 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Time Series Anomalies using Granular-ball Vector Data Description
Nov 15, 2025



Modeling normal behavior in dynamic, nonlinear time series data is challenging for effective anomaly detection. Traditional methods, such as nearest neighbor and clustering approaches, often depend on rigid assumptions, such as a predefined number of reliable neighbors or clusters, which frequently break down in complex temporal scenarios. To address these limitations, we introduce the Granular-ball One-Class Network (GBOC), a novel approach based on a data-adaptive representation called Granular-ball Vector Data Description (GVDD). GVDD partitions the latent space into compact, high-density regions represented by granular-balls, which are generated through a density-guided hierarchical splitting process and refined by removing noisy structures. Each granular-ball serves as a prototype for local normal behavior, naturally positioning itself between individual instances and clusters while preserving the local topological structure of the sample set. During training, GBOC improves the compactness of representations by aligning samples with their nearest granular-ball centers. During inference, anomaly scores are computed based on the distance to the nearest granular-ball. By focusing on dense, high-quality regions and significantly reducing the number of prototypes, GBOC delivers both robustness and efficiency in anomaly detection. Extensive experiments validate the effectiveness and superiority of the proposed method, highlighting its ability to handle the challenges of time series anomaly detection.
TSGDiff: Rethinking Synthetic Time Series Generation from a Pure Graph Perspective
Nov 15, 2025Diffusion models have shown great promise in data generation, yet generating time series data remains challenging due to the need to capture complex temporal dependencies and structural patterns. In this paper, we present \textit{TSGDiff}, a novel framework that rethinks time series generation from a graph-based perspective. Specifically, we represent time series as dynamic graphs, where edges are constructed based on Fourier spectrum characteristics and temporal dependencies. A graph neural network-based encoder-decoder architecture is employed to construct a latent space, enabling the diffusion process to model the structural representation distribution of time series effectively. Furthermore, we propose the Topological Structure Fidelity (Topo-FID) score, a graph-aware metric for assessing the structural similarity of time series graph representations. Topo-FID integrates two sub-metrics: Graph Edit Similarity, which quantifies differences in adjacency matrices, and Structural Entropy Similarity, which evaluates the entropy of node degree distributions. This comprehensive metric provides a more accurate assessment of structural fidelity in generated time series. Experiments on real-world datasets demonstrate that \textit{TSGDiff} generates high-quality synthetic time series data generation, faithfully preserving temporal dependencies and structural integrity, thereby advancing the field of synthetic time series generation.
LeMoLE: LLM-Enhanced Mixture of Linear Experts for Time Series Forecasting
Nov 24, 2024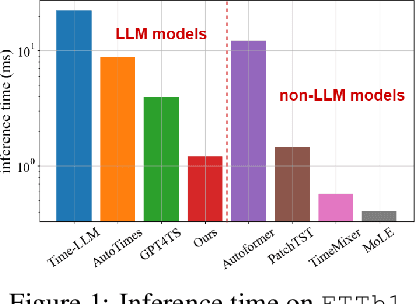
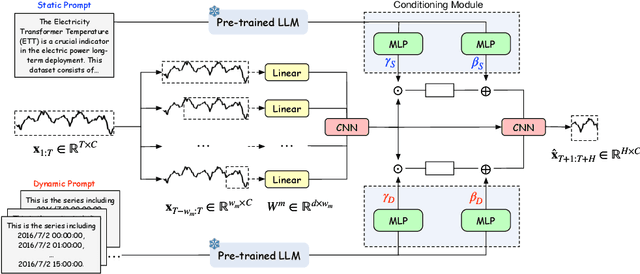
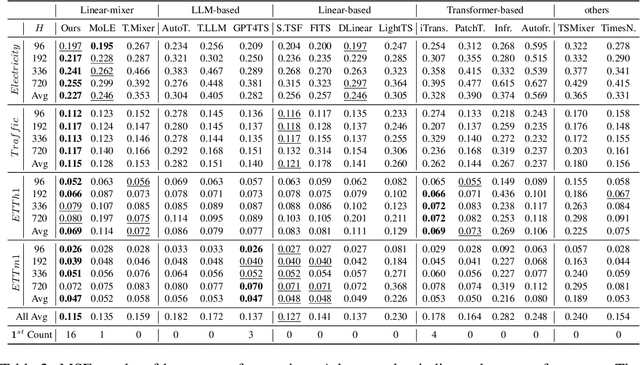
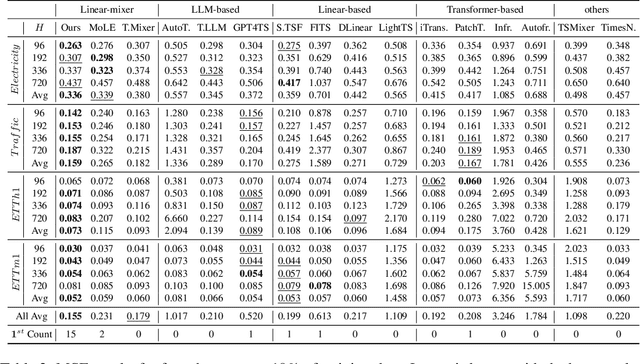
Recent research has shown that large language models (LLMs) can be effectively used for real-world time series forecasting due to their strong natural language understanding capabilities. However, aligning time series into semantic spaces of LLMs comes with high computational costs and inference complexity, particularly for long-range time series generation. Building on recent advancements in using linear models for time series, this paper introduces an LLM-enhanced mixture of linear experts for precise and efficient time series forecasting. This approach involves developing a mixture of linear experts with multiple lookback lengths and a new multimodal fusion mechanism. The use of a mixture of linear experts is efficient due to its simplicity, while the multimodal fusion mechanism adaptively combines multiple linear experts based on the learned features of the text modality from pre-trained large language models. In experiments, we rethink the need to align time series to LLMs by existing time-series large language models and further discuss their efficiency and effectiveness in time series forecasting. Our experimental results show that the proposed LeMoLE model presents lower prediction errors and higher computational efficiency than existing LLM models.
Mixup Augmentation with Multiple Interpolations
Jun 03, 2024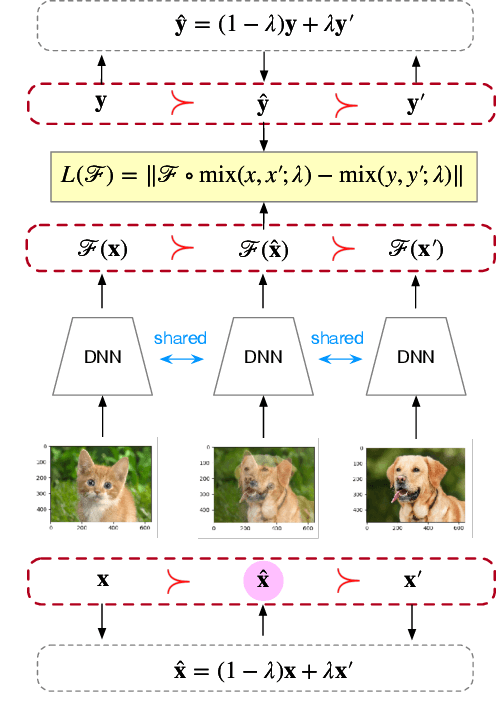


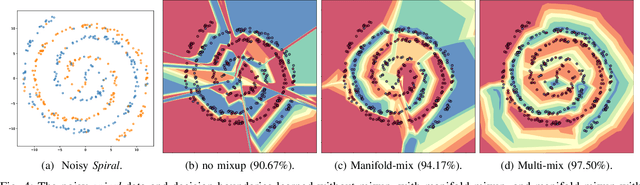
Mixup and its variants form a popular class of data augmentation techniques.Using a random sample pair, it generates a new sample by linear interpolation of the inputs and labels. However, generating only one single interpolation may limit its augmentation ability. In this paper, we propose a simple yet effective extension called multi-mix, which generates multiple interpolations from a sample pair. With an ordered sequence of generated samples, multi-mix can better guide the training process than standard mixup. Moreover, theoretically, this can also reduce the stochastic gradient variance. Extensive experiments on a number of synthetic and large-scale data sets demonstrate that multi-mix outperforms various mixup variants and non-mixup-based baselines in terms of generalization, robustness, and calibration.
Non-autoregressive Conditional Diffusion Models for Time Series Prediction
Jun 08, 2023



Recently, denoising diffusion models have led to significant breakthroughs in the generation of images, audio and text. However, it is still an open question on how to adapt their strong modeling ability to model time series. In this paper, we propose TimeDiff, a non-autoregressive diffusion model that achieves high-quality time series prediction with the introduction of two novel conditioning mechanisms: future mixup and autoregressive initialization. Similar to teacher forcing, future mixup allows parts of the ground-truth future predictions for conditioning, while autoregressive initialization helps better initialize the model with basic time series patterns such as short-term trends. Extensive experiments are performed on nine real-world datasets. Results show that TimeDiff consistently outperforms existing time series diffusion models, and also achieves the best overall performance across a variety of the existing strong baselines (including transformers and FiLM).
Deep-ESN: A Multiple Projection-encoding Hierarchical Reservoir Computing Framework
Nov 13, 2017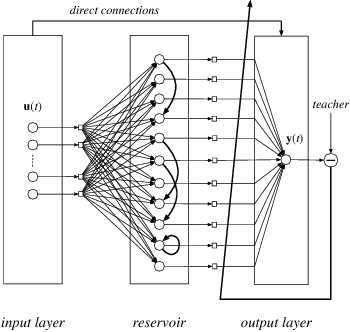
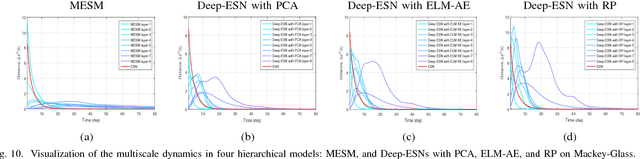
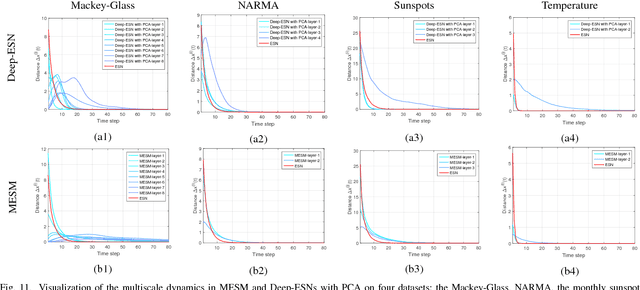
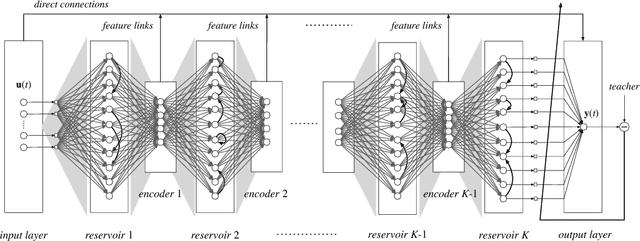
As an efficient recurrent neural network (RNN) model, reservoir computing (RC) models, such as Echo State Networks, have attracted widespread attention in the last decade. However, while they have had great success with time series data [1], [2], many time series have a multiscale structure, which a single-hidden-layer RC model may have difficulty capturing. In this paper, we propose a novel hierarchical reservoir computing framework we call Deep Echo State Networks (Deep-ESNs). The most distinctive feature of a Deep-ESN is its ability to deal with time series through hierarchical projections. Specifically, when an input time series is projected into the high-dimensional echo-state space of a reservoir, a subsequent encoding layer (e.g., a PCA, autoencoder, or a random projection) can project the echo-state representations into a lower-dimensional space. These low-dimensional representations can then be processed by another ESN. By using projection layers and encoding layers alternately in the hierarchical framework, a Deep-ESN can not only attenuate the effects of the collinearity problem in ESNs, but also fully take advantage of the temporal kernel property of ESNs to explore multiscale dynamics of time series. To fuse the multiscale representations obtained by each reservoir, we add connections from each encoding layer to the last output layer. Theoretical analyses prove that stability of a Deep-ESN is guaranteed by the echo state property (ESP), and the time complexity is equivalent to a conventional ESN. Experimental results on some artificial and real world time series demonstrate that Deep-ESNs can capture multiscale dynamics, and outperform both standard ESNs and previous hierarchical ESN-based models.