 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
Feb 02, 2026Achieving highly dynamic humanoid parkour on unseen, complex terrains remains a challenge in robotics. Although general locomotion policies demonstrate capabilities across broad terrain distributions, they often struggle with arbitrary and highly challenging environments. To overcome this limitation, we propose a real-to-sim-to-real framework that leverages rapid test-time training (TTT) on novel terrains, significantly enhancing the robot's capability to traverse extremely difficult geometries. We adopt a two-stage end-to-end learning paradigm: a policy is first pre-trained on diverse procedurally generated terrains, followed by rapid fine-tuning on high-fidelity meshes reconstructed from real-world captures. Specifically, we develop a feed-forward, efficient, and high-fidelity geometry reconstruction pipeline using RGB-D inputs, ensuring both speed and quality during test-time training. We demonstrate that TTT-Parkour empowers humanoid robots to master complex obstacles, including wedges, stakes, boxes, trapezoids, and narrow beams. The whole pipeline of capturing, reconstructing, and test-time training requires less than 10 minutes on most tested terrains. Extensive experiments show that the policy after test-time training exhibits robust zero-shot sim-to-real transfer capability.
Hiking in the Wild: A Scalable Perceptive Parkour Framework for Humanoids
Jan 12, 2026Achieving robust humanoid hiking in complex, unstructured environments requires transitioning from reactive proprioception to proactive perception. However, integrating exteroception remains a significant challenge: mapping-based methods suffer from state estimation drift; for instance, LiDAR-based methods do not handle torso jitter well. Existing end-to-end approaches often struggle with scalability and training complexity; specifically, some previous works using virtual obstacles are implemented case-by-case. In this work, we present \textit{Hiking in the Wild}, a scalable, end-to-end parkour perceptive framework designed for robust humanoid hiking. To ensure safety and training stability, we introduce two key mechanisms: a foothold safety mechanism combining scalable \textit{Terrain Edge Detection} with \textit{Foot Volume Points} to prevent catastrophic slippage on edges, and a \textit{Flat Patch Sampling} strategy that mitigates reward hacking by generating feasible navigation targets. Our approach utilizes a single-stage reinforcement learning scheme, mapping raw depth inputs and proprioception directly to joint actions, without relying on external state estimation. Extensive field experiments on a full-size humanoid demonstrate that our policy enables robust traversal of complex terrains at speeds up to 2.5 m/s. The training and deployment code is open-sourced to facilitate reproducible research and deployment on real robots with minimal hardware modifications.
Deep Whole-body Parkour
Jan 12, 2026Current approaches to humanoid control generally fall into two paradigms: perceptive locomotion, which handles terrain well but is limited to pedal gaits, and general motion tracking, which reproduces complex skills but ignores environmental capabilities. This work unites these paradigms to achieve perceptive general motion control. We present a framework where exteroceptive sensing is integrated into whole-body motion tracking, permitting a humanoid to perform highly dynamic, non-locomotion tasks on uneven terrain. By training a single policy to perform multiple distinct motions across varied terrestrial features, we demonstrate the non-trivial benefit of integrating perception into the control loop. Our results show that this framework enables robust, highly dynamic multi-contact motions, such as vaulting and dive-rolling, on unstructured terrain, significantly expanding the robot's traversability beyond simple walking or running. https://project-instinct.github.io/deep-whole-body-parkour
Embrace Collisions: Humanoid Shadowing for Deployable Contact-Agnostics Motions
Feb 03, 2025



Previous humanoid robot research works treat the robot as a bipedal mobile manipulation platform, where only the feet and hands contact the environment. However, we humans use all body parts to interact with the world, e.g., we sit in chairs, get up from the ground, or roll on the floor. Contacting the environment using body parts other than feet and hands brings significant challenges in both model-predictive control and reinforcement learning-based methods. An unpredictable contact sequence makes it almost impossible for model-predictive control to plan ahead in real time. The success of the zero-shot sim-to-real reinforcement learning method for humanoids heavily depends on the acceleration of GPU-based rigid-body physical simulator and simplification of the collision detection. Lacking extreme torso movement of the humanoid research makes all other components non-trivial to design, such as termination conditions, motion commands and reward designs. To address these potential challenges, we propose a general humanoid motion framework that takes discrete motion commands and controls the robot's motor action in real time. Using a GPU-accelerated rigid-body simulator, we train a humanoid whole-body control policy that follows the high-level motion command in the real world in real time, even with stochastic contacts and extremely large robot base rotation and not-so-feasible motion command. More details at https://project-instinct.github.io
Playful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion
Sep 30, 2024Quadrupedal animals have the ability to perform agile while accurate tasks: a trained dog can chase and catch a flying frisbee before it touches the ground; a cat alone at home can jump and grab the door handle accurately. However, agility and precision are usually a trade-off in robotics problems. Recent works in quadruped robots either focus on agile but not-so-accurate tasks, such as locomotion in challenging terrain, or accurate but not-so-fast tasks, such as using an additional manipulator to interact with objects. In this work, we aim at an accurate and agile task, catching a small object hanging above the robot. We mount a passive gripper in front of the robot chassis, so that the robot has to jump and catch the object with extreme precision. Our experiment shows that our system is able to jump and successfully catch the ball at 1.05m high in simulation and 0.8m high in the real world, while the robot is 0.3m high when standing.
Humanoid Parkour Learning
Jun 15, 2024



Parkour is a grand challenge for legged locomotion, even for quadruped robots, requiring active perception and various maneuvers to overcome multiple challenging obstacles. Existing methods for humanoid locomotion either optimize a trajectory for a single parkour track or train a reinforcement learning policy only to walk with a significant amount of motion references. In this work, we propose a framework for learning an end-to-end vision-based whole-body-control parkour policy for humanoid robots that overcomes multiple parkour skills without any motion prior. Using the parkour policy, the humanoid robot can jump on a 0.42m platform, leap over hurdles, 0.8m gaps, and much more. It can also run at 1.8m/s in the wild and walk robustly on different terrains. We test our policy in indoor and outdoor environments to demonstrate that it can autonomously select parkour skills while following the rotation command of the joystick. We override the arm actions and show that this framework can easily transfer to humanoid mobile manipulation tasks. Videos can be found at https://humanoid4parkour.github.io
Robot Parkour Learning
Sep 12, 2023



Parkour is a grand challenge for legged locomotion that requires robots to overcome various obstacles rapidly in complex environments. Existing methods can generate either diverse but blind locomotion skills or vision-based but specialized skills by using reference animal data or complex rewards. However, autonomous parkour requires robots to learn generalizable skills that are both vision-based and diverse to perceive and react to various scenarios. In this work, we propose a system for learning a single end-to-end vision-based parkour policy of diverse parkour skills using a simple reward without any reference motion data. We develop a reinforcement learning method inspired by direct collocation to generate parkour skills, including climbing over high obstacles, leaping over large gaps, crawling beneath low barriers, squeezing through thin slits, and running. We distill these skills into a single vision-based parkour policy and transfer it to a quadrupedal robot using its egocentric depth camera. We demonstrate that our system can empower two different low-cost robots to autonomously select and execute appropriate parkour skills to traverse challenging real-world environments.
SEMI: Self-supervised Exploration via Multisensory Incongruity
Sep 26, 2020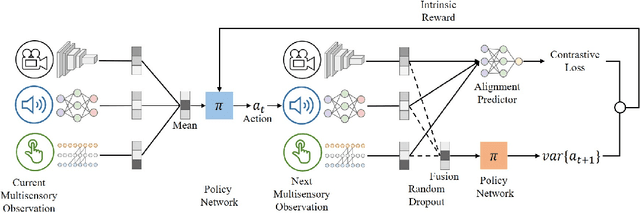
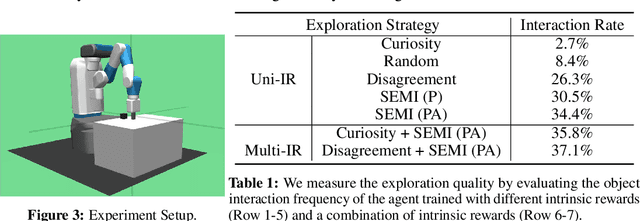
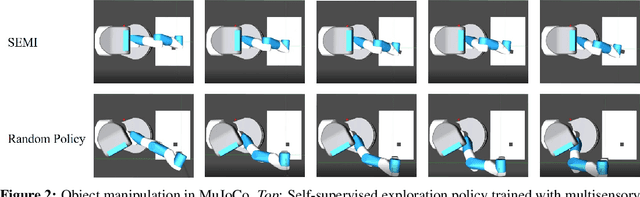
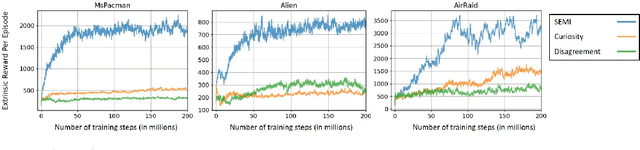
Efficient exploration is a long-standing problem in reinforcement learning. In this work, we introduce a self-supervised exploration policy by incentivizing the agent to maximize multisensory incongruity, which can be measured in two aspects: perception incongruity and action incongruity. The former represents the uncertainty in multisensory fusion model, while the latter represents the uncertainty in an agent's policy. Specifically, an alignment predictor is trained to detect whether multiple sensory inputs are aligned, the error of which is used to measure perception incongruity. The policy takes the multisensory observations with sensory-wise dropout as input and outputs actions for exploration. The variance of actions is further used to measure action incongruity. Our formulation allows the agent to learn skills by exploring in a self-supervised manner without any external rewards. Besides, our method enables the agent to learn a compact multimodal representation from hard examples, which further improves the sample efficiency of our policy learning. We demonstrate the efficacy of this formulation across a variety of benchmark environments including object manipulation and audio-visual games.