 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElk: Exploring the Efficiency of Inter-core Connected AI Chips with Deep Learning Compiler Techniques
Jul 15, 2025To meet the increasing demand of deep learning (DL) models, AI chips are employing both off-chip memory (e.g., HBM) and high-bandwidth low-latency interconnect for direct inter-core data exchange. However, it is not easy to explore the efficiency of these inter-core connected AI (ICCA) chips, due to a fundamental tussle among compute (per-core execution), communication (inter-core data exchange), and I/O (off-chip data access). In this paper, we develop Elk, a DL compiler framework to maximize the efficiency of ICCA chips by jointly trading off all the three performance factors discussed above. Elk structures these performance factors into configurable parameters and forms a global trade-off space in the DL compiler. To systematically explore this space and maximize overall efficiency, Elk employs a new inductive operator scheduling policy and a cost-aware on-chip memory allocation algorithm. It generates globally optimized execution plans that best overlap off-chip data loading and on-chip execution. To examine the efficiency of Elk, we build a full-fledged emulator based on a real ICCA chip IPU-POD4, and an ICCA chip simulator for sensitivity analysis with different interconnect network topologies. Elk achieves 94% of the ideal roofline performance of ICCA chips on average, showing the benefits of supporting large DL models on ICCA chips. We also show Elk's capability of enabling architecture design space exploration for new ICCA chip development.
* This paper is accepted at the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO'25)
Beyond One-Size-Fits-All: Inversion Learning for Highly Effective NLG Evaluation Prompts
Apr 29, 2025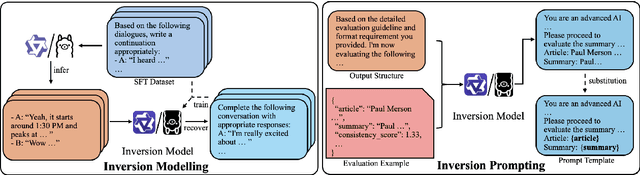
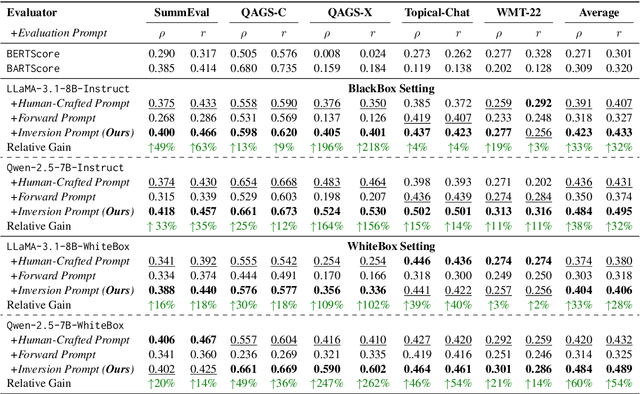

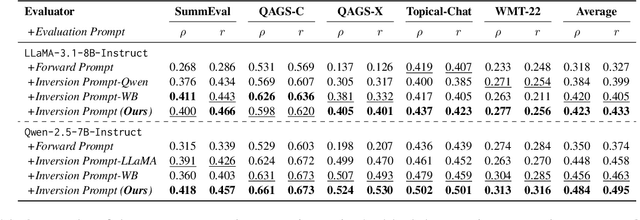
Evaluating natural language generation (NLG) systems is challenging due to the diversity of valid outputs. While human evaluation is the gold standard, it suffers from inconsistencies, lack of standardisation, and demographic biases, limiting reproducibility. LLM-based evaluation offers a scalable alternative but is highly sensitive to prompt design, where small variations can lead to significant discrepancies. In this work, we propose an inversion learning method that learns effective reverse mappings from model outputs back to their input instructions, enabling the automatic generation of highly effective, model-specific evaluation prompts. Our method requires only a single evaluation sample and eliminates the need for time-consuming manual prompt engineering, thereby improving both efficiency and robustness. Our work contributes toward a new direction for more robust and efficient LLM-based evaluation.
ContrastScore: Towards Higher Quality, Less Biased, More Efficient Evaluation Metrics with Contrastive Evaluation
Apr 02, 2025Evaluating the quality of generated text automatically remains a significant challenge. Conventional reference-based metrics have been shown to exhibit relatively weak correlation with human evaluations. Recent research advocates the use of large language models (LLMs) as source-based metrics for natural language generation (NLG) assessment. While promising, LLM-based metrics, particularly those using smaller models, still fall short in aligning with human judgments. In this work, we introduce ContrastScore, a contrastive evaluation metric designed to enable higher-quality, less biased, and more efficient assessment of generated text. We evaluate ContrastScore on two NLG tasks: machine translation and summarization. Experimental results show that ContrastScore consistently achieves stronger correlation with human judgments than both single-model and ensemble-based baselines. Notably, ContrastScore based on Qwen 3B and 0.5B even outperforms Qwen 7B, despite having only half as many parameters, demonstrating its efficiency. Furthermore, it effectively mitigates common evaluation biases such as length and likelihood preferences, resulting in more robust automatic evaluation.
Scaling Deep Learning Computation over the Inter-Core Connected Intelligence Processor
Aug 09, 2024As AI chips incorporate numerous parallelized cores to scale deep learning (DL) computing, inter-core communication is enabled recently by employing high-bandwidth and low-latency interconnect links on the chip (e.g., Graphcore IPU). It allows each core to directly access the fast scratchpad memory in other cores, which enables new parallel computing paradigms. However, without proper support for the scalable inter-core connections in current DL compilers, it is hard for developers to exploit the benefits of this new architecture. We present T10, the first DL compiler to exploit the inter-core communication bandwidth and distributed on-chip memory on AI chips. To formulate the computation and communication patterns of tensor operators in this new architecture, T10 introduces a distributed tensor abstraction rTensor. T10 maps a DNN model to execution plans with a generalized compute-shift pattern, by partitioning DNN computation into sub-operators and mapping them to cores, so that the cores can exchange data following predictable patterns. T10 makes globally optimized trade-offs between on-chip memory consumption and inter-core communication overhead, selects the best execution plan from a vast optimization space, and alleviates unnecessary inter-core communications. Our evaluation with a real inter-core connected AI chip, the Graphcore IPU, shows up to 3.3$\times$ performance improvement, and scalability support for larger models, compared to state-of-the-art DL compilers and vendor libraries.
Hardware-Assisted Virtualization of Neural Processing Units for Cloud Platforms
Aug 07, 2024Cloud platforms today have been deploying hardware accelerators like neural processing units (NPUs) for powering machine learning (ML) inference services. To maximize the resource utilization while ensuring reasonable quality of service, a natural approach is to virtualize NPUs for efficient resource sharing for multi-tenant ML services. However, virtualizing NPUs for modern cloud platforms is not easy. This is not only due to the lack of system abstraction support for NPU hardware, but also due to the lack of architectural and ISA support for enabling fine-grained dynamic operator scheduling for virtualized NPUs. We present TCloud, a holistic NPU virtualization framework. We investigate virtualization techniques for NPUs across the entire software and hardware stack. TCloud consists of (1) a flexible NPU abstraction called vNPU, which enables fine-grained virtualization of the heterogeneous compute units in a physical NPU (pNPU); (2) a vNPU resource allocator that enables pay-as-you-go computing model and flexible vNPU-to-pNPU mappings for improved resource utilization and cost-effectiveness; (3) an ISA extension of modern NPU architecture for facilitating fine-grained tensor operator scheduling for multiple vNPUs. We implement TCloud based on a production-level NPU simulator. Our experiments show that TCloud improves the throughput of ML inference services by up to 1.4$\times$ and reduces the tail latency by up to 4.6$\times$, while improving the NPU utilization by 1.2$\times$ on average, compared to state-of-the-art NPU sharing approaches.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024
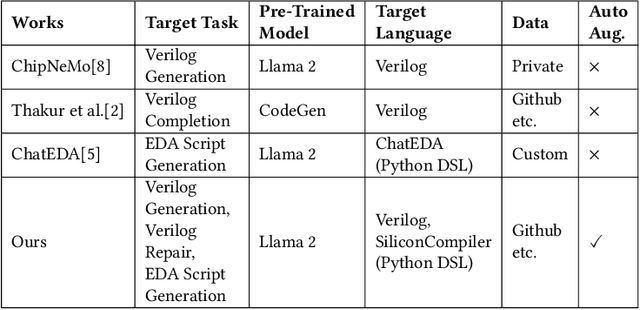


Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.
Inference for an Algorithmic Fairness-Accuracy Frontier
Feb 14, 2024Decision-making processes increasingly rely on the use of algorithms. Yet, algorithms' predictive ability frequently exhibit systematic variation across subgroups of the population. While both fairness and accuracy are desirable properties of an algorithm, they often come at the cost of one another. What should a fairness-minded policymaker do then, when confronted with finite data? In this paper, we provide a consistent estimator for a theoretical fairness-accuracy frontier put forward by Liang, Lu and Mu (2023) and propose inference methods to test hypotheses that have received much attention in the fairness literature, such as (i) whether fully excluding a covariate from use in training the algorithm is optimal and (ii) whether there are less discriminatory alternatives to an existing algorithm. We also provide an estimator for the distance between a given algorithm and the fairest point on the frontier, and characterize its asymptotic distribution. We leverage the fact that the fairness-accuracy frontier is part of the boundary of a convex set that can be fully represented by its support function. We show that the estimated support function converges to a tight Gaussian process as the sample size increases, and then express policy-relevant hypotheses as restrictions on the support function to construct valid test statistics.
LLMs as Narcissistic Evaluators: When Ego Inflates Evaluation Scores
Nov 16, 2023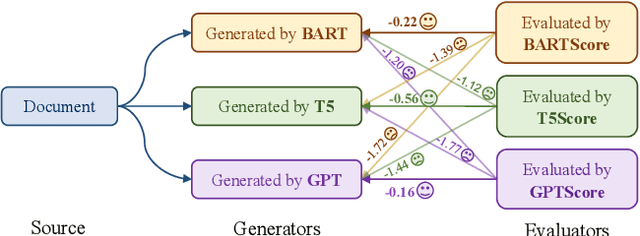
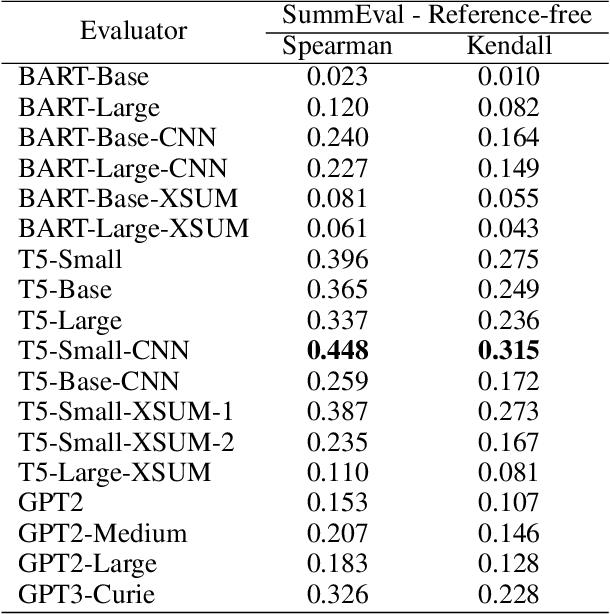
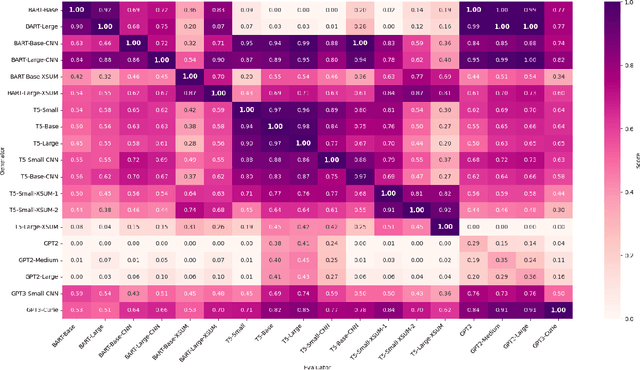
Automatic evaluation of generated textual content presents an ongoing challenge within the field of NLP. Given the impressive capabilities of modern language models (LMs) across diverse NLP tasks, there is a growing trend to employ these models in creating innovative evaluation metrics for automated assessment of generation tasks. This paper investigates a pivotal question: Do language model-driven evaluation metrics inherently exhibit bias favoring texts generated by the same underlying language model? Specifically, we assess whether prominent LM-based evaluation metrics--namely, BARTScore, T5Score, and GPTScore--demonstrate a favorable bias toward their respective underlying LMs in the context of summarization tasks. Our findings unveil a latent bias, particularly pronounced when such evaluation metrics are used in an reference-free manner without leveraging gold summaries. These results underscore that assessments provided by generative evaluation models can be influenced by factors beyond the inherent text quality, highlighting the necessity of developing more dependable evaluation protocols in the future.
G10: Enabling An Efficient Unified GPU Memory and Storage Architecture with Smart Tensor Migrations
Oct 13, 2023To break the GPU memory wall for scaling deep learning workloads, a variety of architecture and system techniques have been proposed recently. Their typical approaches include memory extension with flash memory and direct storage access. However, these techniques still suffer from suboptimal performance and introduce complexity to the GPU memory management, making them hard to meet the scalability requirement of deep learning workloads today. In this paper, we present a unified GPU memory and storage architecture named G10 driven by the fact that the tensor behaviors of deep learning workloads are highly predictable. G10 integrates the host memory, GPU memory, and flash memory into a unified memory space, to scale the GPU memory capacity while enabling transparent data migrations. Based on this unified GPU memory and storage architecture, G10 utilizes compiler techniques to characterize the tensor behaviors in deep learning workloads. Therefore, it can schedule data migrations in advance by considering the available bandwidth of flash memory and host memory. The cooperative mechanism between deep learning compilers and the unified memory architecture enables G10 to hide data transfer overheads in a transparent manner. We implement G10 based on an open-source GPU simulator. Our experiments demonstrate that G10 outperforms state-of-the-art GPU memory solutions by up to 1.75$\times$, without code modifications to deep learning workloads. With the smart data migration mechanism, G10 can reach 90.3\% of the performance of the ideal case assuming unlimited GPU memory.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jul 12, 2023In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.