 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot Parkour Learning
Sep 12, 2023



Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
May 06, 2023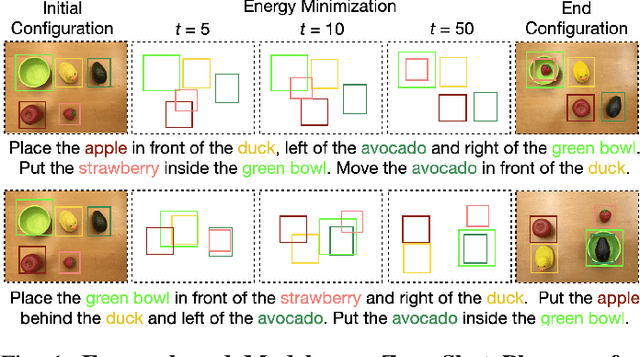
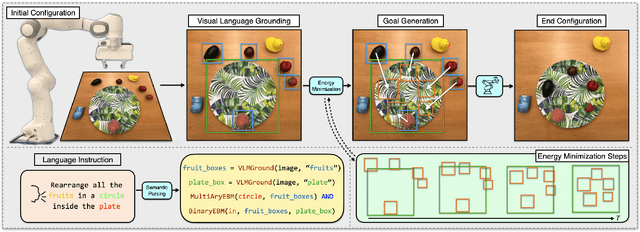


Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene-rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then re-locate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts. Simulation and real-world robot execution videos, as well as our code and datasets are publicly available on our website: https://ebmplanner.github.io.