 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Seismic Inversion Through Integrated Importance Sampling and Ensemble Methods
Sep 10, 2024Seismic inversion is essential for geophysical exploration and geological assessment, but it is inherently subject to significant uncertainty. This uncertainty stems primarily from the limited information provided by observed seismic data, which is largely a result of constraints in data collection geometry. As a result, multiple plausible velocity models can often explain the same set of seismic observations. In deep learning-based seismic inversion, uncertainty arises from various sources, including data noise, neural network design and training, and inherent data limitations. This study introduces a novel approach to uncertainty quantification in seismic inversion by integrating ensemble methods with importance sampling. By leveraging ensemble approach in combination with importance sampling, we enhance the accuracy of uncertainty analysis while maintaining computational efficiency. The method involves initializing each model in the ensemble with different weights, introducing diversity in predictions and thereby improving the robustness and reliability of the inversion outcomes. Additionally, the use of importance sampling weights the contribution of each ensemble sample, allowing us to use a limited number of ensemble samples to obtain more accurate estimates of the posterior distribution. Our approach enables more precise quantification of uncertainty in velocity models derived from seismic data. By utilizing a limited number of ensemble samples, this method achieves an accurate and reliable assessment of uncertainty, ultimately providing greater confidence in seismic inversion results.
Redatuming physical systems using symmetric autoencoders
Aug 05, 2021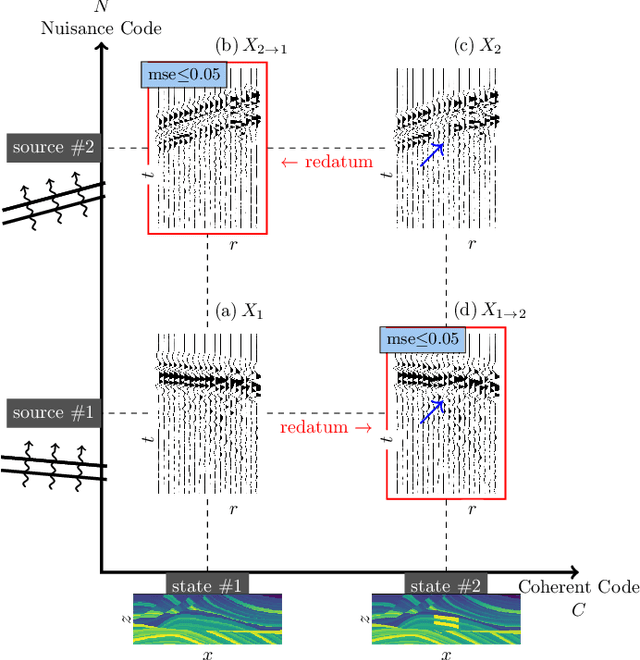
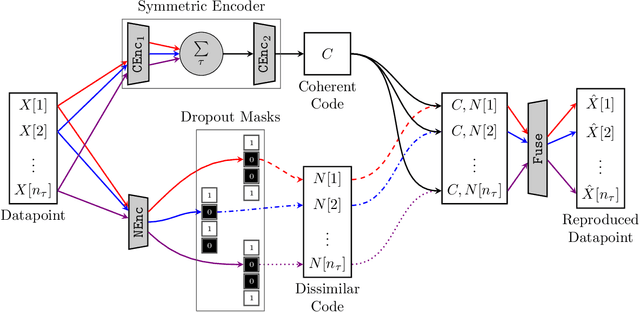


This paper considers physical systems described by hidden states and indirectly observed through repeated measurements corrupted by unmodeled nuisance parameters. A network-based representation learns to disentangle the coherent information (relative to the state) from the incoherent nuisance information (relative to the sensing). Instead of physical models, the representation uses symmetry and stochastic regularization to inform an autoencoder architecture called SymAE. It enables redatuming, i.e., creating virtual data instances where the nuisances are uniformized across measurements.
Accurate and Robust Deep Learning Framework for Solving Wave-Based Inverse Problems in the Super-Resolution Regime
Jun 02, 2021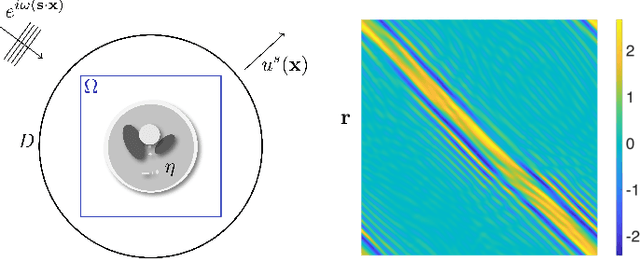


We propose an end-to-end deep learning framework that comprehensively solves the inverse wave scattering problem across all length scales. Our framework consists of the newly introduced wide-band butterfly network coupled with a simple training procedure that dynamically injects noise during training. While our trained network provides competitive results in classical imaging regimes, most notably it also succeeds in the super-resolution regime where other comparable methods fail. This encompasses both (i) reconstruction of scatterers with sub-wavelength geometric features, and (ii) accurate imaging when two or more scatterers are separated by less than the classical diffraction limit. We demonstrate these properties are retained even in the presence of strong noise and extend to scatterers not previously seen in the training set. In addition, our network is straightforward to train requiring no restarts and has an online runtime that is an order of magnitude faster than optimization-based algorithms. We perform experiments with a variety of wave scattering mediums and we demonstrate that our proposed framework outperforms both classical inversion and competing network architectures that specialize in oscillatory wave scattering data.
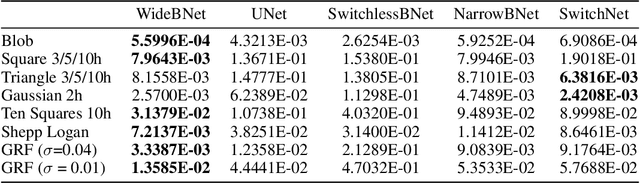
Wide-band butterfly network: stable and efficient inversion via multi-frequency neural networks
Nov 24, 2020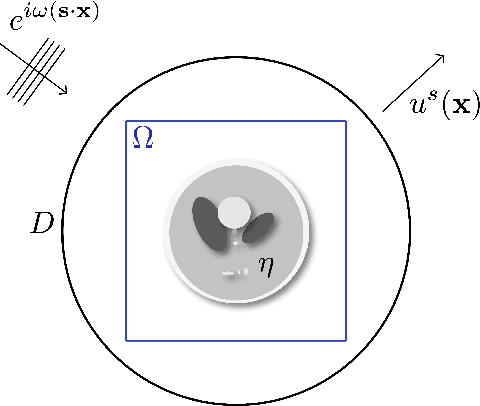
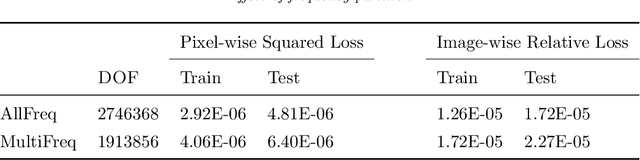

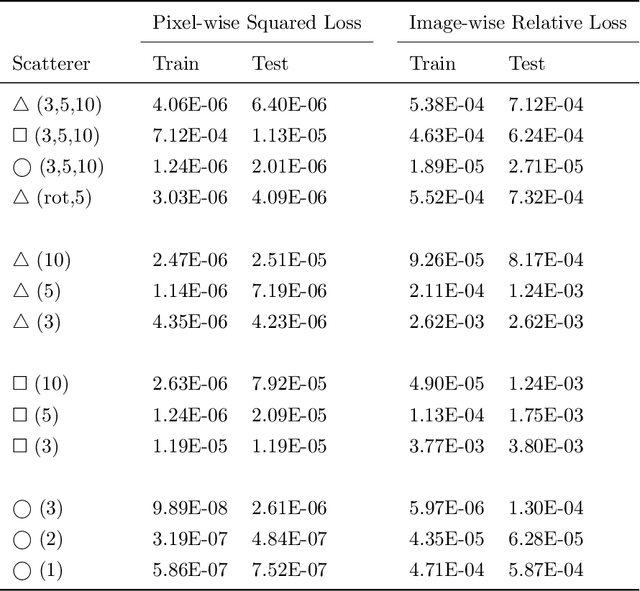
We introduce an end-to-end deep learning architecture called the wide-band butterfly network (WideBNet) for approximating the inverse scattering map from wide-band scattering data. This architecture incorporates tools from computational harmonic analysis, such as the butterfly factorization, and traditional multi-scale methods, such as the Cooley-Tukey FFT algorithm, to drastically reduce the number of trainable parameters to match the inherent complexity of the problem. As a result WideBNet is efficient: it requires fewer training points than off-the-shelf architectures, and has stable training dynamics, thus it can rely on standard weight initialization strategies. The architecture automatically adapts to the dimensions of the data with only a few hyper-parameters that the user must specify. WideBNet is able to produce images that are competitive with optimization-based approaches, but at a fraction of the cost, and we also demonstrate numerically that it learns to super-resolve scatterers in the full aperture scattering setup.