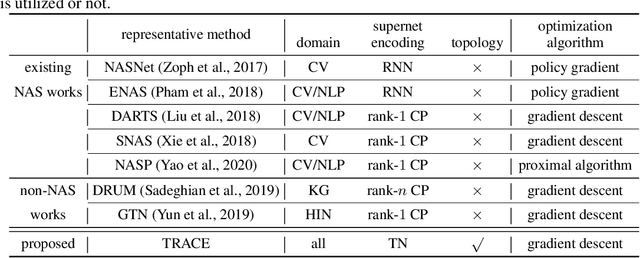
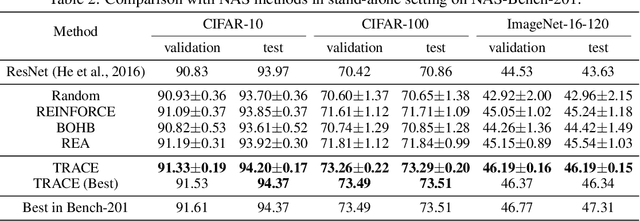
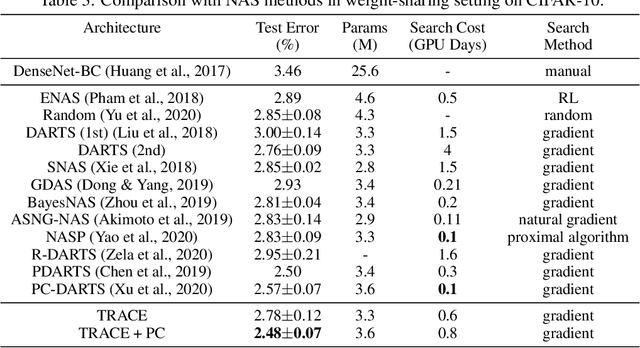
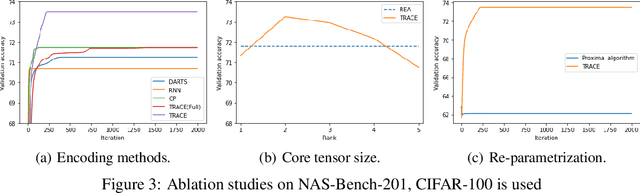
Recently, a special kind of graph, i.e., supernet, which allows two nodes connected by multi-choice edges, has exhibited its power in neural architecture search (NAS) by searching for better architectures for computer vision (CV) and natural language processing (NLP) tasks. In this paper, we discover that the design of such discrete architectures also appears in many other important learning tasks, e.g., logical chain inference in knowledge graphs (KGs) and meta-path discovery in heterogeneous information networks (HINs). Thus, we are motivated to generalize the supernet search problem on a broader horizon. However, none of the existing works are effective since the supernet topology is highly task-dependent and diverse. To address this issue, we propose to tensorize the supernet, i.e., unify the subgraph search problems by a tensor formulation and encode the topology inside the supernet by a tensor network. We further propose an efficient algorithm that admits both stochastic and deterministic objectives to solve the search problem. Finally, we perform extensive experiments on diverse learning tasks, i.e., architecture design for CV, logic inference for KG, and meta-path discovery for HIN. Empirical results demonstrate that our method leads to better performance and architectures.