 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Learning with Human Feedback
Paper and Code
Aug 14, 2024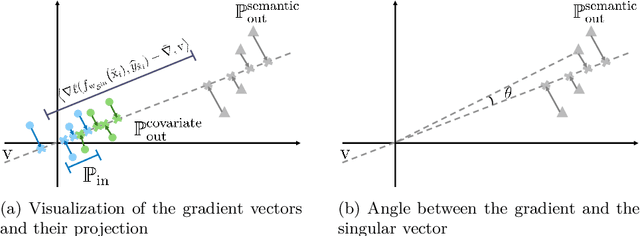
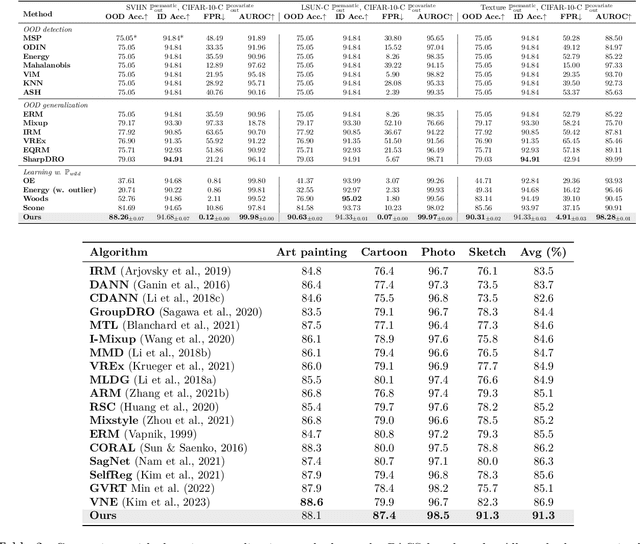
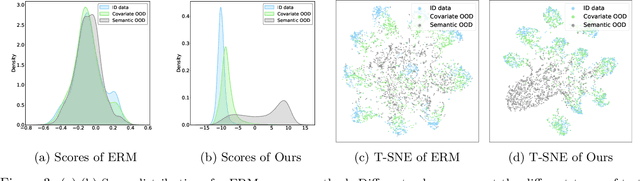

Out-of-distribution (OOD) learning often relies heavily on statistical approaches or predefined assumptions about OOD data distributions, hindering their efficacy in addressing multifaceted challenges of OOD generalization and OOD detection in real-world deployment environments. This paper presents a novel framework for OOD learning with human feedback, which can provide invaluable insights into the nature of OOD shifts and guide effective model adaptation. Our framework capitalizes on the freely available unlabeled data in the wild that captures the environmental test-time OOD distributions under both covariate and semantic shifts. To harness such data, our key idea is to selectively provide human feedback and label a small number of informative samples from the wild data distribution, which are then used to train a multi-class classifier and an OOD detector. By exploiting human feedback, we enhance the robustness and reliability of machine learning models, equipping them with the capability to handle OOD scenarios with greater precision. We provide theoretical insights on the generalization error bounds to justify our algorithm. Extensive experiments show the superiority of our method, outperforming the current state-of-the-art by a significant margin.