 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement
Paper and Code
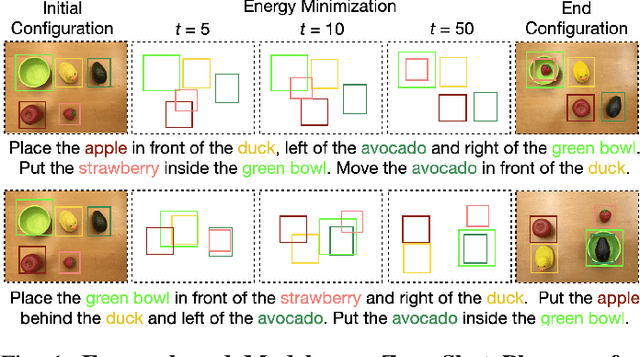
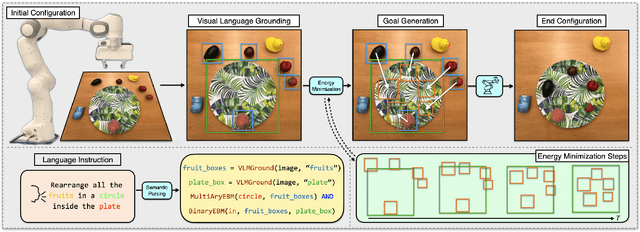


Language is compositional; an instruction can express multiple relation constraints to hold among objects in a scene that a robot is tasked to rearrange. Our focus in this work is an instructable scene-rearranging framework that generalizes to longer instructions and to spatial concept compositions never seen at training time. We propose to represent language-instructed spatial concepts with energy functions over relative object arrangements. A language parser maps instructions to corresponding energy functions and an open-vocabulary visual-language model grounds their arguments to relevant objects in the scene. We generate goal scene configurations by gradient descent on the sum of energy functions, one per language predicate in the instruction. Local vision-based policies then re-locate objects to the inferred goal locations. We test our model on established instruction-guided manipulation benchmarks, as well as benchmarks of compositional instructions we introduce. We show our model can execute highly compositional instructions zero-shot in simulation and in the real world. It outperforms language-to-action reactive policies and Large Language Model planners by a large margin, especially for long instructions that involve compositions of multiple spatial concepts. Simulation and real-world robot execution videos, as well as our code and datasets are publicly available on our website: https://ebmplanner.github.io.