 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Diffusion Sequence Copilots for Shared Autonomy
Mar 24, 2026Shared autonomy combines human user and AI copilot actions to control complex systems such as robotic arms. When a task is challenging, requires high dimensional control, or is subject to corruption, shared autonomy can significantly increase task performance by using a trained copilot to effectively correct user actions in a manner consistent with the user's goals. To significantly improve the performance of shared autonomy, we introduce Diffusion Sequence Copilots (DiSCo): a method of shared autonomy with diffusion policy that plans action sequences consistent with past user actions. DiSCo seeds and inpaints the diffusion process with user-provided actions with hyperparameters to balance conformity to expert actions, alignment with user intent, and perceived responsiveness. We demonstrate that DiSCo substantially improves task performance in simulated driving and robotic arm tasks. Project website: https://sites.google.com/view/disco-shared-autonomy/
Redatuming physical systems using symmetric autoencoders
Aug 05, 2021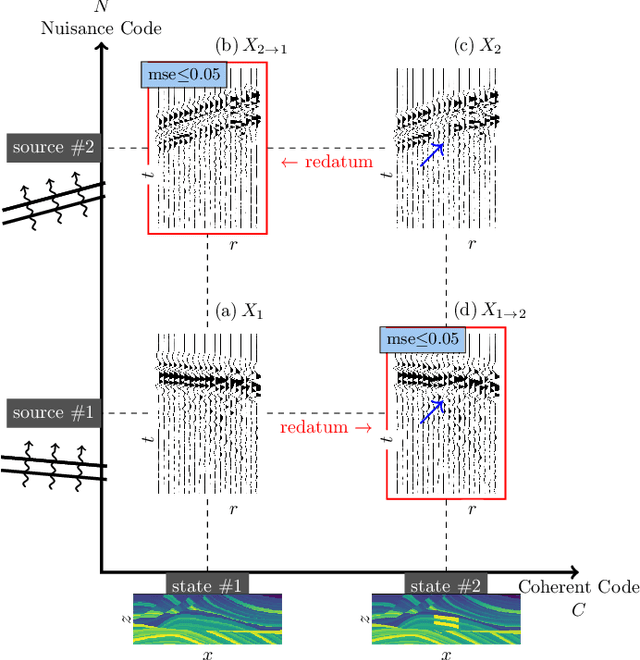
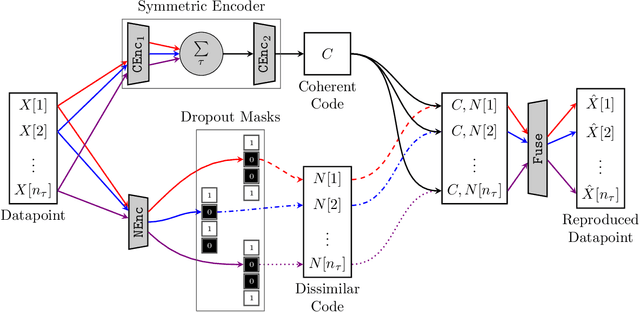


This paper considers physical systems described by hidden states and indirectly observed through repeated measurements corrupted by unmodeled nuisance parameters. A network-based representation learns to disentangle the coherent information (relative to the state) from the incoherent nuisance information (relative to the sensing). Instead of physical models, the representation uses symmetry and stochastic regularization to inform an autoencoder architecture called SymAE. It enables redatuming, i.e., creating virtual data instances where the nuisances are uniformized across measurements.
Accurate and Robust Deep Learning Framework for Solving Wave-Based Inverse Problems in the Super-Resolution Regime
Jun 02, 2021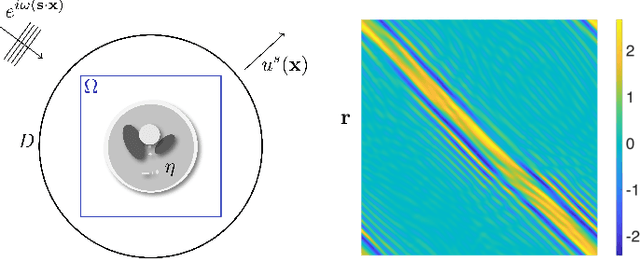
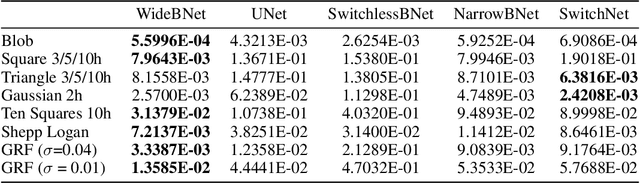


We propose an end-to-end deep learning framework that comprehensively solves the inverse wave scattering problem across all length scales. Our framework consists of the newly introduced wide-band butterfly network coupled with a simple training procedure that dynamically injects noise during training. While our trained network provides competitive results in classical imaging regimes, most notably it also succeeds in the super-resolution regime where other comparable methods fail. This encompasses both (i) reconstruction of scatterers with sub-wavelength geometric features, and (ii) accurate imaging when two or more scatterers are separated by less than the classical diffraction limit. We demonstrate these properties are retained even in the presence of strong noise and extend to scatterers not previously seen in the training set. In addition, our network is straightforward to train requiring no restarts and has an online runtime that is an order of magnitude faster than optimization-based algorithms. We perform experiments with a variety of wave scattering mediums and we demonstrate that our proposed framework outperforms both classical inversion and competing network architectures that specialize in oscillatory wave scattering data.
Wide-band butterfly network: stable and efficient inversion via multi-frequency neural networks
Nov 24, 2020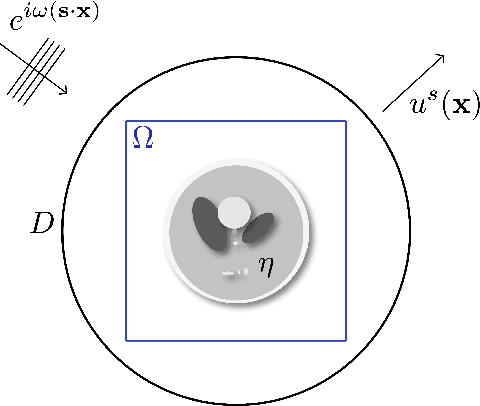
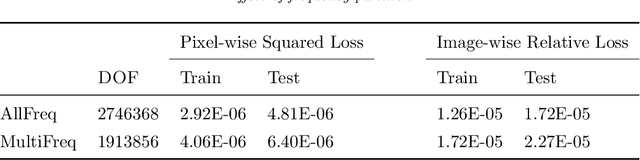

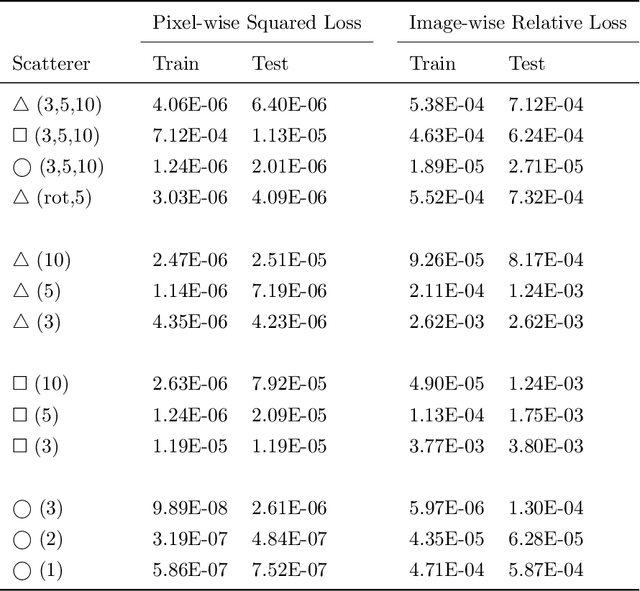
We introduce an end-to-end deep learning architecture called the wide-band butterfly network (WideBNet) for approximating the inverse scattering map from wide-band scattering data. This architecture incorporates tools from computational harmonic analysis, such as the butterfly factorization, and traditional multi-scale methods, such as the Cooley-Tukey FFT algorithm, to drastically reduce the number of trainable parameters to match the inherent complexity of the problem. As a result WideBNet is efficient: it requires fewer training points than off-the-shelf architectures, and has stable training dynamics, thus it can rely on standard weight initialization strategies. The architecture automatically adapts to the dimensions of the data with only a few hyper-parameters that the user must specify. WideBNet is able to produce images that are competitive with optimization-based approaches, but at a fraction of the cost, and we also demonstrate numerically that it learns to super-resolve scatterers in the full aperture scattering setup.
Towards Trainable Saliency Maps in Medical Imaging
Nov 15, 2020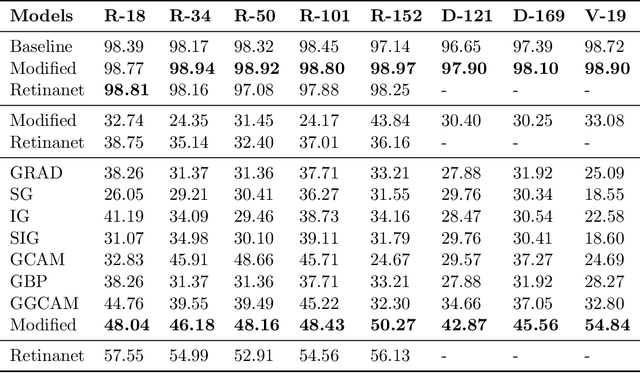
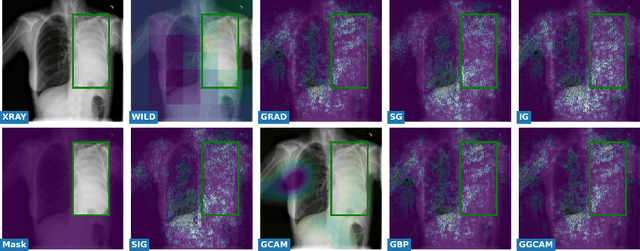
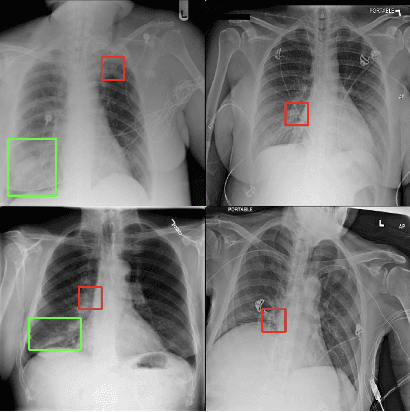
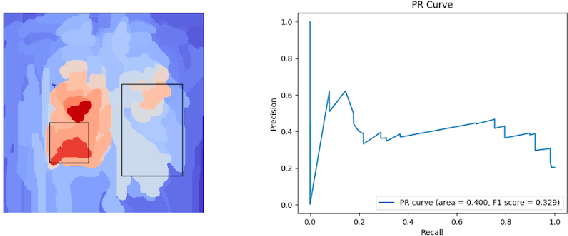
While success of Deep Learning (DL) in automated diagnosis can be transformative to the medicinal practice especially for people with little or no access to doctors, its widespread acceptability is severely limited by inherent black-box decision making and unsafe failure modes. While saliency methods attempt to tackle this problem in non-medical contexts, their apriori explanations do not transfer well to medical usecases. With this study we validate a model design element agnostic to both architecture complexity and model task, and show how introducing this element gives an inherently self-explanatory model. We compare our results with state of the art non-trainable saliency maps on RSNA Pneumonia Dataset and demonstrate a much higher localization efficacy using our adopted technique. We also compare, with a fully supervised baseline and provide a reasonable alternative to it's high data labelling overhead. We further investigate the validity of our claims through qualitative evaluation from an expert reader.