 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Feature Prompting of Image Segmentation Models
May 27, 2025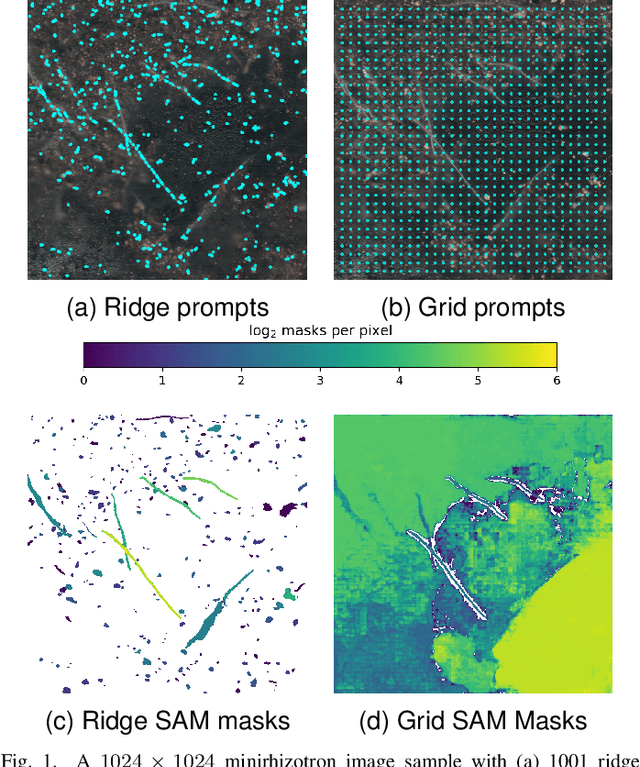

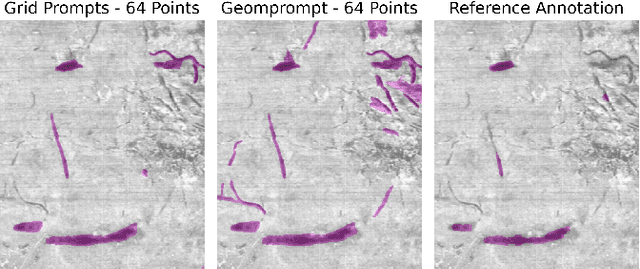
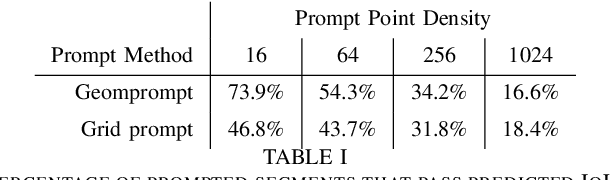
Advances in machine learning, especially the introduction of transformer architectures and vision transformers, have led to the development of highly capable computer vision foundation models. The segment anything model (known colloquially as SAM and more recently SAM 2), is a highly capable foundation model for segmentation of natural images and has been further applied to medical and scientific image segmentation tasks. SAM relies on prompts -- points or regions of interest in an image -- to generate associated segmentations. In this manuscript we propose the use of a geometrically motivated prompt generator to produce prompt points that are colocated with particular features of interest. Focused prompting enables the automatic generation of sensitive and specific segmentations in a scientific image analysis task using SAM with relatively few point prompts. The image analysis task examined is the segmentation of plant roots in rhizotron or minirhizotron images, which has historically been a difficult task to automate. Hand annotation of rhizotron images is laborious and often subjective; SAM, initialized with GeomPrompt local ridge prompts has the potential to dramatically improve rhizotron image processing. The authors have concurrently released an open source software suite called geomprompt https://pypi.org/project/geomprompt/ that can produce point prompts in a format that enables direct integration with the segment-anything package.
Your Interest, Your Summaries: Query-Focused Long Video Summarization
Oct 17, 2024Generating a concise and informative video summary from a long video is important, yet subjective due to varying scene importance. Users' ability to specify scene importance through text queries enhances the relevance of such summaries. This paper introduces an approach for query-focused video summarization, aiming to align video summaries closely with user queries. To this end, we propose the Fully Convolutional Sequence Network with Attention (FCSNA-QFVS), a novel approach designed for this task. Leveraging temporal convolutional and attention mechanisms, our model effectively extracts and highlights relevant content based on user-specified queries. Experimental validation on a benchmark dataset for query-focused video summarization demonstrates the effectiveness of our approach.
Topological Parallax: A Geometric Specification for Deep Perception Models
Jun 20, 2023

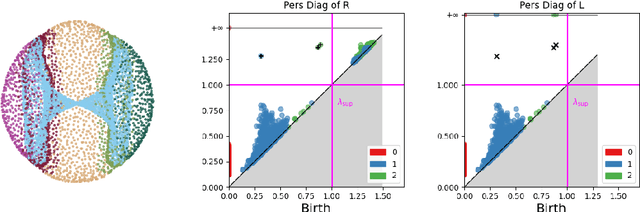

For safety and robustness of AI systems, we introduce topological parallax as a theoretical and computational tool that compares a trained model to a reference dataset to determine whether they have similar multiscale geometric structure. Our proofs and examples show that this geometric similarity between dataset and model is essential to trustworthy interpolation and perturbation, and we conjecture that this new concept will add value to the current debate regarding the unclear relationship between overfitting and generalization in applications of deep-learning. In typical DNN applications, an explicit geometric description of the model is impossible, but parallax can estimate topological features (components, cycles, voids, etc.) in the model by examining the effect on the Rips complex of geodesic distortions using the reference dataset. Thus, parallax indicates whether the model shares similar multiscale geometric features with the dataset. Parallax presents theoretically via topological data analysis [TDA] as a bi-filtered persistence module, and the key properties of this module are stable under perturbation of the reference dataset.
xView3-SAR: Detecting Dark Fishing Activity Using Synthetic Aperture Imagery
Jun 02, 2022
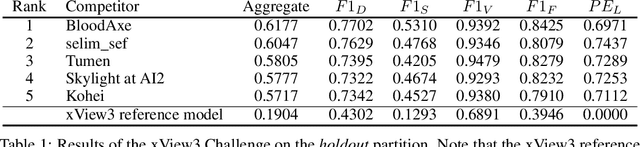

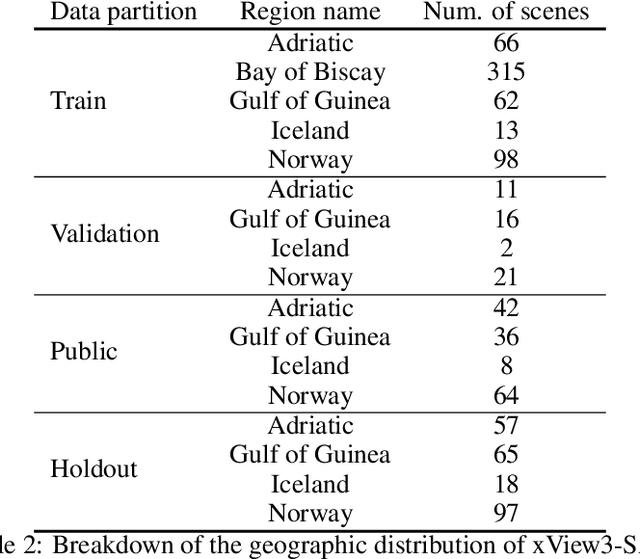
Unsustainable fishing practices worldwide pose a major threat to marine resources and ecosystems. Identifying vessels that evade monitoring systems -- known as "dark vessels" -- is key to managing and securing the health of marine environments. With the rise of satellite-based synthetic aperture radar (SAR) imaging and modern machine learning (ML), it is now possible to automate detection of dark vessels day or night, under all-weather conditions. SAR images, however, require domain-specific treatment and is not widely accessible to the ML community. Moreover, the objects (vessels) are small and sparse, challenging traditional computer vision approaches. We present the largest labeled dataset for training ML models to detect and characterize vessels from SAR. xView3-SAR consists of nearly 1,000 analysis-ready SAR images from the Sentinel-1 mission that are, on average, 29,400-by-24,400 pixels each. The images are annotated using a combination of automated and manual analysis. Co-located bathymetry and wind state rasters accompany every SAR image. We provide an overview of the results from the xView3 Computer Vision Challenge, an international competition using xView3-SAR for ship detection and characterization at large scale. We release the data (https://iuu.xview.us/) and code (https://github.com/DIUx-xView) to support ongoing development and evaluation of ML approaches for this important application.
xBD: A Dataset for Assessing Building Damage from Satellite Imagery
Nov 21, 2019
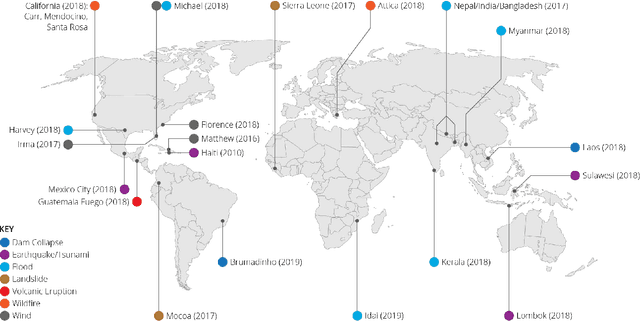
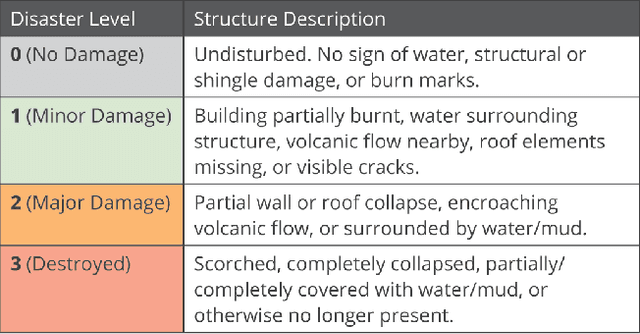

We present xBD, a new, large-scale dataset for the advancement of change detection and building damage assessment for humanitarian assistance and disaster recovery research. Natural disaster response requires an accurate understanding of damaged buildings in an affected region. Current response strategies require in-person damage assessments within 24-48 hours of a disaster. Massive potential exists for using aerial imagery combined with computer vision algorithms to assess damage and reduce the potential danger to human life. In collaboration with multiple disaster response agencies, xBD provides pre- and post-event satellite imagery across a variety of disaster events with building polygons, ordinal labels of damage level, and corresponding satellite metadata. Furthermore, the dataset contains bounding boxes and labels for environmental factors such as fire, water, and smoke. xBD is the largest building damage assessment dataset to date, containing 850,736 building annotations across 45,362 km\textsuperscript{2} of imagery.