 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Bi-manipulation using RGBD Multi-model Fusion based on Attention Mechanism
Paper and Code
Apr 27, 2024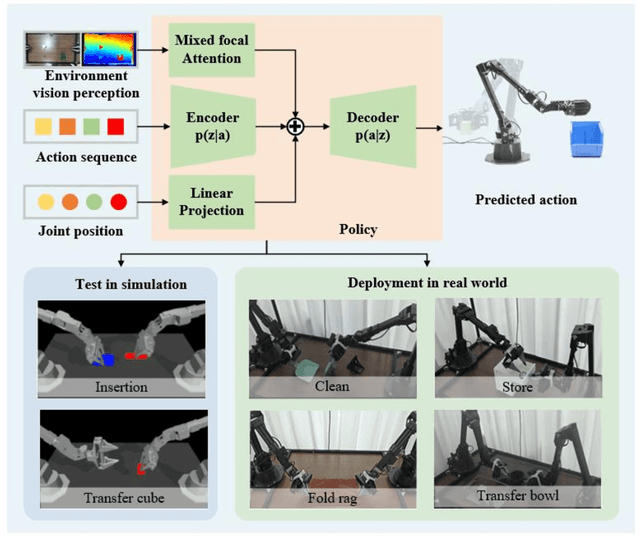
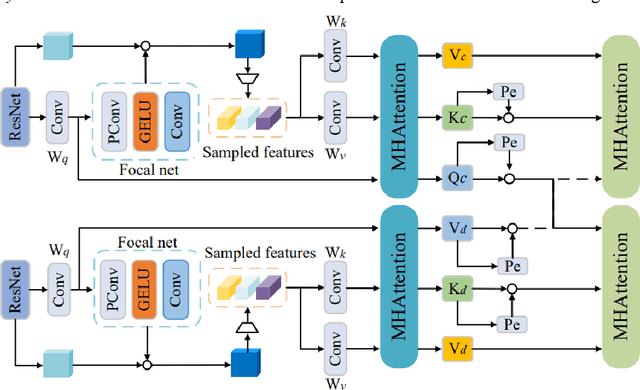
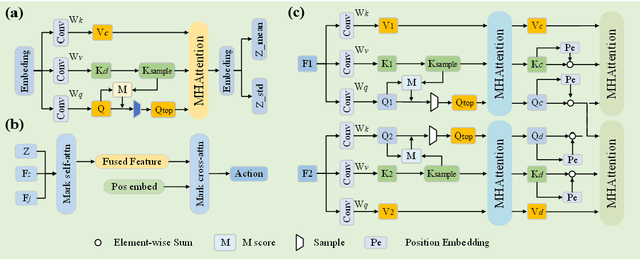
Dual-arm robots have great application prospects in intelligent manufacturing due to their human-like structure when deployed with advanced intelligence algorithm. However, the previous visuomotor policy suffers from perception deficiencies in environments where features of images are impaired by the various conditions, such as abnormal lighting, occlusion and shadow etc. The Focal CVAE framework is proposed for RGB-D multi-modal data fusion to address this challenge. In this study, a mixed focal attention module is designed for the fusion of RGB images containing color features and depth images containing 3D shape and structure information. This module highlights the prominent local features and focuses on the relevance of RGB and depth via cross-attention. A saliency attention module is proposed to improve its computational efficiency, which is applied in the encoder and the decoder of the framework. We illustrate the effectiveness of the proposed method via extensive simulation and experiments. It's shown that the performances of bi-manipulation are all significantly improved in the four real-world tasks with lower computational cost. Besides, the robustness is validated through experiments under different scenarios where there is a perception deficiency problem, demonstrating the feasibility of the method.