 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGARA: A novel approach to Improve Genetic Algorithms' Accuracy and Efficiency by Utilizing Relationships among Genes
Apr 28, 2024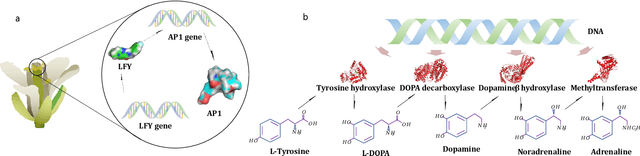
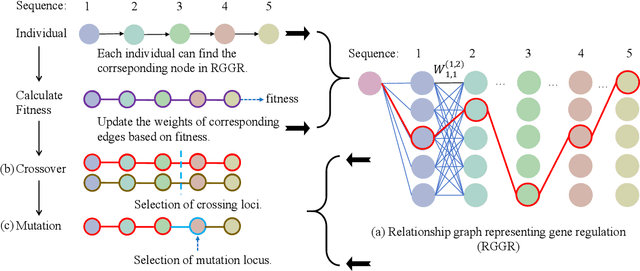
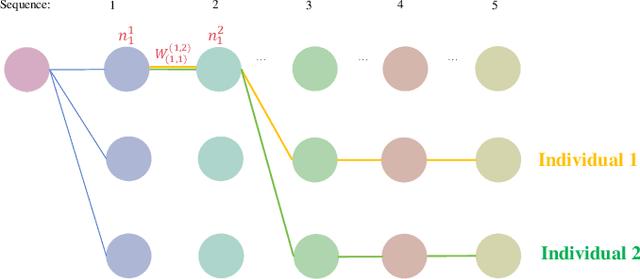
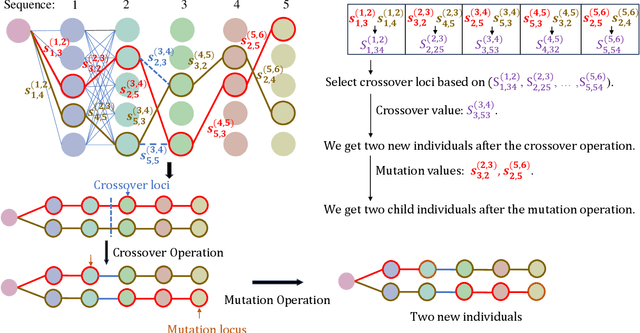
Genetic algorithms have played an important role in engineering optimization. Traditional GAs treat each gene separately. However, biophysical studies of gene regulatory networks revealed direct associations between different genes. It inspires us to propose an improvement to GA in this paper, Gene Regulatory Genetic Algorithm (GRGA), which, to our best knowledge, is the first time to utilize relationships among genes for improving GA's accuracy and efficiency. We design a directed multipartite graph encapsulating the solution space, called RGGR, where each node corresponds to a gene in the solution and the edge represents the relationship between adjacent nodes. The edge's weight reflects the relationship degree and is updated based on the idea that the edges' weights in a complete chain as candidate solution with acceptable or unacceptable performance should be strengthened or reduced, respectively. The obtained RGGR is then employed to determine appropriate loci of crossover and mutation operators, thereby directing the evolutionary process toward faster and better convergence. We analyze and validate our proposed GRGA approach in a single-objective multimodal optimization problem, and further test it on three types of applications, including feature selection, text summarization, and dimensionality reduction. Results illustrate that our GARA is effective and promising.
Generating meta-learning tasks to evolve parametric loss for classification learning
Nov 20, 2021


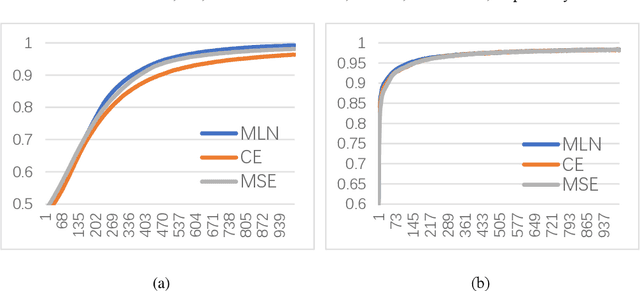
The field of meta-learning has seen a dramatic rise in interest in recent years. In existing meta-learning approaches, learning tasks for training meta-models are usually collected from public datasets, which brings the difficulty of obtaining a sufficient number of meta-learning tasks with a large amount of training data. In this paper, we propose a meta-learning approach based on randomly generated meta-learning tasks to obtain a parametric loss for classification learning based on big data. The loss is represented by a deep neural network, called meta-loss network (MLN). To train the MLN, we construct a large number of classification learning tasks through randomly generating training data, validation data, and corresponding ground-truth linear classifier. Our approach has two advantages. First, sufficient meta-learning tasks with large number of training data can be obtained easily. Second, the ground-truth classifier is given, so that the difference between the learned classifier and the ground-truth model can be measured to reflect the performance of MLN more precisely than validation accuracy. Based on this difference, we apply the evolutionary strategy algorithm to find out the optimal MLN. The resultant MLN not only leads to satisfactory learning effects on generated linear classifier learning tasks for testing, but also behaves very well on generated nonlinear classifier learning tasks and various public classification tasks. Our MLN stably surpass cross-entropy (CE) and mean square error (MSE) in testing accuracy and generalization ability. These results illustrate the possibility of achieving satisfactory meta-learning effects using generated learning tasks.
Mining the Weights Knowledge for Optimizing Neural Network Structures
Oct 11, 2021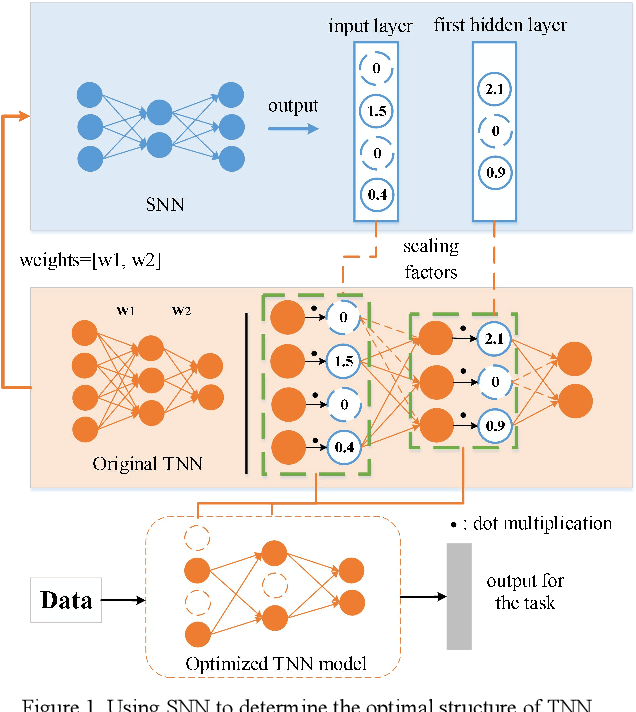
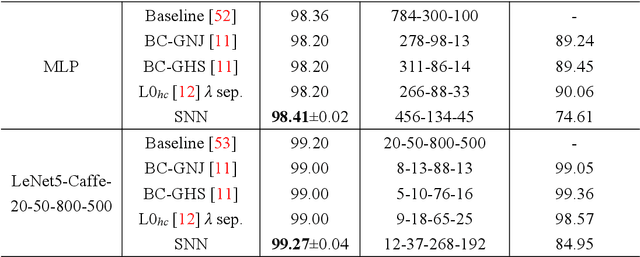
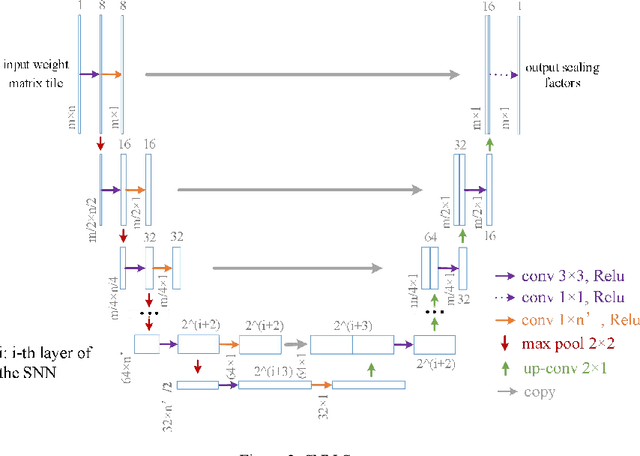
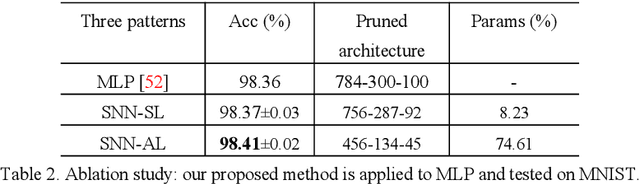
Knowledge embedded in the weights of the artificial neural network can be used to improve the network structure, such as in network compression. However, the knowledge is set up by hand, which may not be very accurate, and relevant information may be overlooked. Inspired by how learning works in the mammalian brain, we mine the knowledge contained in the weights of the neural network toward automatic architecture learning in this paper. We introduce a switcher neural network (SNN) that uses as inputs the weights of a task-specific neural network (called TNN for short). By mining the knowledge contained in the weights, the SNN outputs scaling factors for turning off and weighting neurons in the TNN. To optimize the structure and the parameters of TNN simultaneously, the SNN and TNN are learned alternately under the same performance evaluation of TNN using stochastic gradient descent. We test our method on widely used datasets and popular networks in classification applications. In terms of accuracy, we outperform baseline networks and other structure learning methods stably and significantly. At the same time, we compress the baseline networks without introducing any sparse induction mechanism, and our method, in particular, leads to a lower compression rate when dealing with simpler baselines or more difficult tasks. These results demonstrate that our method can produce a more reasonable structure.
Evolving parametrized Loss for Image Classification Learning on Small Datasets
Mar 15, 2021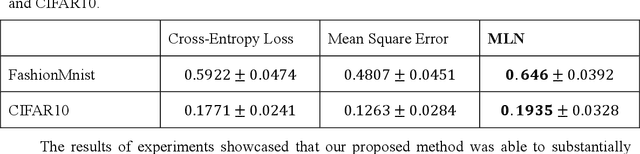
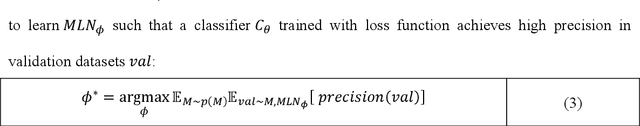
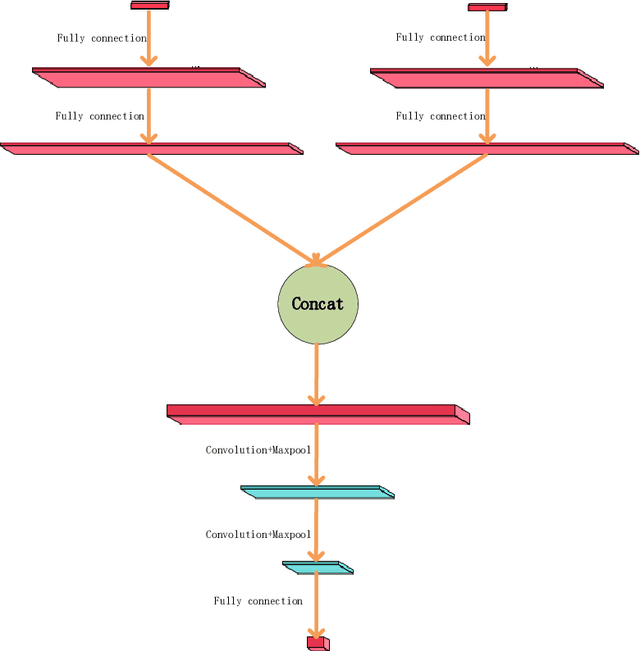
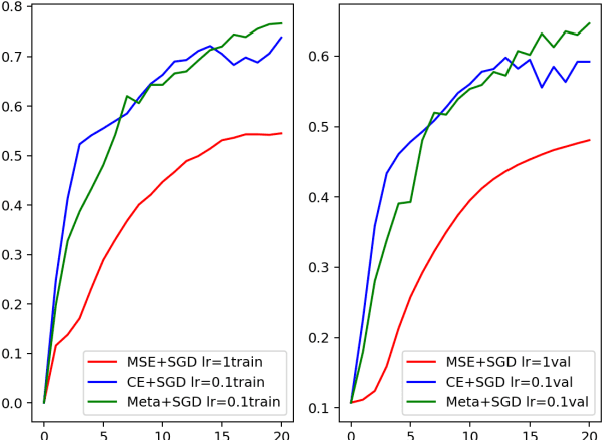
This paper proposes a meta-learning approach to evolving a parametrized loss function, which is called Meta-Loss Network (MLN), for training the image classification learning on small datasets. In our approach, the MLN is embedded in the framework of classification learning as a differentiable objective function. The MLN is evolved with the Evolutionary Strategy algorithm (ES) to an optimized loss function, such that a classifier, which optimized to minimize this loss, will achieve a good generalization effect. A classifier learns on a small training dataset to minimize MLN with Stochastic Gradient Descent (SGD), and then the MLN is evolved with the precision of the small-dataset-updated classifier on a large validation dataset. In order to evaluate our approach, the MLN is trained with a large number of small sample learning tasks sampled from FashionMNIST and tested on validation tasks sampled from FashionMNIST and CIFAR10. Experiment results demonstrate that the MLN effectively improved generalization compared to classical cross-entropy error and mean squared error.