 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer-aided Colorization State-of-the-science: A Survey
Oct 03, 2024This paper reviews published research in the field of computer-aided colorization technology. We argue that the colorization task originates from computer graphics, prospers by introducing computer vision, and tends to the fusion of vision and graphics, so we put forward our taxonomy and organize the whole paper chronologically. We extend the existing reconstruction-based colorization evaluation techniques, considering that aesthetic assessment of colored images should be introduced to ensure that colorization satisfies human visual-related requirements and emotions more closely. We perform the colorization aesthetic assessment on seven representative unconditional colorization models and discuss the difference between our assessment and the existing reconstruction-based metrics. Finally, this paper identifies unresolved issues and proposes fruitful areas for future research and development. Access to the project associated with this survey can be obtained at https://github.com/DanielCho-HK/Colorization.
Playful DoggyBot: Learning Agile and Precise Quadrupedal Locomotion
Sep 30, 2024Quadrupedal animals have the ability to perform agile while accurate tasks: a trained dog can chase and catch a flying frisbee before it touches the ground; a cat alone at home can jump and grab the door handle accurately. However, agility and precision are usually a trade-off in robotics problems. Recent works in quadruped robots either focus on agile but not-so-accurate tasks, such as locomotion in challenging terrain, or accurate but not-so-fast tasks, such as using an additional manipulator to interact with objects. In this work, we aim at an accurate and agile task, catching a small object hanging above the robot. We mount a passive gripper in front of the robot chassis, so that the robot has to jump and catch the object with extreme precision. Our experiment shows that our system is able to jump and successfully catch the ball at 1.05m high in simulation and 0.8m high in the real world, while the robot is 0.3m high when standing.
LCCo: Lending CLIP to Co-Segmentation
Aug 22, 2023
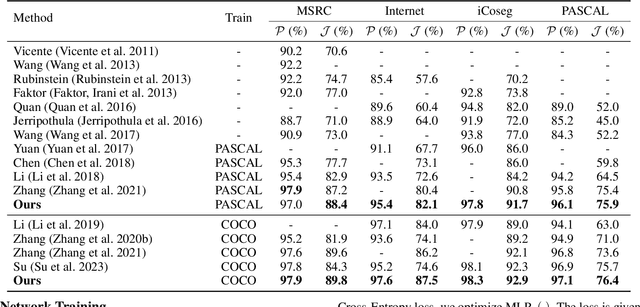

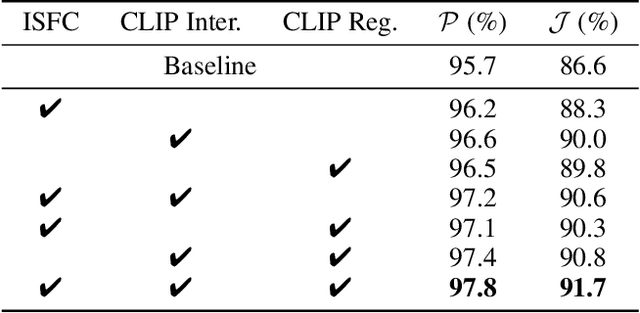
This paper studies co-segmenting the common semantic object in a set of images. Existing works either rely on carefully engineered networks to mine the implicit semantic information in visual features or require extra data (i.e., classification labels) for training. In this paper, we leverage the contrastive language-image pre-training framework (CLIP) for the task. With a backbone segmentation network that independently processes each image from the set, we introduce semantics from CLIP into the backbone features, refining them in a coarse-to-fine manner with three key modules: i) an image set feature correspondence module, encoding global consistent semantic information of the image set; ii) a CLIP interaction module, using CLIP-mined common semantics of the image set to refine the backbone feature; iii) a CLIP regularization module, drawing CLIP towards this co-segmentation task, identifying the best CLIP semantic and using it to regularize the backbone feature. Experiments on four standard co-segmentation benchmark datasets show that the performance of our method outperforms state-of-the-art methods.
RL-CoSeg : A Novel Image Co-Segmentation Algorithm with Deep Reinforcement Learning
Apr 12, 2022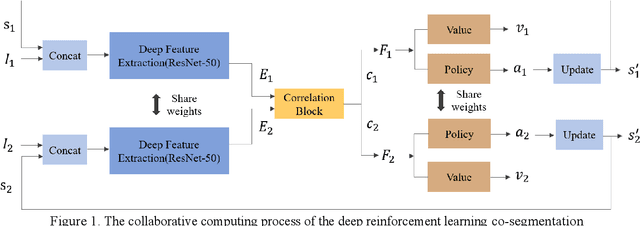
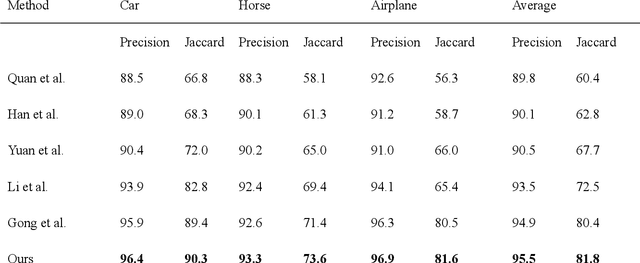
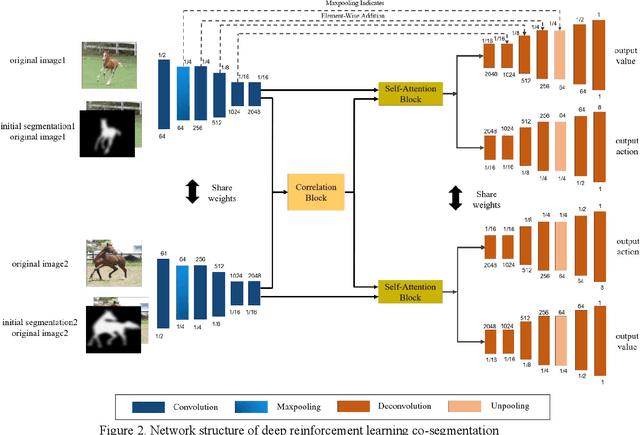
This paper proposes an automatic image co-segmentation algorithm based on deep reinforcement learning (RL). Existing co-segmentation tasks mainly rely on deep learning methods, and the obtained foreground edges are often rough. In order to obtain more precise foreground edges, we use deep RL to solve this problem and achieve the finer segmentation. To our best knowledge, this is the first work to apply RL methods to co-segmentation. We define the problem as a Markov Decision Process (MDP) and optimize it by RL with asynchronous advantage actor-critic (A3C). The RL image co-segmentation network uses the correlation between images to segment common and salient objects from a set of related images. In order to achieve automatic segmentation, our RL-CoSeg method eliminates user's hints. For the image co-segmentation problem, we propose a collaborative RL algorithm based on the A3C model. We propose a Siamese RL co-segmentation network structure to obtain the co-attention of images for co-segmentation. We improve the self-attention for automatic RL algorithm to obtain long-distance dependence and enlarge the receptive field. The image feature information obtained by self-attention can be used to supplement the deleted user's hints and help to obtain more accurate actions. Experimental results have shown that our method can improve the performance effectively on both coarse and fine initial segmentations, and it achieves the state-of-the-art performance on Internet dataset, iCoseg dataset and MLMR-COS dataset.
Mining the Weights Knowledge for Optimizing Neural Network Structures
Oct 11, 2021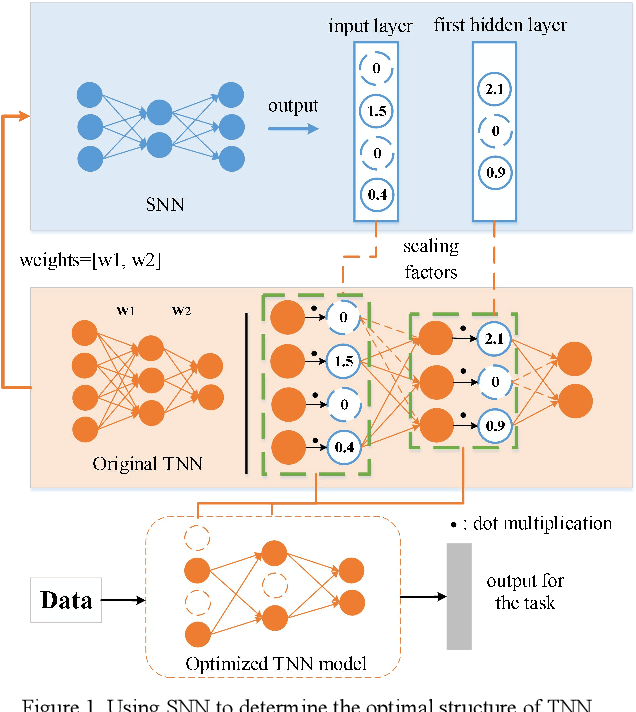
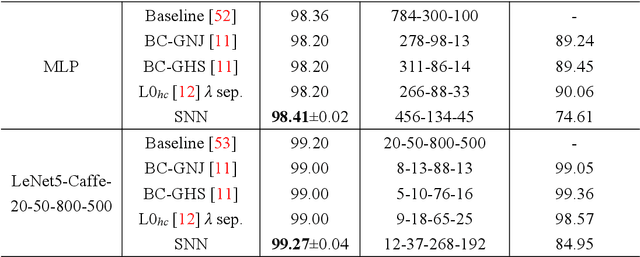
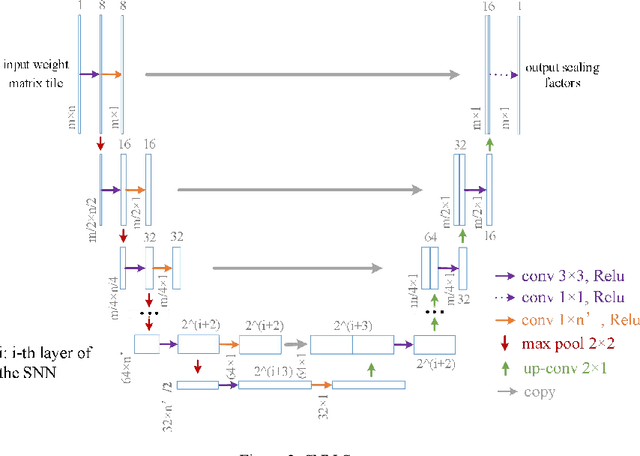
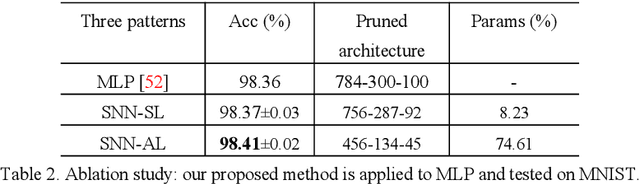
Knowledge embedded in the weights of the artificial neural network can be used to improve the network structure, such as in network compression. However, the knowledge is set up by hand, which may not be very accurate, and relevant information may be overlooked. Inspired by how learning works in the mammalian brain, we mine the knowledge contained in the weights of the neural network toward automatic architecture learning in this paper. We introduce a switcher neural network (SNN) that uses as inputs the weights of a task-specific neural network (called TNN for short). By mining the knowledge contained in the weights, the SNN outputs scaling factors for turning off and weighting neurons in the TNN. To optimize the structure and the parameters of TNN simultaneously, the SNN and TNN are learned alternately under the same performance evaluation of TNN using stochastic gradient descent. We test our method on widely used datasets and popular networks in classification applications. In terms of accuracy, we outperform baseline networks and other structure learning methods stably and significantly. At the same time, we compress the baseline networks without introducing any sparse induction mechanism, and our method, in particular, leads to a lower compression rate when dealing with simpler baselines or more difficult tasks. These results demonstrate that our method can produce a more reasonable structure.
HoloLens 2 Research Mode as a Tool for Computer Vision Research
Aug 25, 2020
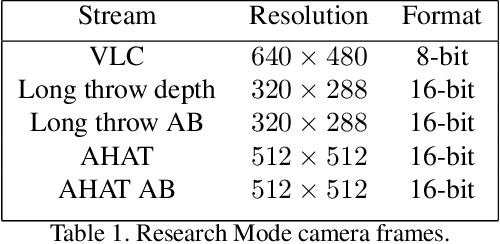


Mixed reality headsets, such as the Microsoft HoloLens 2, are powerful sensing devices with integrated compute capabilities, which makes it an ideal platform for computer vision research. In this technical report, we present HoloLens 2 Research Mode, an API and a set of tools enabling access to the raw sensor streams. We provide an overview of the API and explain how it can be used to build mixed reality applications based on processing sensor data. We also show how to combine the Research Mode sensor data with the built-in eye and hand tracking capabilities provided by HoloLens 2. By releasing the Research Mode API and a set of open-source tools, we aim to foster further research in the fields of computer vision as well as robotics and encourage contributions from the research community.
Automatic Image Co-Segmentation: A Survey
Nov 18, 2019

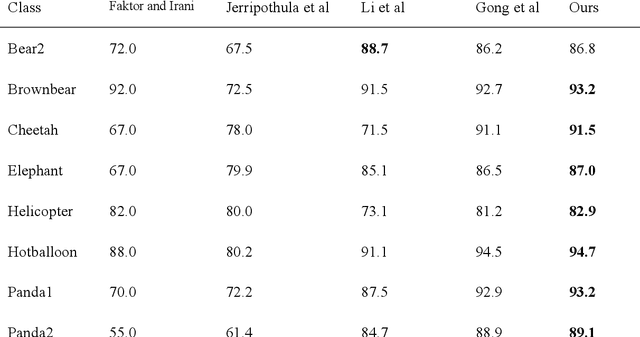
Image co-segmentation is important for its advantage of alleviating the ill-pose nature of image segmentation through exploring the correlation between related images. Many automatic image co-segmentation algorithms have been developed in the last decade, which are investigated comprehensively in this paper. We firstly analyze visual/semantic cues for guiding image co-segmentation, including object cues and correlation cues. Then we describe the traditional methods in three categories of object elements based, object regions/contours based, common object model based. In the next part, deep learning based methods are reviewed. Furthermore, widely used test datasets and evaluation criteria are introduced and the reported performances of the surveyed algorithms are compared with each other. Finally, we discuss the current challenges and possible future directions and conclude the paper. Hopefully, this comprehensive investigation will be helpful for the development of image co-segmentation technique.