 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOriented Object Detection with Transformer
Jun 06, 2021
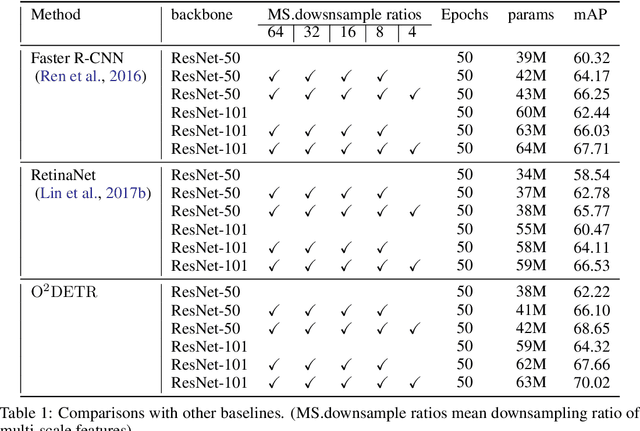
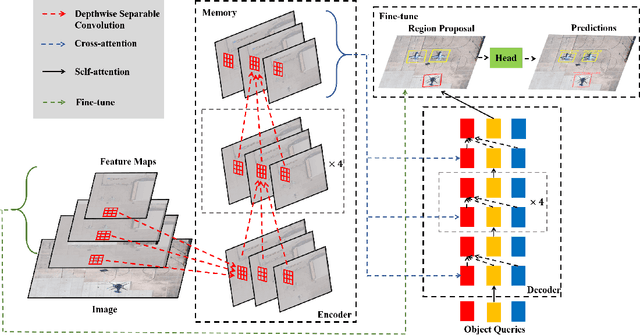
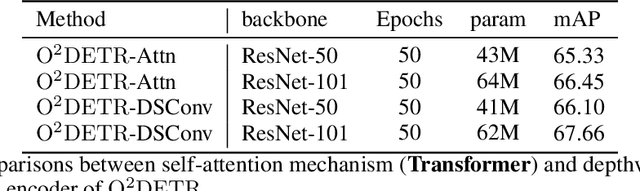
Object detection with Transformers (DETR) has achieved a competitive performance over traditional detectors, such as Faster R-CNN. However, the potential of DETR remains largely unexplored for the more challenging task of arbitrary-oriented object detection problem. We provide the first attempt and implement Oriented Object DEtection with TRansformer ($\bf O^2DETR$) based on an end-to-end network. The contributions of $\rm O^2DETR$ include: 1) we provide a new insight into oriented object detection, by applying Transformer to directly and efficiently localize objects without a tedious process of rotated anchors as in conventional detectors; 2) we design a simple but highly efficient encoder for Transformer by replacing the attention mechanism with depthwise separable convolution, which can significantly reduce the memory and computational cost of using multi-scale features in the original Transformer; 3) our $\rm O^2DETR$ can be another new benchmark in the field of oriented object detection, which achieves up to 3.85 mAP improvement over Faster R-CNN and RetinaNet. We simply fine-tune the head mounted on $\rm O^2DETR$ in a cascaded architecture and achieve a competitive performance over SOTA in the DOTA dataset.
Dual-stream Network for Visual Recognition
May 31, 2021
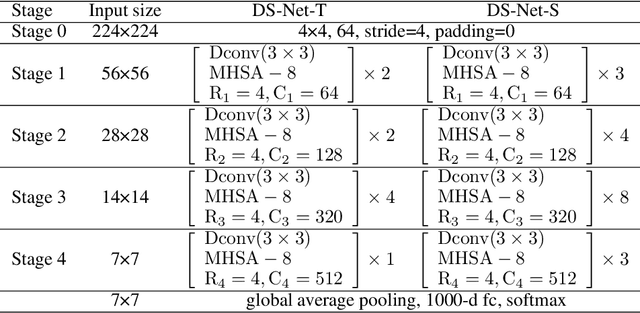
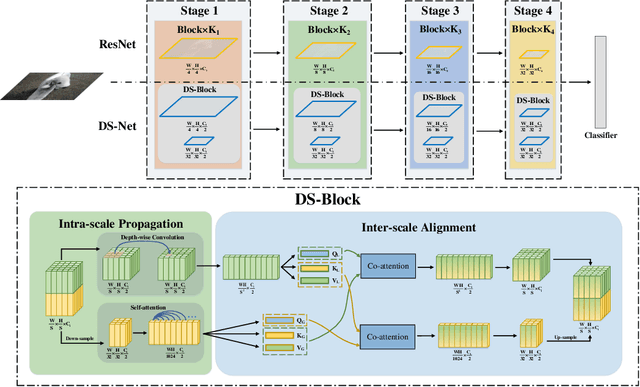
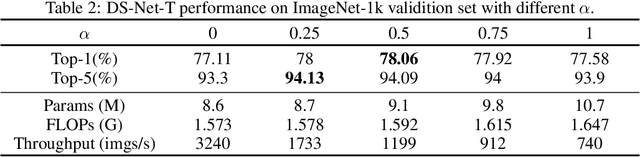
Transformers with remarkable global representation capacities achieve competitive results for visual tasks, but fail to consider high-level local pattern information in input images. In this paper, we present a generic Dual-stream Network (DS-Net) to fully explore the representation capacity of local and global pattern features for image classification. Our DS-Net can simultaneously calculate fine-grained and integrated features and efficiently fuse them. Specifically, we propose an Intra-scale Propagation module to process two different resolutions in each block and an Inter-Scale Alignment module to perform information interaction across features at dual scales. Besides, we also design a Dual-stream FPN (DS-FPN) to further enhance contextual information for downstream dense predictions. Without bells and whistles, the propsed DS-Net outperforms Deit-Small by 2.4% in terms of top-1 accuracy on ImageNet-1k and achieves state-of-the-art performance over other Vision Transformers and ResNets. For object detection and instance segmentation, DS-Net-Small respectively outperforms ResNet-50 by 6.4% and 5.5 % in terms of mAP on MSCOCO 2017, and surpasses the previous state-of-the-art scheme, which significantly demonstrates its potential to be a general backbone in vision tasks. The code will be released soon.
Probabilistic Ranking-Aware Ensembles for Enhanced Object Detections
May 07, 2021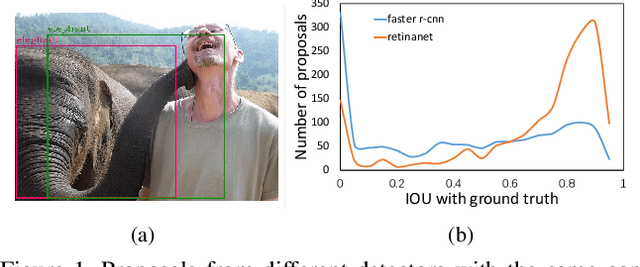

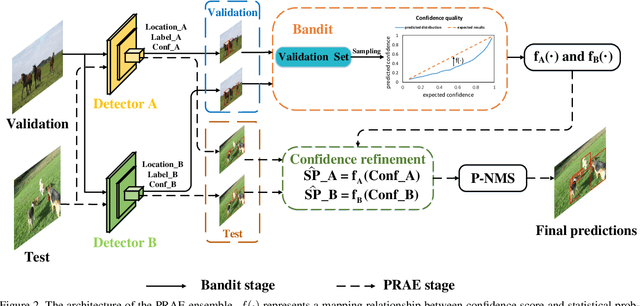

Model ensembles are becoming one of the most effective approaches for improving object detection performance already optimized for a single detector. Conventional methods directly fuse bounding boxes but typically fail to consider proposal qualities when combining detectors. This leads to a new problem of confidence discrepancy for the detector ensembles. The confidence has little effect on single detectors but significantly affects detector ensembles. To address this issue, we propose a novel ensemble called the Probabilistic Ranking Aware Ensemble (PRAE) that refines the confidence of bounding boxes from detectors. By simultaneously considering the category and the location on the same validation set, we obtain a more reliable confidence based on statistical probability. We can then rank the detected bounding boxes for assembly. We also introduce a bandit approach to address the confidence imbalance problem caused by the need to deal with different numbers of boxes at different confidence levels. We use our PRAE-based non-maximum suppression (P-NMS) to replace the conventional NMS method in ensemble learning. Experiments on the PASCAL VOC and COCO2017 datasets demonstrate that our PRAE method consistently outperforms state-of-the-art methods by significant margins.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021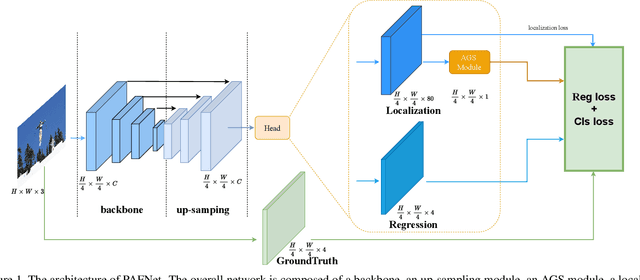
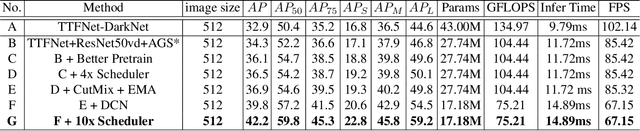
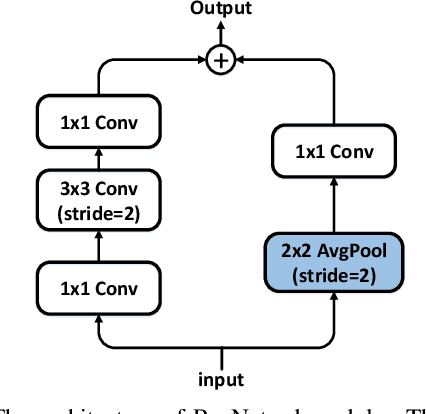

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020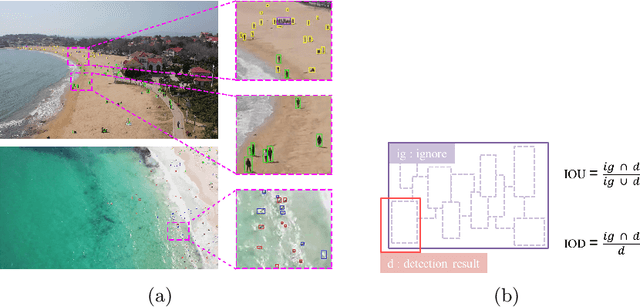
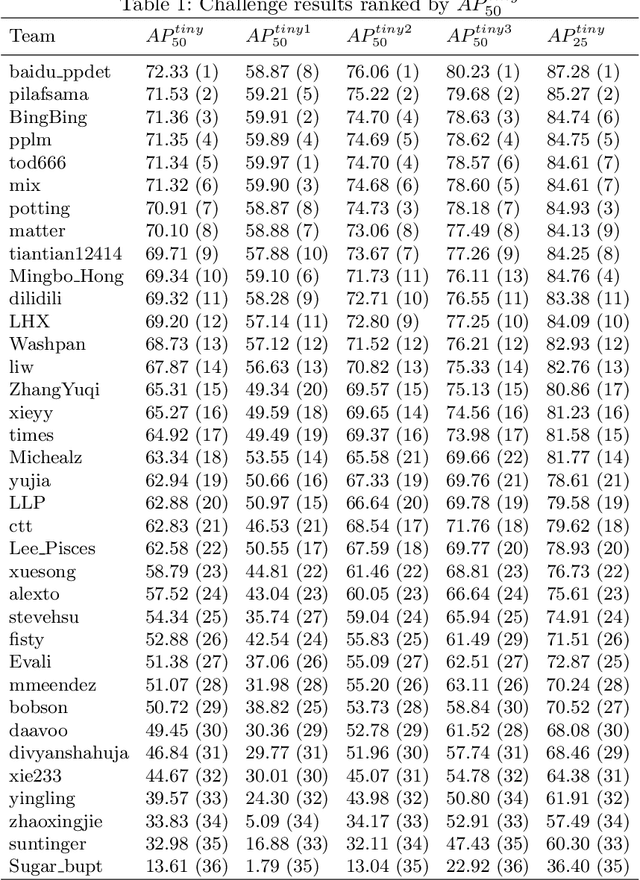
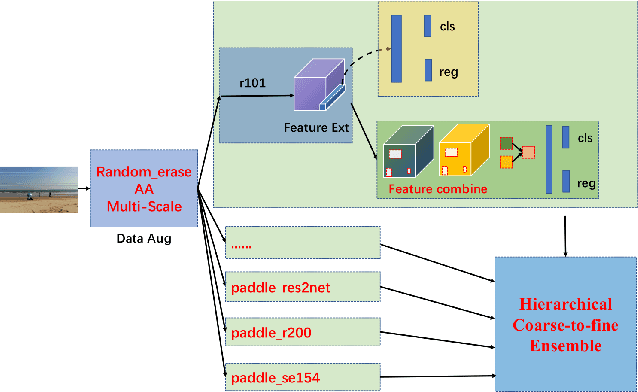

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.
iffDetector: Inference-aware Feature Filtering for Object Detection
Jun 23, 2020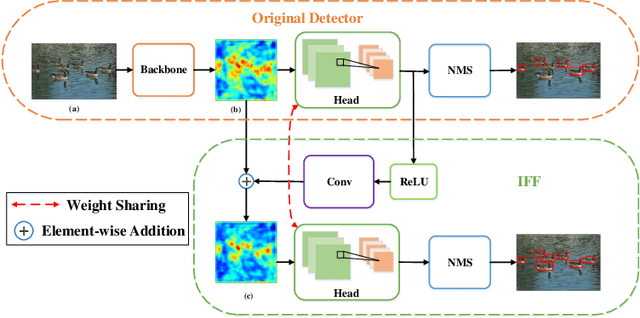

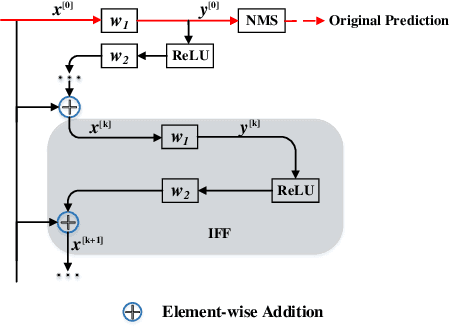
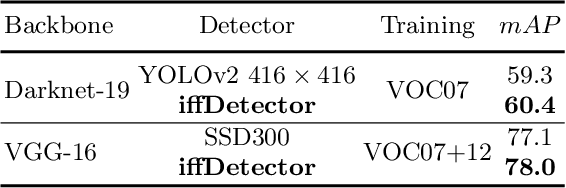
Modern CNN-based object detectors focus on feature configuration during training but often ignore feature optimization during inference. In this paper, we propose a new feature optimization approach to enhance features and suppress background noise in both the training and inference stages. We introduce a generic Inference-aware Feature Filtering (IFF) module that can easily be combined with modern detectors, resulting in our iffDetector. Unlike conventional open-loop feature calculation approaches without feedback, the IFF module performs closed-loop optimization by leveraging high-level semantics to enhance the convolutional features. By applying Fourier transform analysis, we demonstrate that the IFF module acts as a negative feedback that theoretically guarantees the stability of feature learning. IFF can be fused with CNN-based object detectors in a plug-and-play manner with negligible computational cost overhead. Experiments on the PASCAL VOC and MS COCO datasets demonstrate that our iffDetector consistently outperforms state-of-the-art methods by significant margins\footnote{The test code and model are anonymously available in https://github.com/anonymous2020new/iffDetector }.