 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024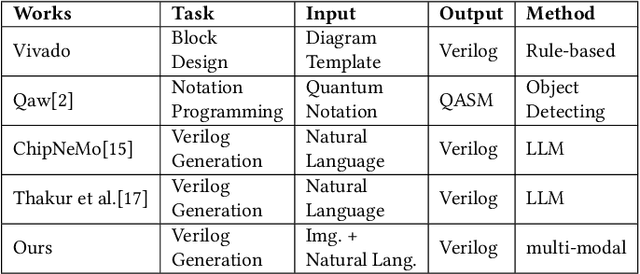
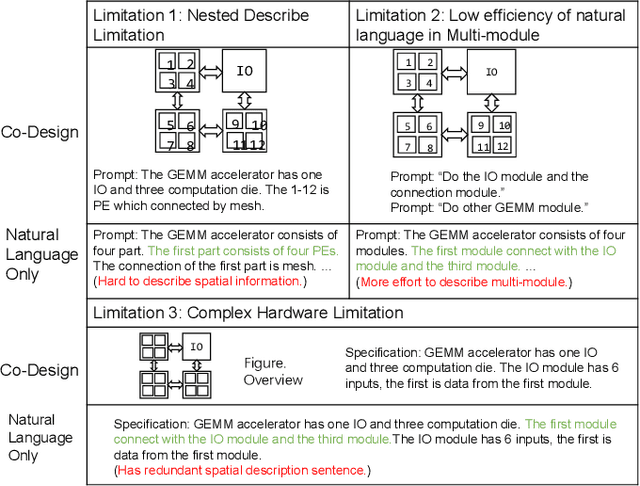
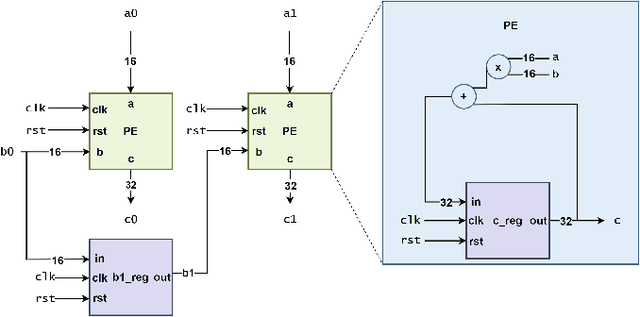
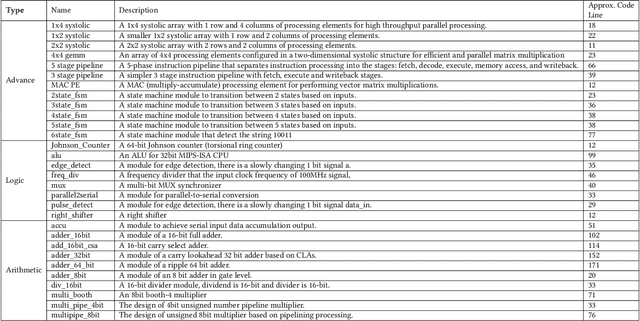
Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.
Data is all you need: Finetuning LLMs for Chip Design via an Automated design-data augmentation framework
Mar 17, 2024
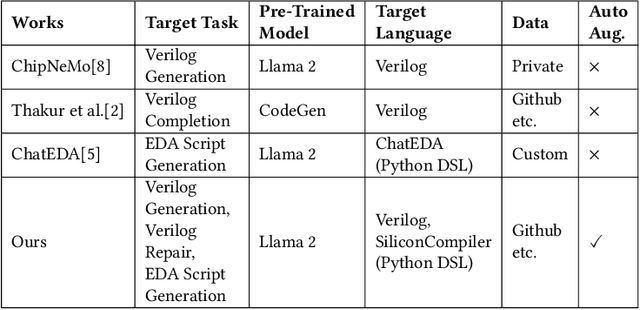


Recent advances in large language models have demonstrated their potential for automated generation of hardware description language (HDL) code from high-level prompts. Researchers have utilized fine-tuning to enhance the ability of these large language models (LLMs) in the field of Chip Design. However, the lack of Verilog data hinders further improvement in the quality of Verilog generation by LLMs. Additionally, the absence of a Verilog and Electronic Design Automation (EDA) script data augmentation framework significantly increases the time required to prepare the training dataset for LLM trainers. This paper proposes an automated design-data augmentation framework, which generates high-volume and high-quality natural language aligned with Verilog and EDA scripts. For Verilog generation, it translates Verilog files to an abstract syntax tree and then maps nodes to natural language with a predefined template. For Verilog repair, it uses predefined rules to generate the wrong verilog file and then pairs EDA Tool feedback with the right and wrong verilog file. For EDA Script generation, it uses existing LLM(GPT-3.5) to obtain the description of the Script. To evaluate the effectiveness of our data augmentation method, we finetune Llama2-13B and Llama2-7B models using the dataset generated by our augmentation framework. The results demonstrate a significant improvement in the Verilog generation tasks with LLMs. Moreover, the accuracy of Verilog generation surpasses that of the current state-of-the-art open-source Verilog generation model, increasing from 58.8% to 70.6% with the same benchmark. Our 13B model (ChipGPT-FT) has a pass rate improvement compared with GPT-3.5 in Verilog generation and outperforms in EDA script (i.e., SiliconCompiler) generation with only 200 EDA script data.