 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-CoSeg : A Novel Image Co-Segmentation Algorithm with Deep Reinforcement Learning
Apr 12, 2022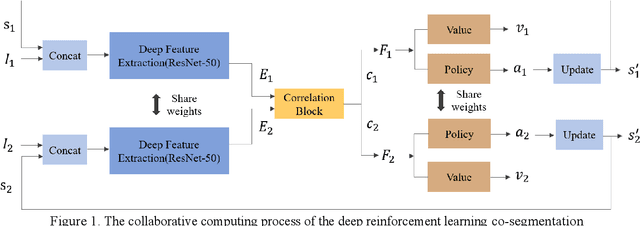
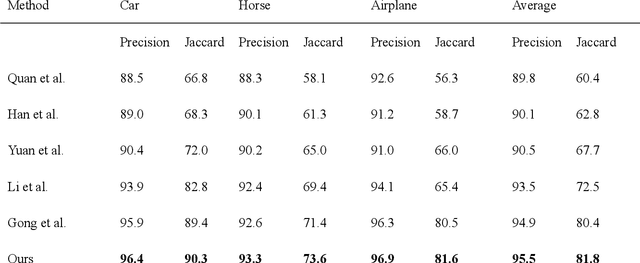
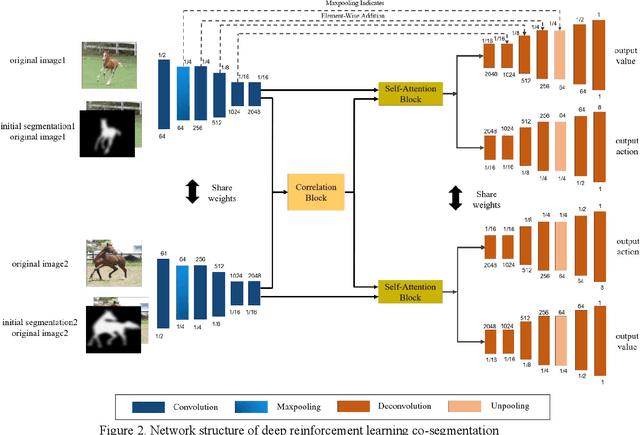
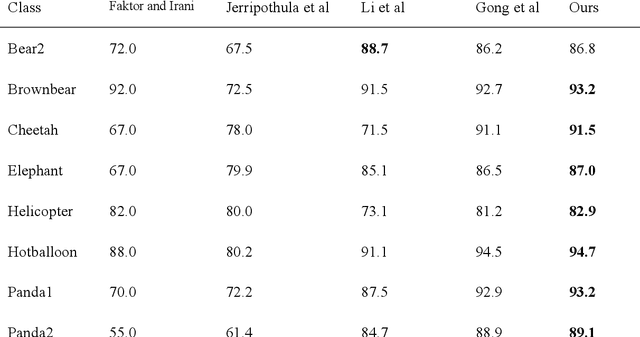
This paper proposes an automatic image co-segmentation algorithm based on deep reinforcement learning (RL). Existing co-segmentation tasks mainly rely on deep learning methods, and the obtained foreground edges are often rough. In order to obtain more precise foreground edges, we use deep RL to solve this problem and achieve the finer segmentation. To our best knowledge, this is the first work to apply RL methods to co-segmentation. We define the problem as a Markov Decision Process (MDP) and optimize it by RL with asynchronous advantage actor-critic (A3C). The RL image co-segmentation network uses the correlation between images to segment common and salient objects from a set of related images. In order to achieve automatic segmentation, our RL-CoSeg method eliminates user's hints. For the image co-segmentation problem, we propose a collaborative RL algorithm based on the A3C model. We propose a Siamese RL co-segmentation network structure to obtain the co-attention of images for co-segmentation. We improve the self-attention for automatic RL algorithm to obtain long-distance dependence and enlarge the receptive field. The image feature information obtained by self-attention can be used to supplement the deleted user's hints and help to obtain more accurate actions. Experimental results have shown that our method can improve the performance effectively on both coarse and fine initial segmentations, and it achieves the state-of-the-art performance on Internet dataset, iCoseg dataset and MLMR-COS dataset.
Mining the Weights Knowledge for Optimizing Neural Network Structures
Oct 11, 2021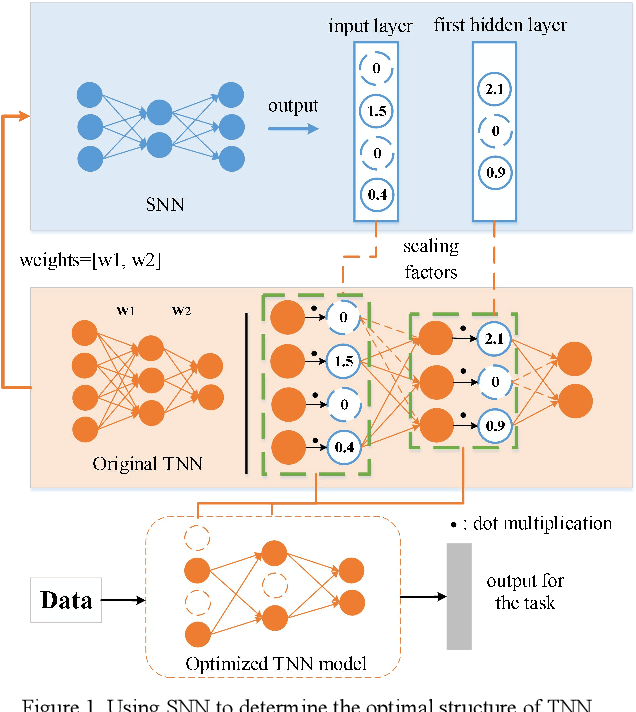
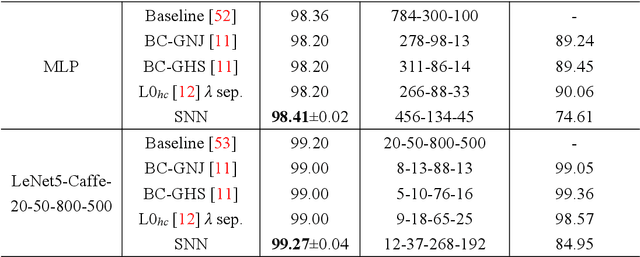
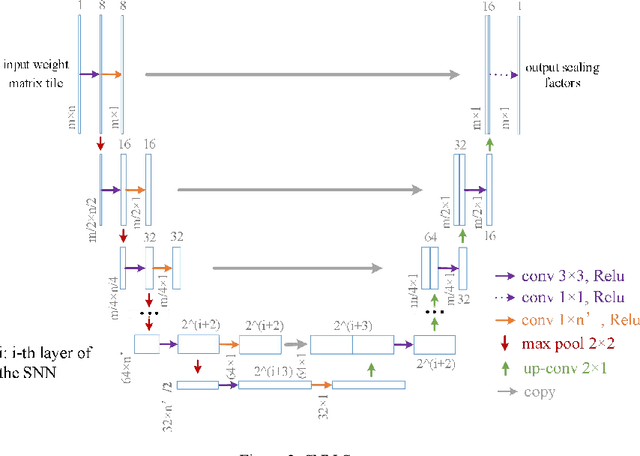
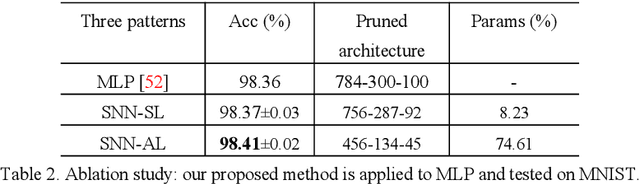
Knowledge embedded in the weights of the artificial neural network can be used to improve the network structure, such as in network compression. However, the knowledge is set up by hand, which may not be very accurate, and relevant information may be overlooked. Inspired by how learning works in the mammalian brain, we mine the knowledge contained in the weights of the neural network toward automatic architecture learning in this paper. We introduce a switcher neural network (SNN) that uses as inputs the weights of a task-specific neural network (called TNN for short). By mining the knowledge contained in the weights, the SNN outputs scaling factors for turning off and weighting neurons in the TNN. To optimize the structure and the parameters of TNN simultaneously, the SNN and TNN are learned alternately under the same performance evaluation of TNN using stochastic gradient descent. We test our method on widely used datasets and popular networks in classification applications. In terms of accuracy, we outperform baseline networks and other structure learning methods stably and significantly. At the same time, we compress the baseline networks without introducing any sparse induction mechanism, and our method, in particular, leads to a lower compression rate when dealing with simpler baselines or more difficult tasks. These results demonstrate that our method can produce a more reasonable structure.
Explore the Knowledge contained in Network Weights to Obtain Sparse Neural Networks
Mar 26, 2021

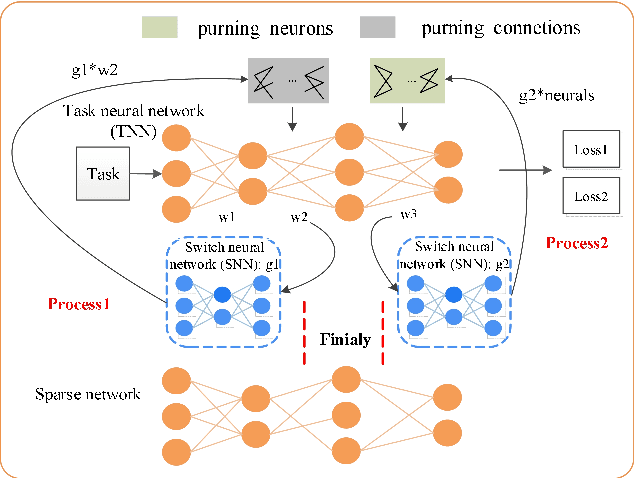

Sparse neural networks are important for achieving better generalization and enhancing computation efficiency. This paper proposes a novel learning approach to obtain sparse fully connected layers in neural networks (NNs) automatically. We design a switcher neural network (SNN) to optimize the structure of the task neural network (TNN). The SNN takes the weights of the TNN as the inputs and its outputs are used to switch the connections of TNN. In this way, the knowledge contained in the weights of TNN is explored to determine the importance of each connection and the structure of TNN consequently. The SNN and TNN are learned alternately with stochastic gradient descent (SGD) optimization, targeting at a common objective. After learning, we achieve the optimal structure and the optimal parameters of the TNN simultaneously. In order to evaluate the proposed approach, we conduct image classification experiments on various network structures and datasets. The network structures include LeNet, ResNet18, ResNet34, VggNet16 and MobileNet. The datasets include MNIST, CIFAR10 and CIFAR100. The experimental results show that our approach can stably lead to sparse and well-performing fully connected layers in NNs.