 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLCCo: Lending CLIP to Co-Segmentation
Paper and Code
Aug 22, 2023
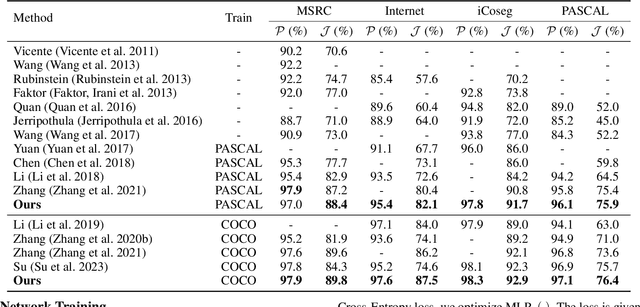

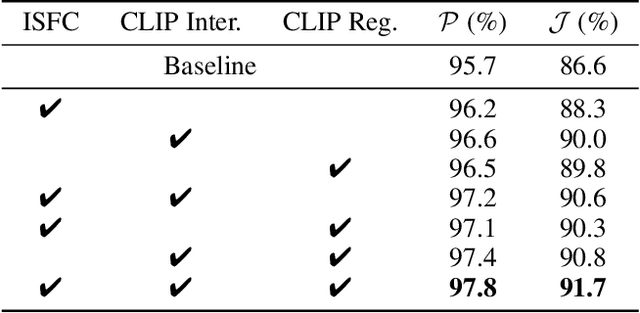
This paper studies co-segmenting the common semantic object in a set of images. Existing works either rely on carefully engineered networks to mine the implicit semantic information in visual features or require extra data (i.e., classification labels) for training. In this paper, we leverage the contrastive language-image pre-training framework (CLIP) for the task. With a backbone segmentation network that independently processes each image from the set, we introduce semantics from CLIP into the backbone features, refining them in a coarse-to-fine manner with three key modules: i) an image set feature correspondence module, encoding global consistent semantic information of the image set; ii) a CLIP interaction module, using CLIP-mined common semantics of the image set to refine the backbone feature; iii) a CLIP regularization module, drawing CLIP towards this co-segmentation task, identifying the best CLIP semantic and using it to regularize the backbone feature. Experiments on four standard co-segmentation benchmark datasets show that the performance of our method outperforms state-of-the-art methods.