 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating meta-learning tasks to evolve parametric loss for classification learning
Nov 20, 2021


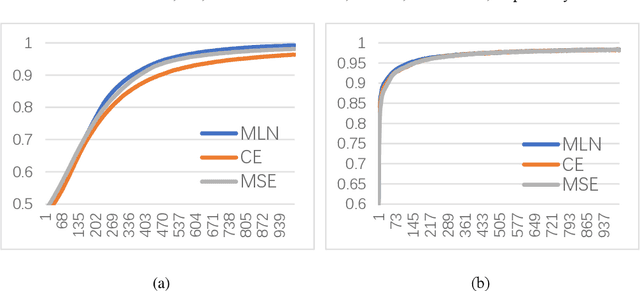
The field of meta-learning has seen a dramatic rise in interest in recent years. In existing meta-learning approaches, learning tasks for training meta-models are usually collected from public datasets, which brings the difficulty of obtaining a sufficient number of meta-learning tasks with a large amount of training data. In this paper, we propose a meta-learning approach based on randomly generated meta-learning tasks to obtain a parametric loss for classification learning based on big data. The loss is represented by a deep neural network, called meta-loss network (MLN). To train the MLN, we construct a large number of classification learning tasks through randomly generating training data, validation data, and corresponding ground-truth linear classifier. Our approach has two advantages. First, sufficient meta-learning tasks with large number of training data can be obtained easily. Second, the ground-truth classifier is given, so that the difference between the learned classifier and the ground-truth model can be measured to reflect the performance of MLN more precisely than validation accuracy. Based on this difference, we apply the evolutionary strategy algorithm to find out the optimal MLN. The resultant MLN not only leads to satisfactory learning effects on generated linear classifier learning tasks for testing, but also behaves very well on generated nonlinear classifier learning tasks and various public classification tasks. Our MLN stably surpass cross-entropy (CE) and mean square error (MSE) in testing accuracy and generalization ability. These results illustrate the possibility of achieving satisfactory meta-learning effects using generated learning tasks.