 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Free Guided Flow Matching with Optimal Control
Oct 23, 2024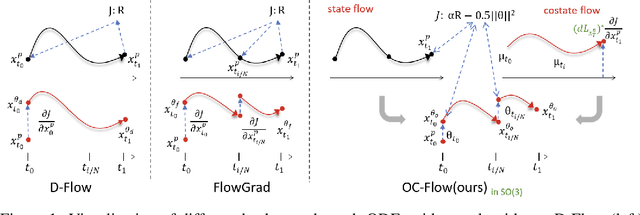


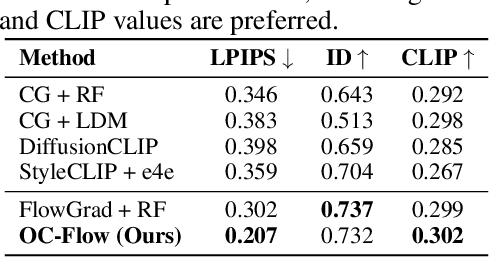
Controlled generation with pre-trained Diffusion and Flow Matching models has vast applications. One strategy for guiding ODE-based generative models is through optimizing a target loss $R(x_1)$ while staying close to the prior distribution. Along this line, some recent work showed the effectiveness of guiding flow model by differentiating through its ODE sampling process. Despite the superior performance, the theoretical understanding of this line of methods is still preliminary, leaving space for algorithm improvement. Moreover, existing methods predominately focus on Euclidean data manifold, and there is a compelling need for guided flow methods on complex geometries such as SO(3), which prevails in high-stake scientific applications like protein design. We present OC-Flow, a general and theoretically grounded training-free framework for guided flow matching using optimal control. Building upon advances in optimal control theory, we develop effective and practical algorithms for solving optimal control in guided ODE-based generation and provide a systematic theoretical analysis of the convergence guarantee in both Euclidean and SO(3). We show that existing backprop-through-ODE methods can be interpreted as special cases of Euclidean OC-Flow. OC-Flow achieved superior performance in extensive experiments on text-guided image manipulation, conditional molecule generation, and all-atom peptide design.
An Information-Theoretic Approach to Analyze NLP Classification Tasks
Feb 01, 2024Understanding the importance of the inputs on the output is useful across many tasks. This work provides an information-theoretic framework to analyse the influence of inputs for text classification tasks. Natural language processing (NLP) tasks take either a single element input or multiple element inputs to predict an output variable, where an element is a block of text. Each text element has two components: an associated semantic meaning and a linguistic realization. Multiple-choice reading comprehension (MCRC) and sentiment classification (SC) are selected to showcase the framework. For MCRC, it is found that the context influence on the output compared to the question influence reduces on more challenging datasets. In particular, more challenging contexts allow a greater variation in complexity of questions. Hence, test creators need to carefully consider the choice of the context when designing multiple-choice questions for assessment. For SC, it is found the semantic meaning of the input text dominates (above 80\% for all datasets considered) compared to its linguistic realisation when determining the sentiment. The framework is made available at: https://github.com/WangLuran/nlp-element-influence