 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixup Augmentation with Multiple Interpolations
Paper and Code
Jun 03, 2024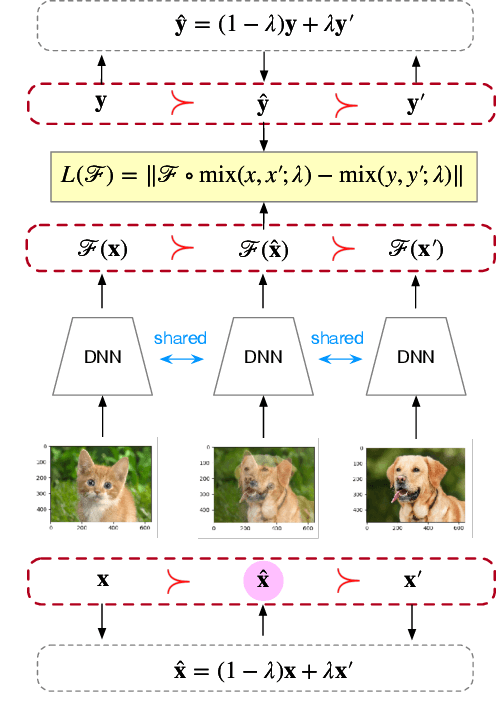


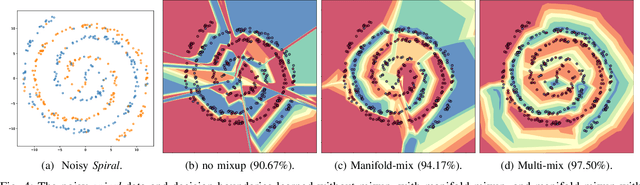
Mixup and its variants form a popular class of data augmentation techniques.Using a random sample pair, it generates a new sample by linear interpolation of the inputs and labels. However, generating only one single interpolation may limit its augmentation ability. In this paper, we propose a simple yet effective extension called multi-mix, which generates multiple interpolations from a sample pair. With an ordered sequence of generated samples, multi-mix can better guide the training process than standard mixup. Moreover, theoretically, this can also reduce the stochastic gradient variance. Extensive experiments on a number of synthetic and large-scale data sets demonstrate that multi-mix outperforms various mixup variants and non-mixup-based baselines in terms of generalization, robustness, and calibration.