 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple but Tough-to-Beat Data Augmentation Approach for Natural Language Understanding and Generation
Oct 23, 2020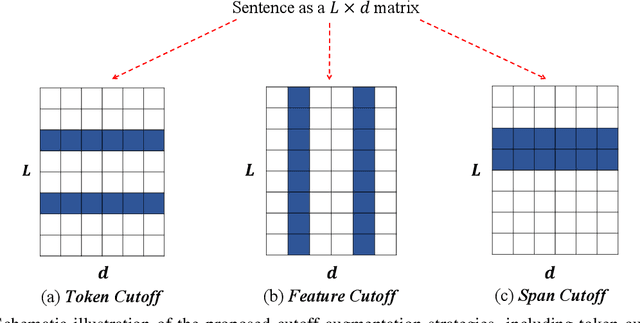
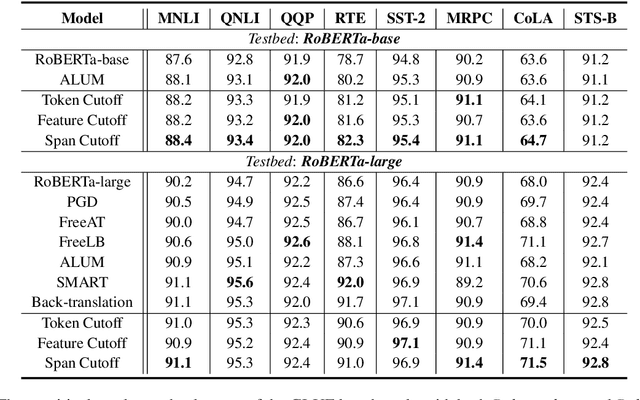

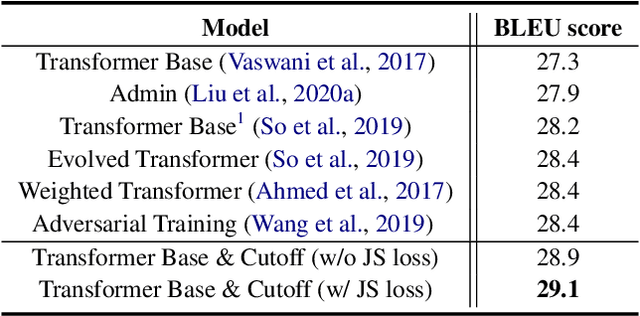
Adversarial training has been shown effective at endowing the learned representations with stronger generalization ability. However, it typically requires expensive computation to determine the direction of the injected perturbations. In this paper, we introduce a set of simple yet effective data augmentation strategies dubbed cutoff, where part of the information within an input sentence is erased to yield its restricted views (during the fine-tuning stage). Notably, this process relies merely on stochastic sampling and thus adds little computational overhead. A Jensen-Shannon Divergence consistency loss is further utilized to incorporate these augmented samples into the training objective in a principled manner. To verify the effectiveness of the proposed strategies, we apply cutoff to both natural language understanding and generation problems. On the GLUE benchmark, it is demonstrated that cutoff, in spite of its simplicity, performs on par or better than several competitive adversarial-based approaches. We further extend cutoff to machine translation and observe significant gains in BLEU scores (based upon the Transformer Base model). Moreover, cutoff consistently outperforms adversarial training and achieves state-of-the-art results on the IWSLT2014 German-English dataset.
Improving Self-supervised Pre-training via a Fully-Explored Masked Language Model
Oct 14, 2020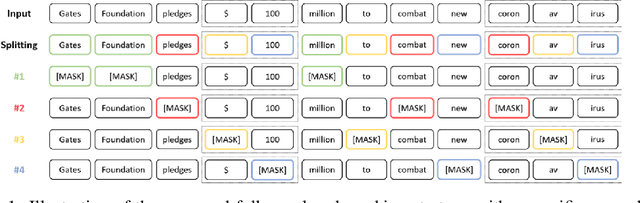
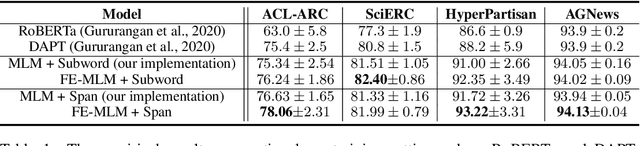
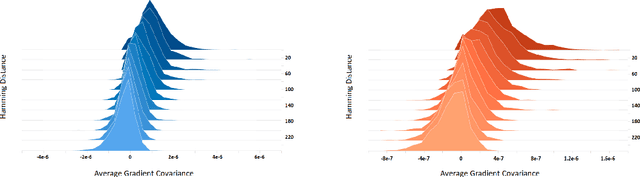

Masked Language Model (MLM) framework has been widely adopted for self-supervised language pre-training. In this paper, we argue that randomly sampled masks in MLM would lead to undesirably large gradient variance. Thus, we theoretically quantify the gradient variance via correlating the gradient covariance with the Hamming distance between two different masks (given a certain text sequence). To reduce the variance due to the sampling of masks, we propose a fully-explored masking strategy, where a text sequence is divided into a certain number of non-overlapping segments. Thereafter, the tokens within one segment are masked for training. We prove, from a theoretical perspective, that the gradients derived from this new masking schema have a smaller variance and can lead to more efficient self-supervised training. We conduct extensive experiments on both continual pre-training and general pre-training from scratch. Empirical results confirm that this new masking strategy can consistently outperform standard random masking. Detailed efficiency analysis and ablation studies further validate the advantages of our fully-explored masking strategy under the MLM framework.